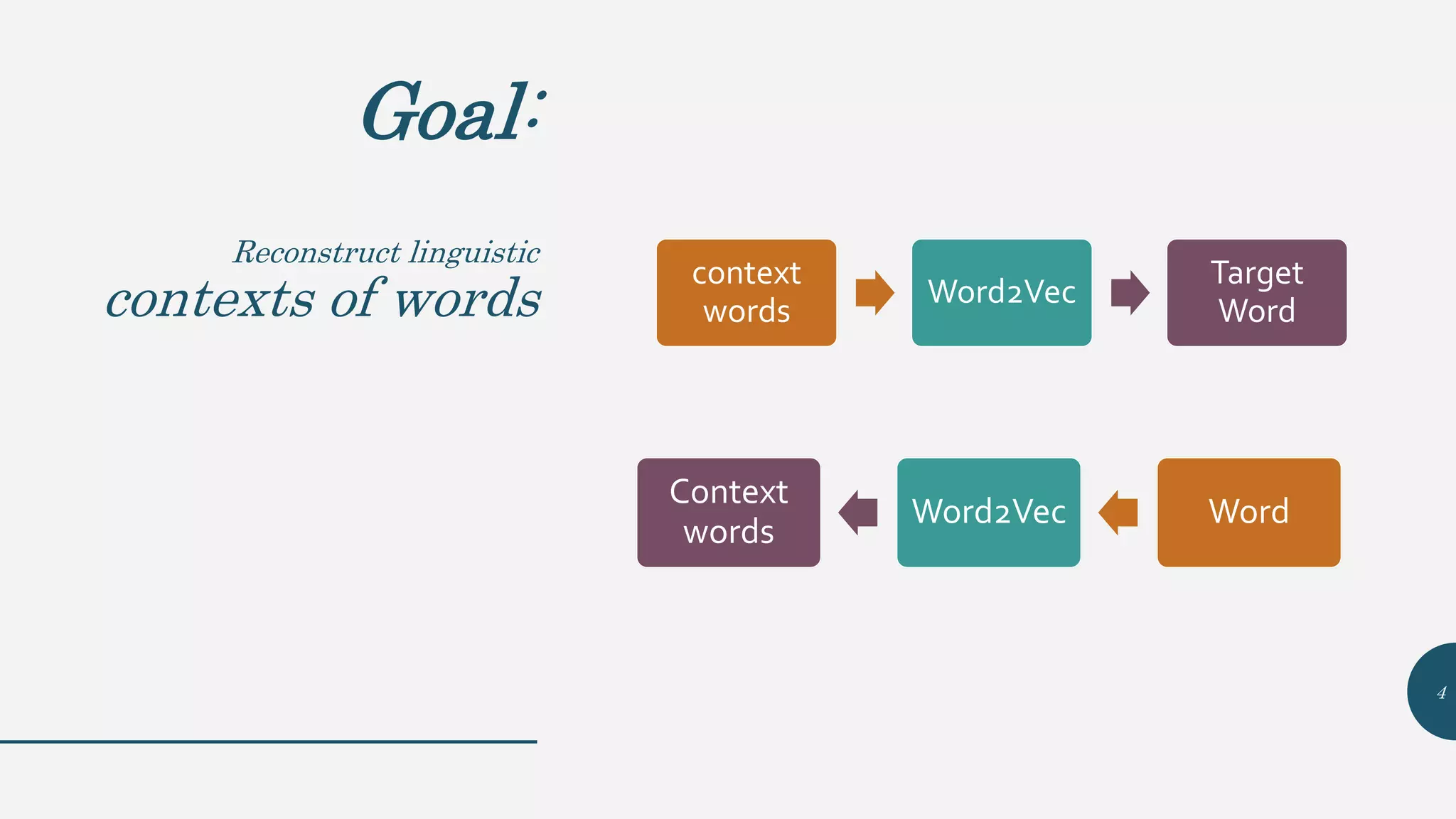
