Downloaded 1,201 times











![Word Analogy Task
man is to woman as king is to ?
good is to best as smart is to ?
china is to beijing as russia is to ?
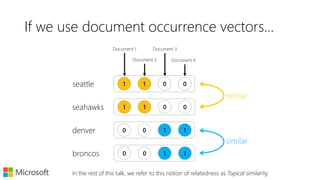
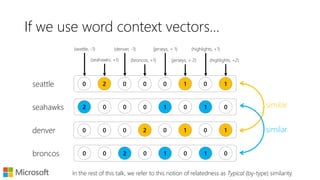
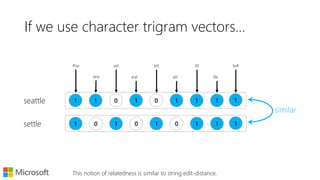
Turns out the word-context based vector model we just learnt is
good for such analogy tasks,
[king] – [man] + [woman] ≈ [queen]
Levy, Goldberg, and Israel, Linguistic Regularities in Sparse and Explicit Word Representations, CoNLL. 2014.](https://image.slidesharecdn.com/introductiontowordembeddings-160405062343/85/A-Simple-Introduction-to-Word-Embeddings-14-320.jpg)
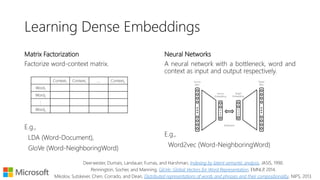
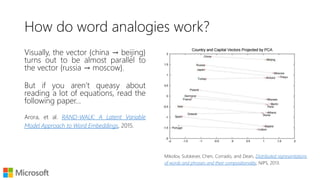


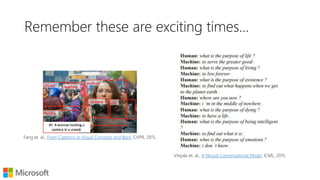





The document discusses vector space models and their application in representing words as numerical vectors, which can depict relationships based on document occurrences, neighboring word context, and character trigrams. It highlights various methods for computing word similarity, including pointwise mutual information and cosine similarity, and introduces dense word embeddings as a more efficient alternative for high-dimensional sparse vectors. Furthermore, it touches on potential practical applications, such as document ranking and analogy tasks, while also encouraging experimentation with pre-trained word embeddings like Word2Vec and GloVe.











































































































