![INTRODUCTION WORD2VEC WORD MOVERS DISTANCE Q&A
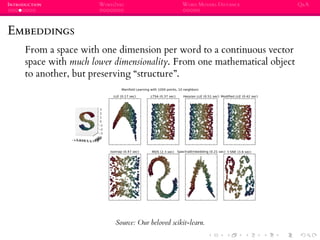
WORD EMBEDDINGS
Word Model
Word
Embedding
V(cat) = [ 1.4, -1.3, ... ]
Cat
sat
mat
on
cat = [ 0, 1, 0, ... ]
Sparse
Dense
From a sparse representation (usually one-hot encoding) to a
dense representation
Embeddings created as by-product vs explicit model](https://image.slidesharecdn.com/embeddings-170201143747/85/Word-Embeddings-Introduction-11-320.jpg)
![INTRODUCTION WORD2VEC WORD MOVERS DISTANCE Q&A
LANGUAGE MODELING
P(w1, · · · , wn) =
i
P(wi | w1, · · · , wi−1)
P(”the cat sat on the mat“) > P(”the mat sat on the cat“)
Useful for many different tasks, such as speech recognition,
handwriting recognition, translation, etc.
Naive counting: doesn’t generalize, too many possible
sentences
A word sequence on which the model will be tested is likely to
be different from all the word sequences seen during training.
[Bengio et al, 2003]
Markov assumption / how to approximate it](https://image.slidesharecdn.com/embeddings-170201143747/85/Word-Embeddings-Introduction-12-320.jpg)





















![INTRODUCTION WORD2VEC WORD MOVERS DISTANCE Q&A
WORD MOVERS DISTANCE
From Word Embeddings To Document Distances
1 2 3 4 5 6 7 8
0
10
20
30
40
50
60
70
twitter recipe ohsumed classic reuters amazon
testerror%
43
33
44
33 32 32
29
66
63 61
49 51
44
36
8.0 9.7
62
44 41
35
6.9
5.0
6.7
2.8
33
29
14
8.16.96.3
3.5
59
42
28
14
17
12
9.3
7.4
34
17
22
21
8.4
6.4
4.3
21
4.6
53 53
59
54
48
45
43
51
56 54
58
36
40
31
29
27
20newsbbcsport
k-nearest neighbor error
BOW [Frakes & Baeza-Yates, 1992]
TF-IDF [Jones, 1972]
Okapi BM25 [Robertson & Walker, 1994]
LSI [Deerwester et al., 1990]
LDA [Blei et al., 2003]
mSDA [Chen et al., 2012]
Componential Counting Grid [Perina et al., 2013]
Word Mover's Distance
Figure 3. The kNN test error results on 8 document classification data sets, compared to canonical and state-of-the-art baselines methods.
1 2 3 4 5 6 7 8
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
averageerrorw.r.t.BOW
1.6
1.4
1.2
1.0
0.8
0.6
0.4
0.2
0
1.29
1.15
1.0
0.72
0.60 0.55
0.49 0.42
BOW
TF-IDF
Okapi BM25
LSI
LDA
mSDA
CCG
WMD
Figure 4. The kNN test errors of various document metrics aver-
aged over all eight datasets, relative to kNN with BOW.
w, TF(w, D) is its term frequency in document D, |D| is
Table 2. Test error percentage and standard deviation for different
text embeddings. NIPS, AMZ, News are word2vec (w2v) models
trained on different data sets whereas HLBL and Collo were also
obtained with other embedding algorithms.
DOCUMENT k-NEAREST NEIGHBOR RESULTS
DATASET HLBL CW NIPS AMZ NEWS
(W2V) (W2V) (W2V)
BBCSPORT 4.5 8.2 9.5 4.1 5.0
TWITTER 33.3 33.7 29.3 28.1 28.3
RECIPE 47.0 51.6 52.7 47.4 45.1
OHSUMED 52.0 56.2 55.6 50.4 44.5
CLASSIC 5.3 5.5 4.0 3.8 3.0
REUTERS 4.2 4.6 7.1 9.1 3.5
AMAZON 12.3 13.3 13.9 7.8 7.2
Source: From Word Embeddings To Document Distances. Kusner, Matt J. et al. 2015.](https://image.slidesharecdn.com/embeddings-170201143747/85/Word-Embeddings-Introduction-34-320.jpg)



The document provides an introduction to word embeddings and two related techniques: Word2Vec and Word Movers Distance. Word2Vec is an algorithm that produces word embeddings by training a neural network on a large corpus of text, with the goal of producing dense vector representations of words that encode semantic relationships. Word Movers Distance is a method for calculating the semantic distance between documents based on the embedded word vectors, allowing comparison of documents with different words but similar meanings. The document explains these techniques and provides examples of their applications and properties.