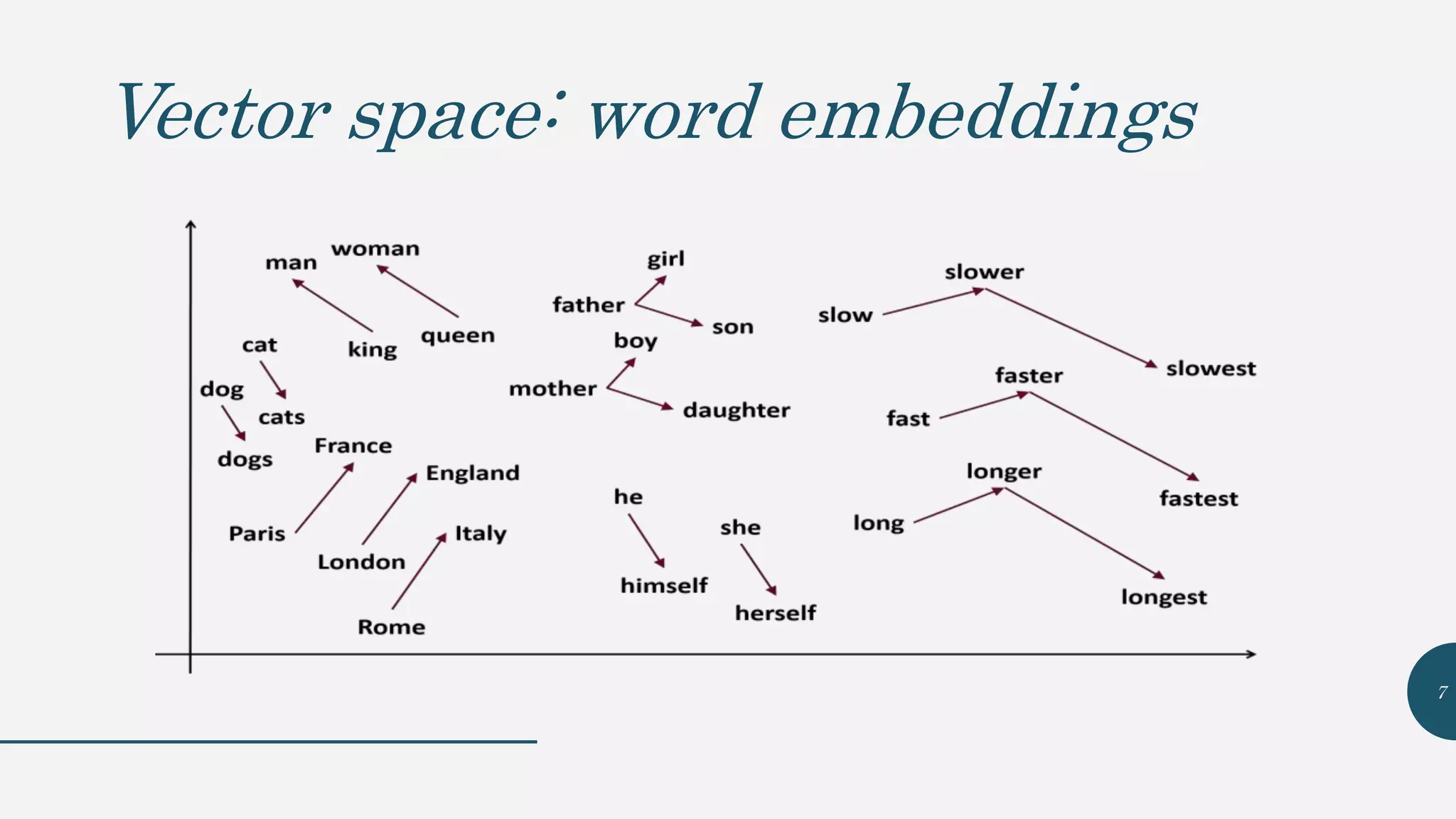
