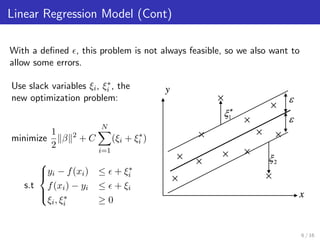
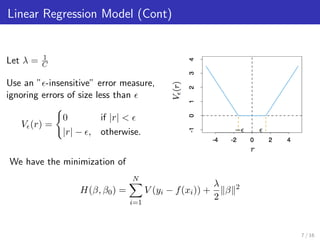
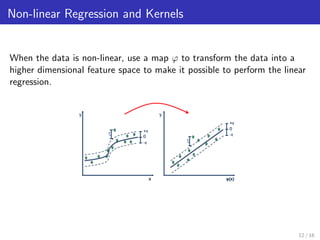
Support Vector Machines can be used for regression by finding the tube that best fits the data while minimizing complexity. This is done by minimizing errors outside an epsilon-insensitive tube while allowing errors within epsilon. Non-linear regression is handled by mapping data into a higher dimensional feature space and using kernels to calculate inner products without explicitly performing the mapping. Kernels allow support vector regression to find a linear function in this feature space, resulting in a non-linear function in the original space.












![Non-linear Regression and Kernels (Cont)
We have estimate function:
f(x) = h(x)T ˆβ
= h(x)T
HT
(HHT
)−1
Hˆβ
= h(x)T
HT
(HHT
)−1
(HHT
+ λI)−1
HHT
y
= h(x)T
HT
[(HHT
+ λI)(HHT
)]−1
HHT
y
= h(x)T
HT
[(HHT
)(HHT
) + λ(HHT
)I]−1
HHT
y
= h(x)T
HT
[(HHT
)(HHT
+ λI)]−1
HHT
y
= h(x)T
HT
(HHT
+ λI)−1
(HHT
)−1
HHT
y
= h(x)T
HT
(HHT
+ λI)−1
y
= [K(x, x1)K(x, x2)...K(x, xN )]ˆα
=
N
i=1
ˆαiK(x, xi)
where ˆα = (HHT
+ λI)−1y. 15 / 16](https://image.slidesharecdn.com/svmforregression-150715033408-lva1-app6891/85/SVM-for-Regression-15-320.jpg)




































































