Downloaded 315 times




![Some applications…4Information retrieval using vectoral model [Salton & Lesk 1971]Relevance Feedback and Text Classification [Rocchio 1971]Word sense disambiguation [Lesk 1986; Schutze 1998]Extractive Summarization [Salton et al 1997]Automatic evaluation of machine translation [Papineni et al 2002]Text Summarization [Lin & Hovy 2003]Evaluation of Text coherence [Lapata & Barzilay 2005]](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-4-320.jpg)

![Vector Space ModelSaS = Sense and Sensibility (Austen)PaP = Pride and Prejudice (Austen)WH= Wuthering Heights (Brontë)Sim(SaS,PaP) = 0.999Sim(SaS, WH) = 0.888Problems: synonymy, polysemy[source: Manning et al, IR book]6](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-6-320.jpg)
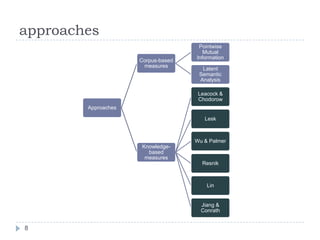
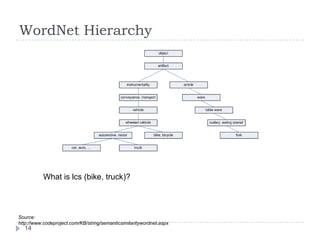
![Solution 2 (this paper)Leverage on existing word-to-word similarity measures either from corpus-based or knowledge-basedReduction of text similarity into word-to-word similairtymaxSim = highest word-to-word similarity based on one of 8 similarity measures (next slides)idf =inverse document frequency = Specificity: [collie, sheepdog] > [get, become]Only open-class words that share same POS7](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-7-320.jpg)
![Pointwise Mutual Information (PMI)UnsupervisedBased on co-occurrence in a very large corporaNEAR query: co-occurrence within a ten-word window72.5% accuracy on identifying the correct synonym out of 4 TOEFL synonym choices.Source: [Turney 2001]9](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-9-320.jpg)

![Latent Semantic Analysis[Landauer 1998]Term co-occurrence are captured by means of dimensionality reduction through “singular value decomposition” on the term document matrix TT = term-by-document matrix ∑k = diagonal k x k matrixU and V are column-orthogonal matrices.11](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-11-320.jpg)
![Example[source: Manning, IR book]12](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-12-320.jpg)
![Lesk [1986]Similarity of two concepts is defined as a function of the overlap between the corresponding definitions 13](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-13-320.jpg)
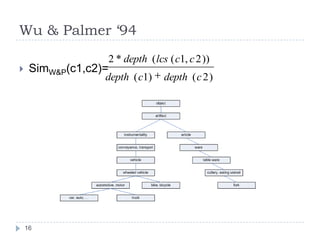
![Leacock & Chodorow [1998]Length = length of the shortest path between two concepts using node-countingD = max depth of the taxonomy15](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-15-320.jpg)

![ExperimentAutomatically identify if two text segments are paraphrases of each otherCorpus: Microsoft paraphrase corpus [Dolan et al 2004]4,076 training and 1,725 test setNews source over 18 monthsHuman labelled with 83% agreementThe system labels a pair as ‘paraphrase’ if score > 0.5Baselines:Random baselineVector-based using cosine similarity18](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-18-320.jpg)
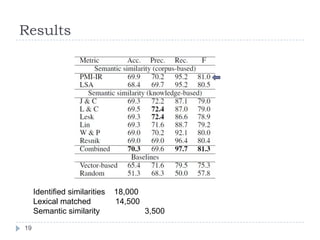
![Results [cont’d]Pearson correlation20](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-20-320.jpg)







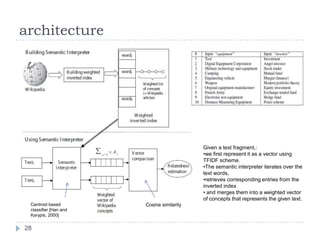


![and merges them into a weighted vector of concepts that represents the given text.Centroid based classifier [Han and Karypis, 2000]Cosine similarity](https://image.slidesharecdn.com/textsimilarity-100211062411-phpapp02/85/Text-Similarity-31-320.jpg)




The document discusses text semantic similarity, outlining various approaches including both corpus-based and knowledge-based methods. It highlights the performance of different measures in identifying paraphrases and semantic relatedness, particularly focusing on explicit semantic analysis using Wikipedia concepts. Additionally, it compares the effectiveness of these methods in understanding relationships between words and concepts in natural language processing.























































