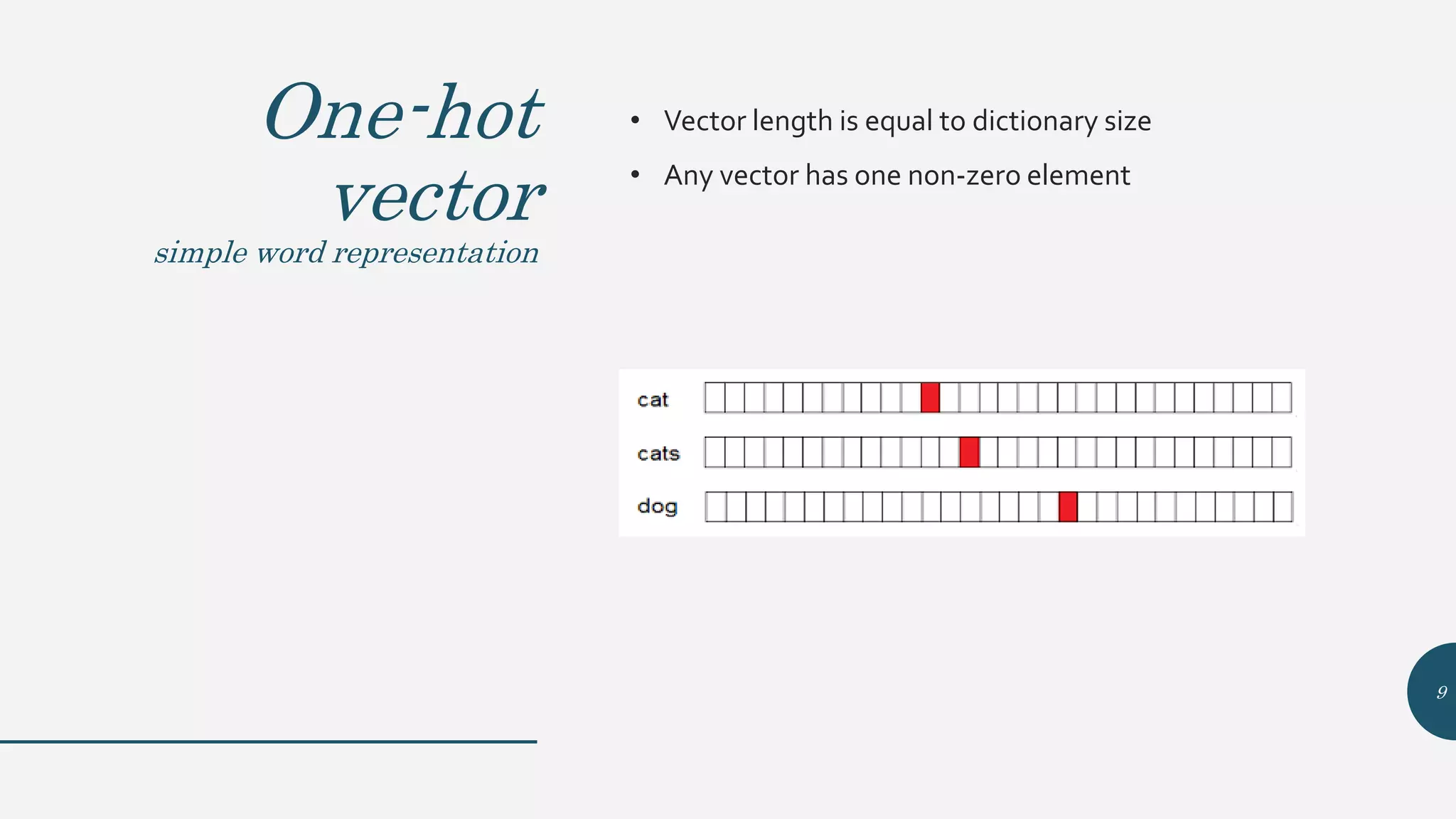
