Download to read offline

![• Machine Learning algorithms are incapable of processing strings.
• They require numbers as inputs.
• Huge amount of text data to be converted.
• A Word Embedding format generally tries to map a word using a dictionary to a vector.
sentence= “Word Embeddings are Word converted into numbers ”
• Words: “Embeddings” or “numbers ” etc.
• Dictionary: List of all unique words in the sentence.
[‘Word’,’Embeddings’,’are’,’Converted’,’into’,’numbers’]
• A vector representation of a word may be a one-hot encoded vector where 1 stands for the position where the word
exists and 0 everywhere else.
“numbers” - [0,0,0,0,0,1]
“converted” - [0,0,0,1,0,0].
Why do we need WORD EMBEDDINGS?](https://image.slidesharecdn.com/wordembeddings-180506004653/85/Word-embeddings-2-320.jpg)



![PMI = Pointwise Mutual Information.
Matrix Factorization of Word Embeddings (co-
occurrence matrix)
Larger PMI Higher correlation
ISSUES: Many entries with PMI (w,c) = log 0
SOLUTION:
• Set PMI(w,c) = 0 for all unobserved pairs.
• Drop all entries of PMI< 0 [POSITIVE POINTWISE MUTUAL INFORMATION]
Where, w= word, c= context word
Produces 2 different vectors for each word:
• Describes word when it is the ‘target word’ in the window
• Describes word when it is the ‘context word’ in window](https://image.slidesharecdn.com/wordembeddings-180506004653/85/Word-embeddings-6-320.jpg)


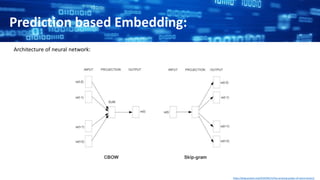







Word embeddings are a technique for converting words into vectors of numbers so that they can be processed by machine learning algorithms. Words with similar meanings are mapped to similar vectors in the vector space. There are two main types of word embedding models: count-based models that use co-occurrence statistics, and prediction-based models like CBOW and skip-gram neural networks that learn embeddings by predicting nearby words. Word embeddings allow words with similar contexts to have similar vector representations, and have applications such as document representation.



















![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)















































