Downloaded 383 times






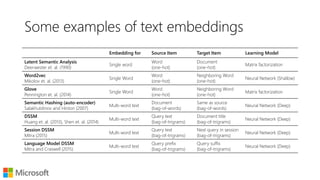
![Learning word embeddings
Start with a paired items dataset
[source, target]
Train a neural network
Bottleneck layer gives you a
dense vector representation
E.g., word2vec
Pennington, Socher, and Manning. "Glove: Global Vectors for Word Representation." EMNLP (2014).
Target
Item
Source
Item
Source
Embedding
Target
Embedding
Distance
Metric](https://image.slidesharecdn.com/textembeddingsforir-glasgow-160523190221/85/Using-Text-Embeddings-for-Information-Retrieval-6-320.jpg)
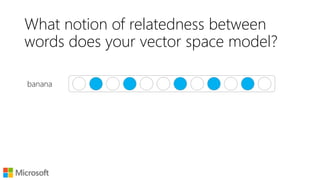
![Learning word embeddings
Start with a paired items dataset
[source, target]
Make a Source x Target matrix
Factorizing the matrix gives you
a dense vector representation
E.g., LSA, GloVe
T0 T1 T2 T3 T4 T5 T6 T7 T8
S0
S1
S2
S3
S5
S6
S7
Pennington, Socher, and Manning. "Glove: Global Vectors for Word Representation." EMNLP (2014).](https://image.slidesharecdn.com/textembeddingsforir-glasgow-160523190221/85/Using-Text-Embeddings-for-Information-Retrieval-7-320.jpg)
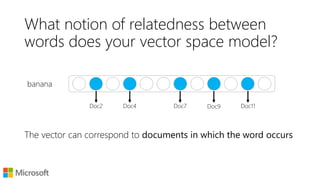
![Learning word embeddings
Start with a paired items dataset
[source, target]
Make a bi-partite graph
PPMI over edges gives you a
sparse vector representation
E.g., explicit representations
Levy et. al. “Linguistic regularities in sparse and explicit word representations”. CoNLL (2015)](https://image.slidesharecdn.com/textembeddingsforir-glasgow-160523190221/85/Using-Text-Embeddings-for-Information-Retrieval-8-320.jpg)
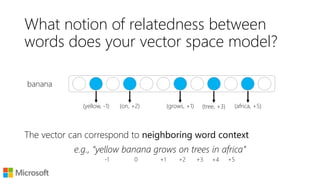
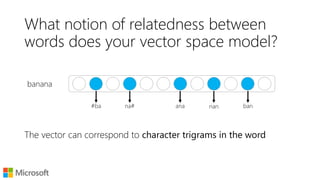


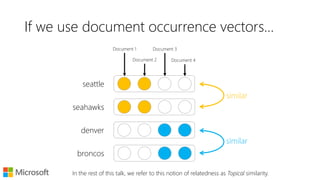
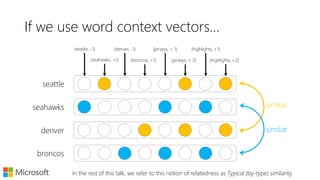
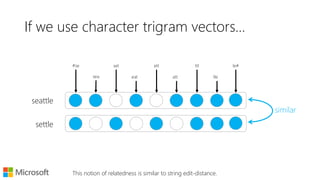

![What does word2vec do?
seattle
seattle denver
seahawks broncos
jerseys
highlights
wilson
sherman
seahawks
denver
broncos
similar
browner
lfedi
lynch
sanchez
miller
marshall
[seahawks] – [seattle] + [Denver]
Mikolov et al. "Distributed representations of words and phrases and their compositionality." NIPS (2013).
Mikolov et al. "Efficient estimation of word representations in vector space." arXiv preprint (2013).](https://image.slidesharecdn.com/textembeddingsforir-glasgow-160523190221/85/Using-Text-Embeddings-for-Information-Retrieval-20-320.jpg)



















Neural text embeddings provide dense vector representations of words and documents that encode various notions of semantic relatedness. Word2vec models typical similarity by representing words based on neighboring context words, while models like latent semantic analysis encode topical similarity through co-occurrence in documents. Dual embedding spaces can separately model both typical and topical similarities. Recent work has applied text embeddings to tasks like query auto-completion, session modeling, and document ranking, demonstrating their ability to capture semantic relationships between text beyond just words.











































































