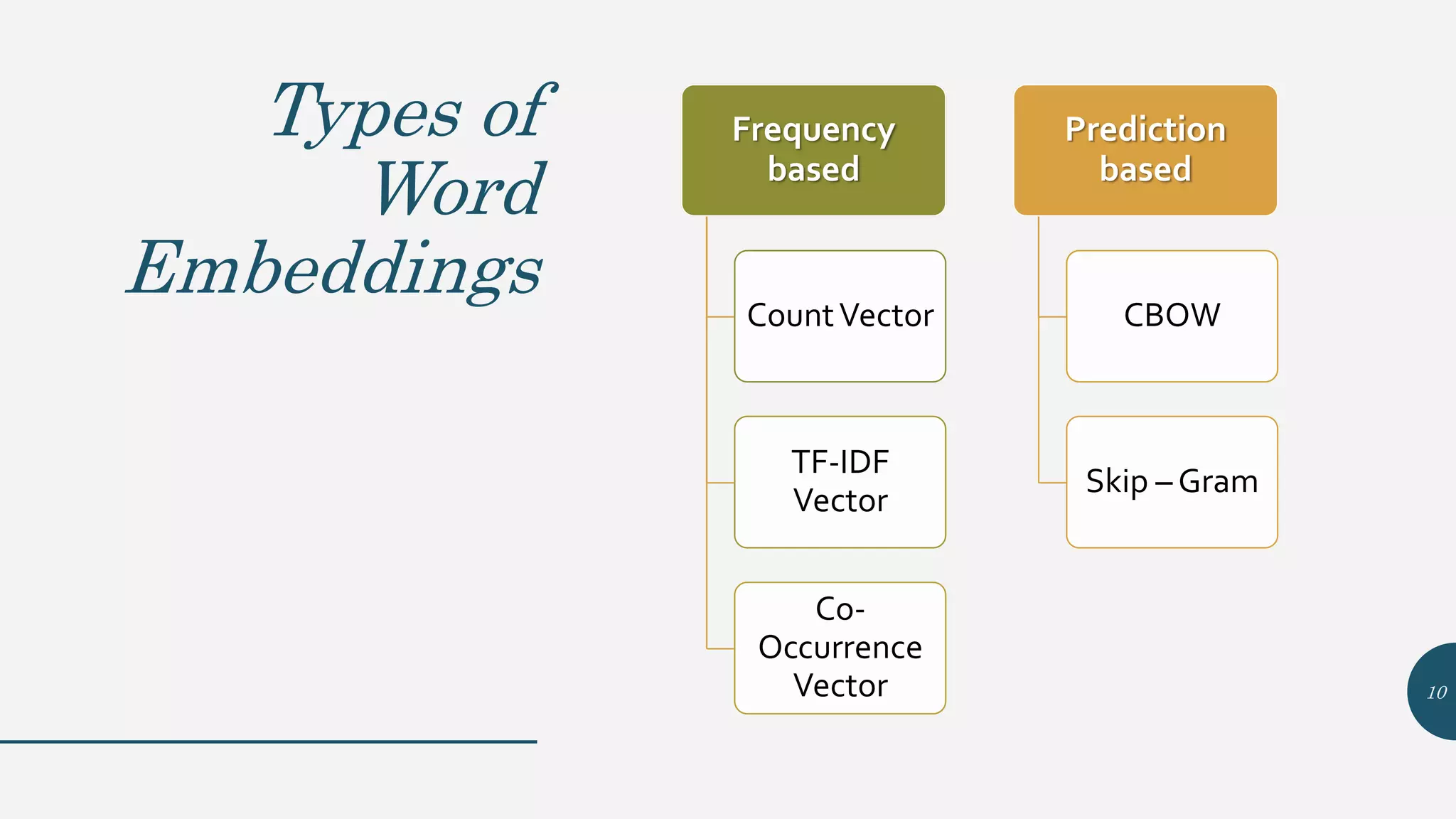
