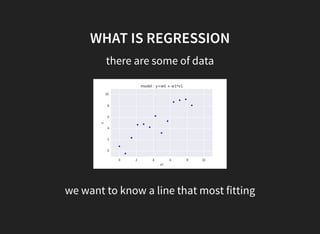
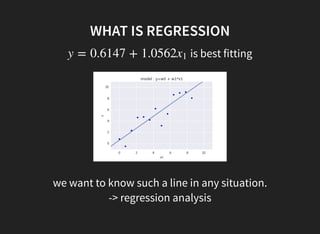
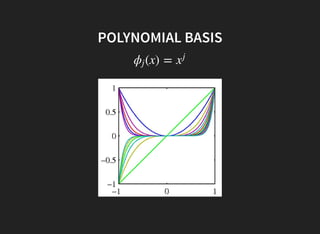
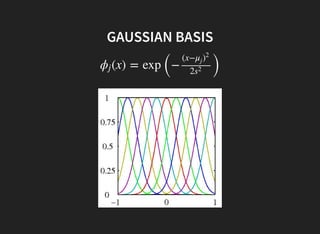
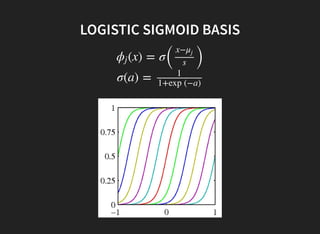
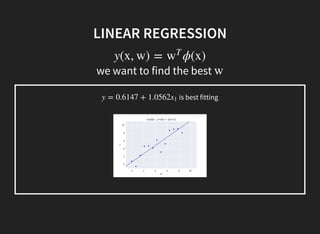
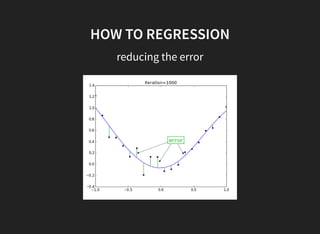
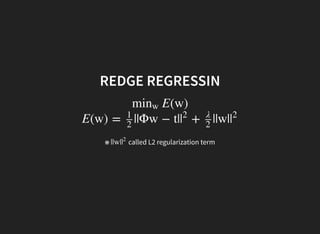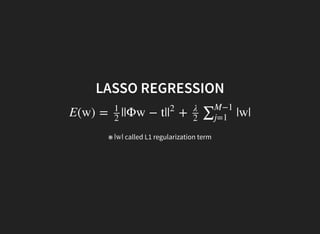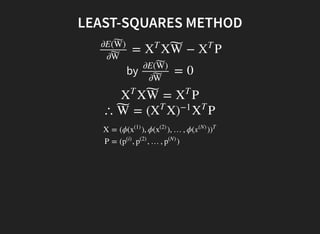I introduced some key concepts in linear regression models:
1. Linear regression aims to fit a linear function to data to minimize error.
2. Maximum likelihood estimation is equivalent to least squares regression.
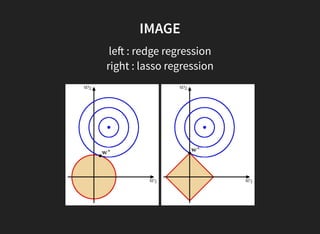
3. MAP estimation with a Gaussian prior is equivalent to ridge regression.
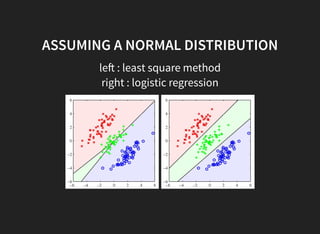
4. Linear classification models predict class probabilities using multiple linear functions.
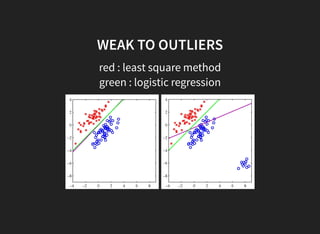
5. The least squares method for classification has disadvantages like being sensitive to outliers.