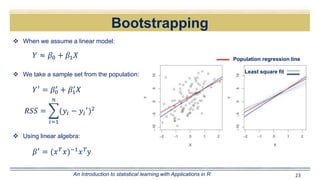
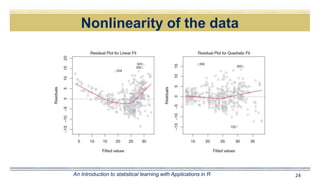
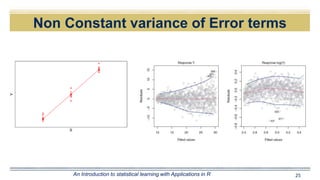
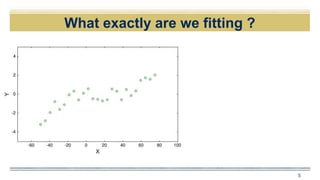
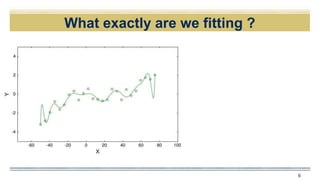
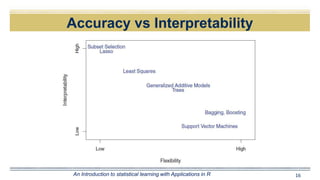
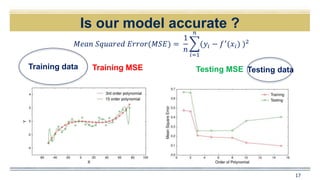
The document discusses curve fitting and modeling. It begins with a quote about fitting an elephant with four parameters. It then discusses searching for the "holy elephant" by fitting data to different models. The rest of the document discusses various aspects of curve fitting such as determining the fitting function, testing accuracy, improving the model, and dealing with issues like nonlinearity and non-constant variance. It emphasizes using techniques like learning curves and bootstrapping to evaluate fit and avoid overfitting. The overall message is that model fitting requires supporting it with residual analysis and having the right balance of model flexibility and data.





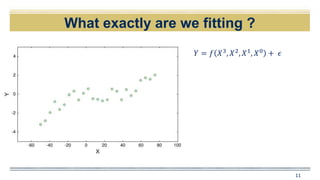
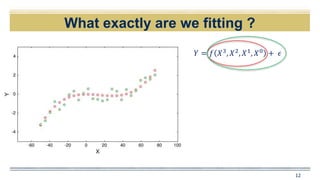
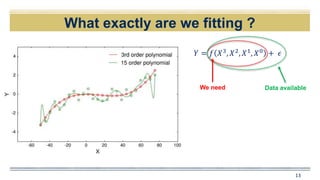
![Why Estimate f ?
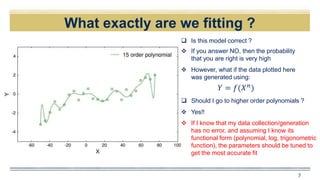
14
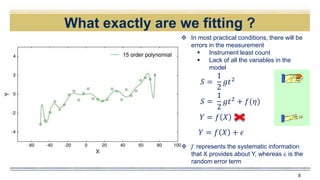
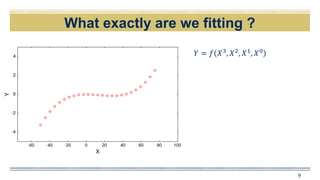
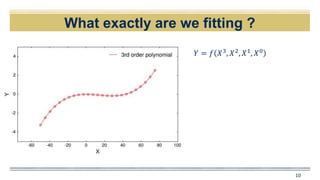
𝑌 = 𝑓 𝑋3
, 𝑋2
, 𝑋1
, 𝑋0
+ 𝜖
Data availableWe need
Prediction
𝑌′ = 𝑓′ 𝑋
Inference
How does Y depend on X ?
We do need to estimate f but the is
not necessarily to make predictions
on Y
𝐸(𝑌 − 𝑌′)2= 𝐸[𝑓 𝑋 + 𝜖 − 𝑓′(𝑋)]2
= [𝑓 𝑋 − 𝑓′(𝑋)]2+𝑉𝑎𝑟(𝜖)
Reducible Irreducible](https://image.slidesharecdn.com/e2802f2f-9f71-45ef-aa46-b681e883fb85-161210164243/85/151028_abajpai1-14-320.jpg)

![Bias-Variance trade off
18
One basic inference from a U–shaped/Convex dependency ?
𝐸((𝑦0) − 𝑓′(𝑋0))2= 𝑉𝑎𝑟 𝑓′ 𝑋0 + [𝐵𝑖𝑎𝑠(𝑓′ 𝑋0 )]2+𝑉𝑎𝑟(𝜖)
Expected Test MSE
Flexible methods
High Variance
Low bias
Rigid methods
High bias
Low variance](https://image.slidesharecdn.com/e2802f2f-9f71-45ef-aa46-b681e883fb85-161210164243/85/151028_abajpai1-18-320.jpg)

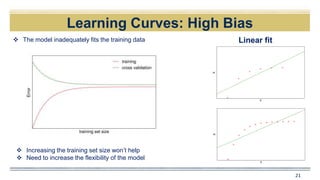
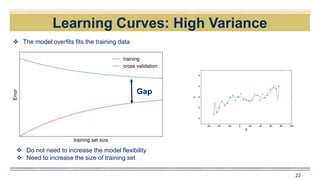
![Learning Curves
20
Quadratic fit
𝐸((𝑦0) − 𝑓′
(𝑋0))2
= 𝑉𝑎𝑟 𝑓′
𝑋0 + [𝐵𝑖𝑎𝑠(𝑓′
𝑋0 )]2
+𝑉𝑎𝑟(𝜖)
Expected Test MSE High biasHigh var](https://image.slidesharecdn.com/e2802f2f-9f71-45ef-aa46-b681e883fb85-161210164243/85/151028_abajpai1-20-320.jpg)