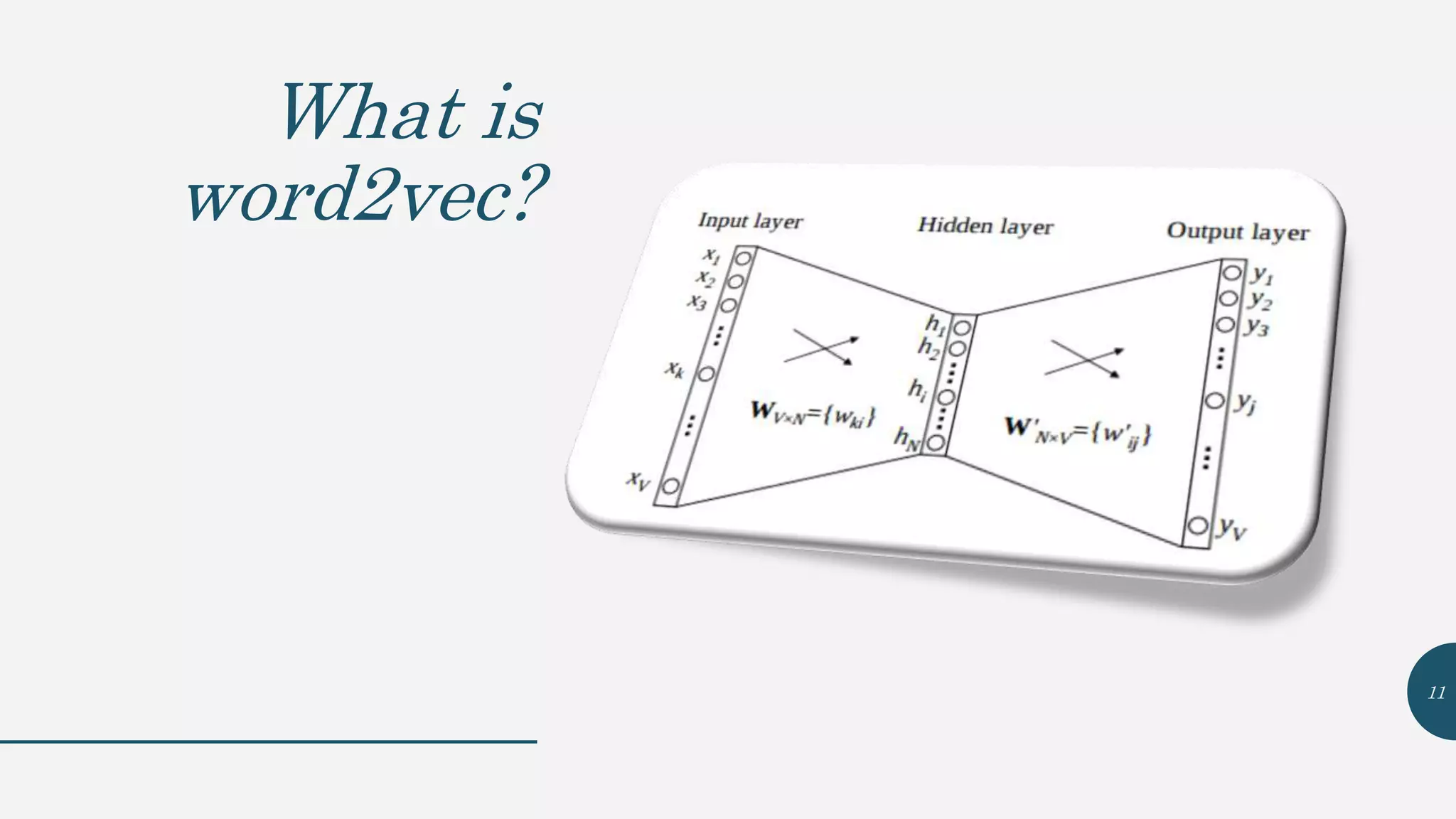
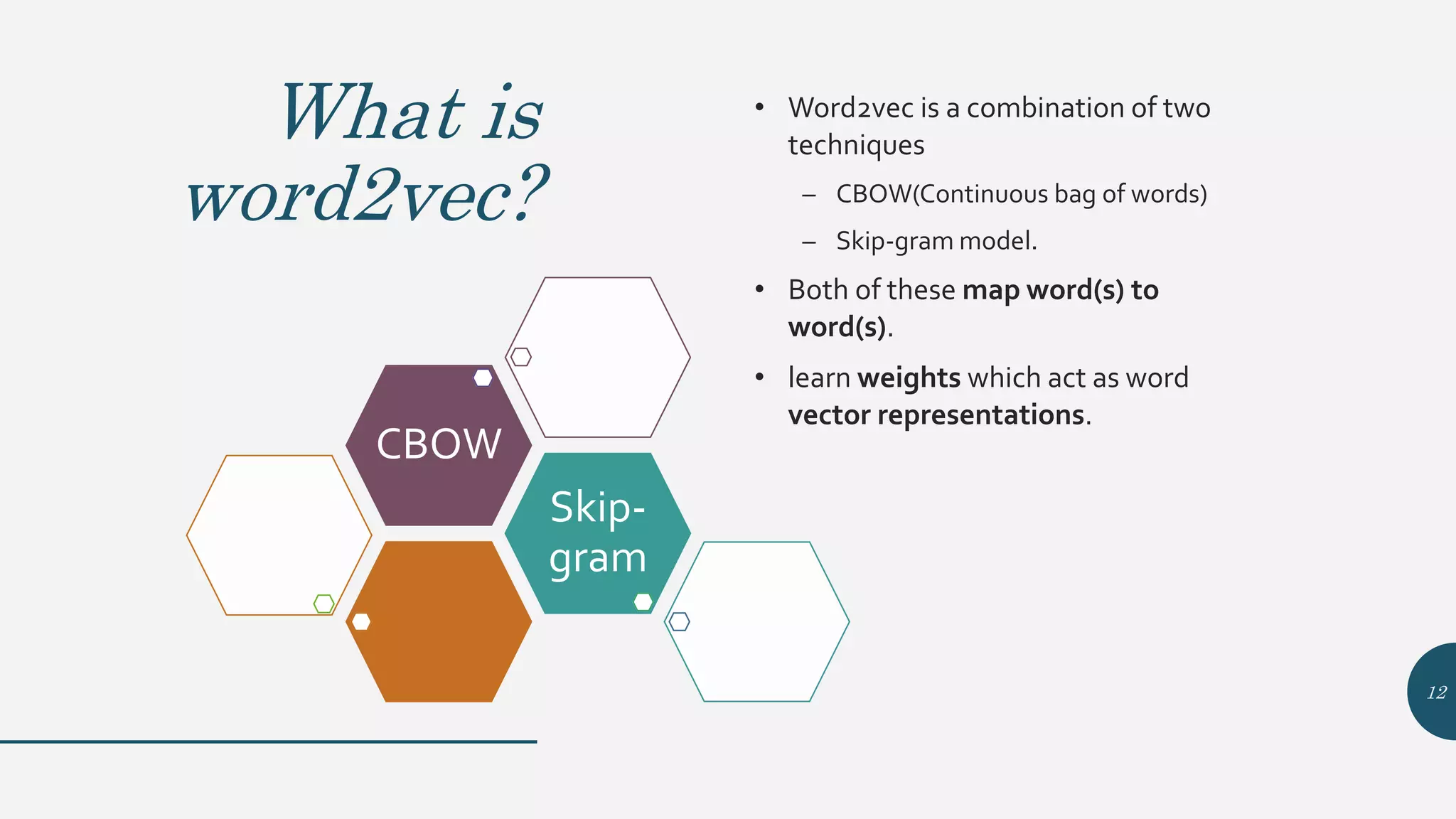
