Downloaded 78 times



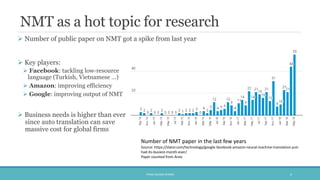

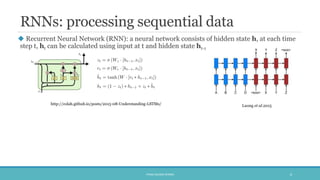
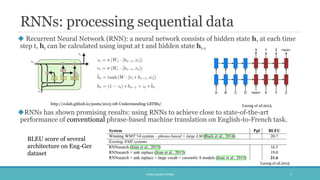
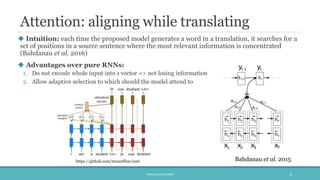


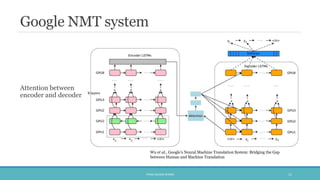
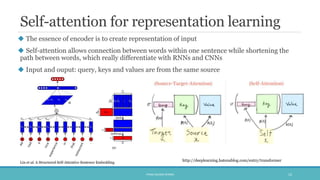

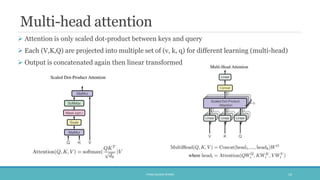

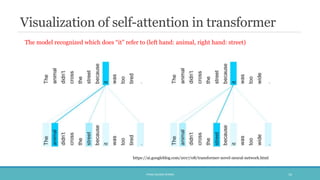


The document discusses the evolution and significance of neural machine translation (NMT), highlighting the attention mechanism as a key innovation in improving translation accuracy and efficiency. It details evaluation methods such as the BLEU score and outlines various NMT architectures, including recurrent neural networks (RNNs), attention-based models, and transformers, with a focus on enhancing the handling of long sentences and complex dependencies. Additionally, the document notes the increasing demand for effective translation solutions across various applications, including business and scientific domains.


![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)














![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)








