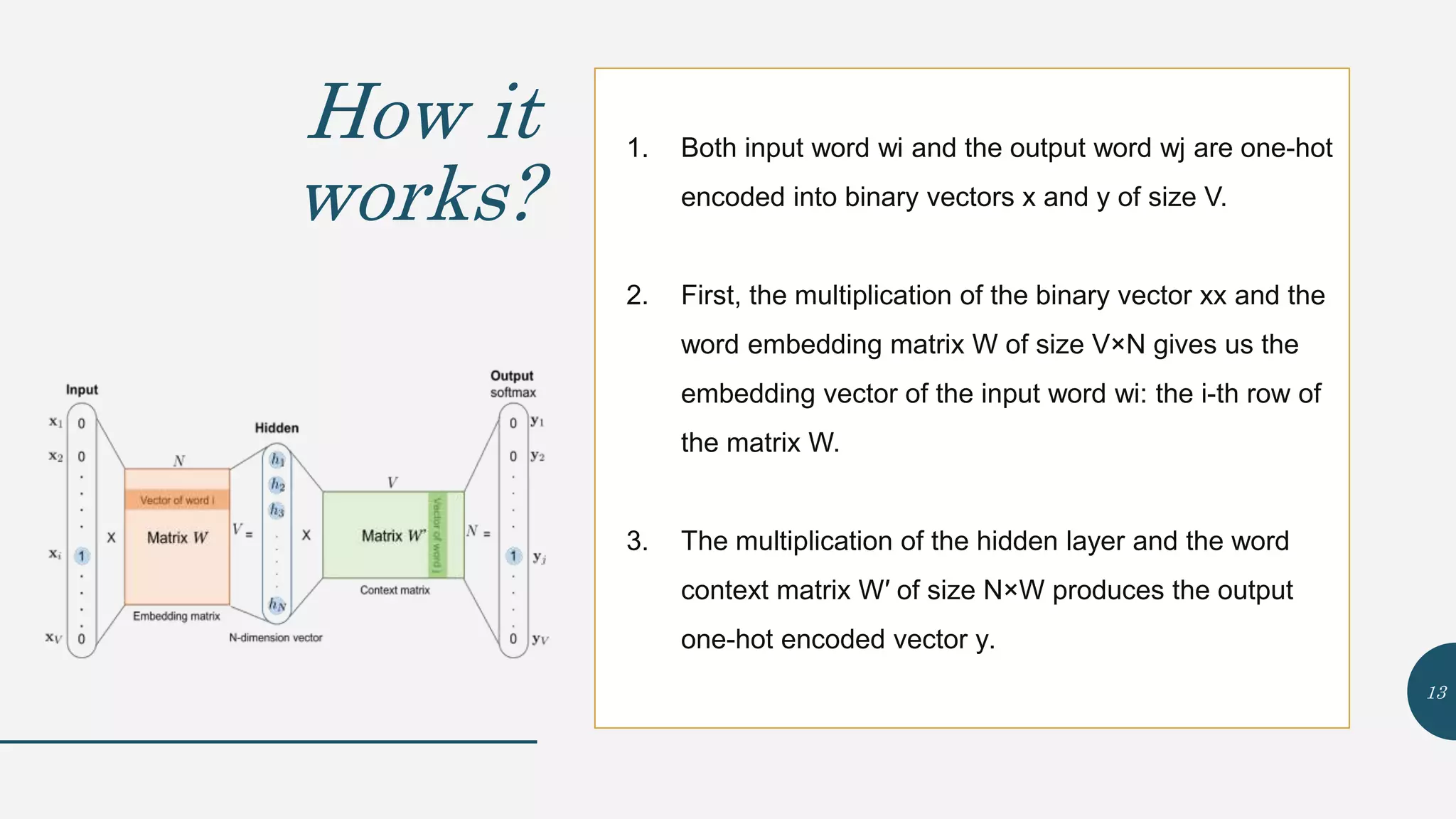
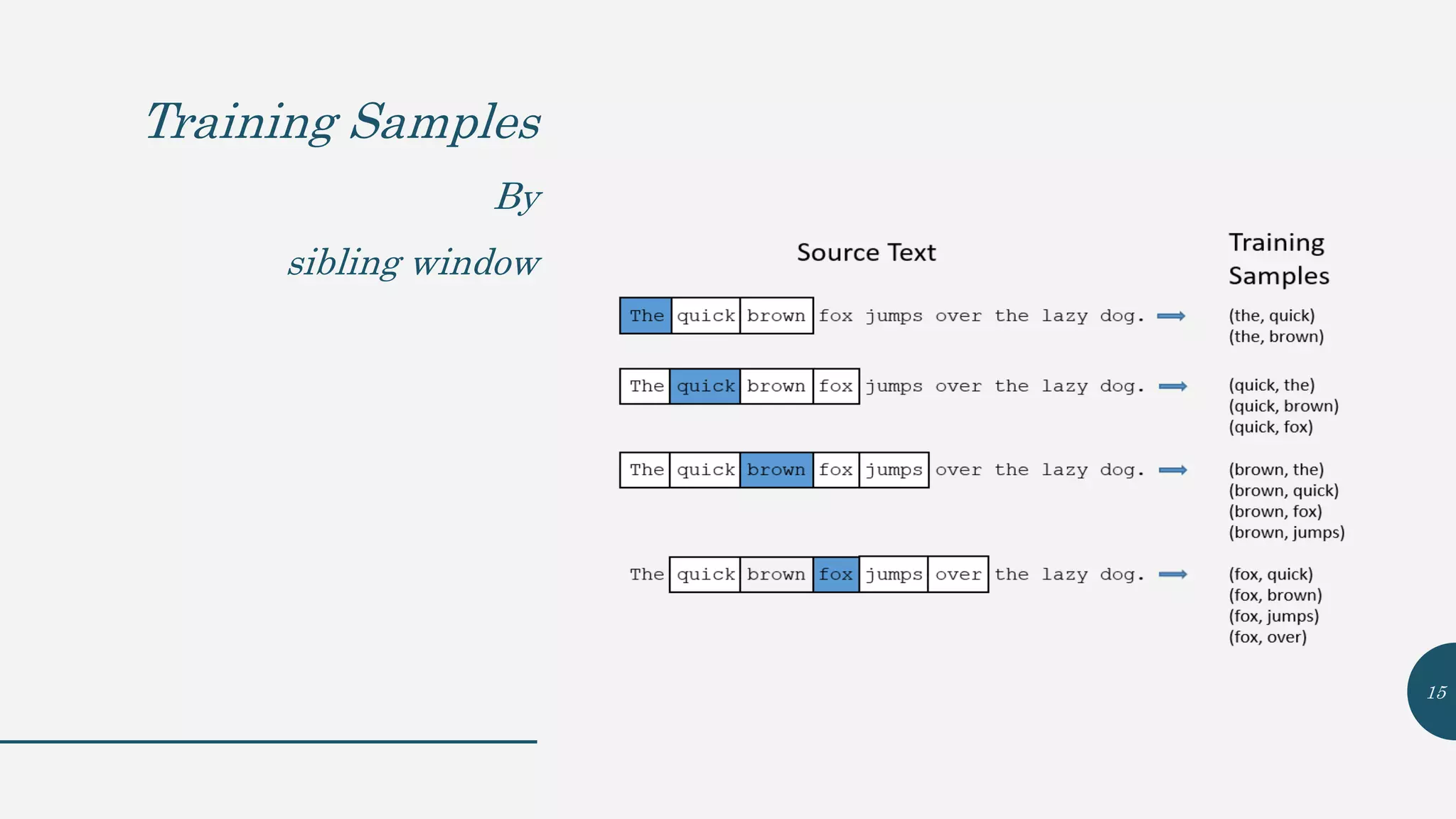
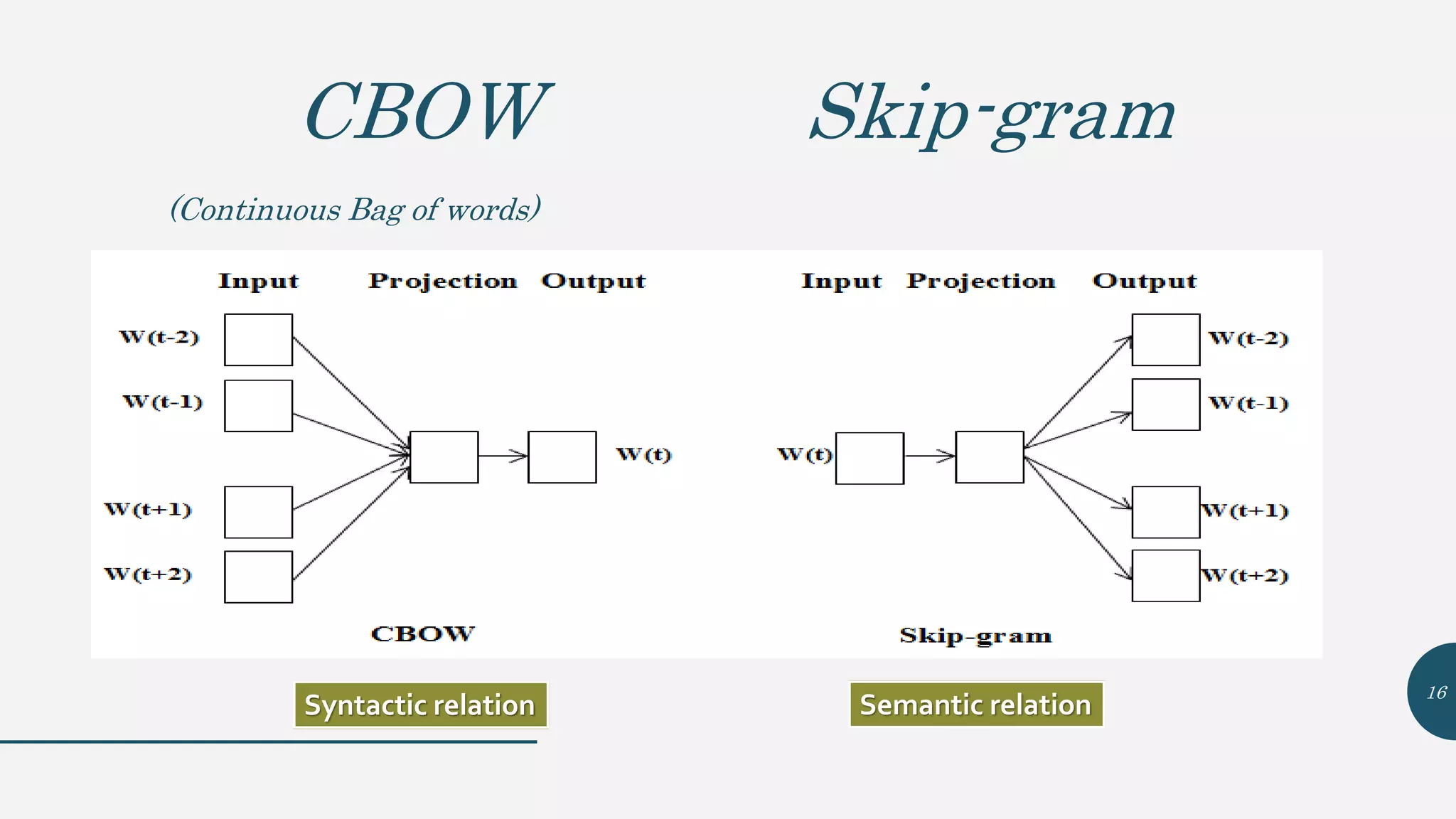
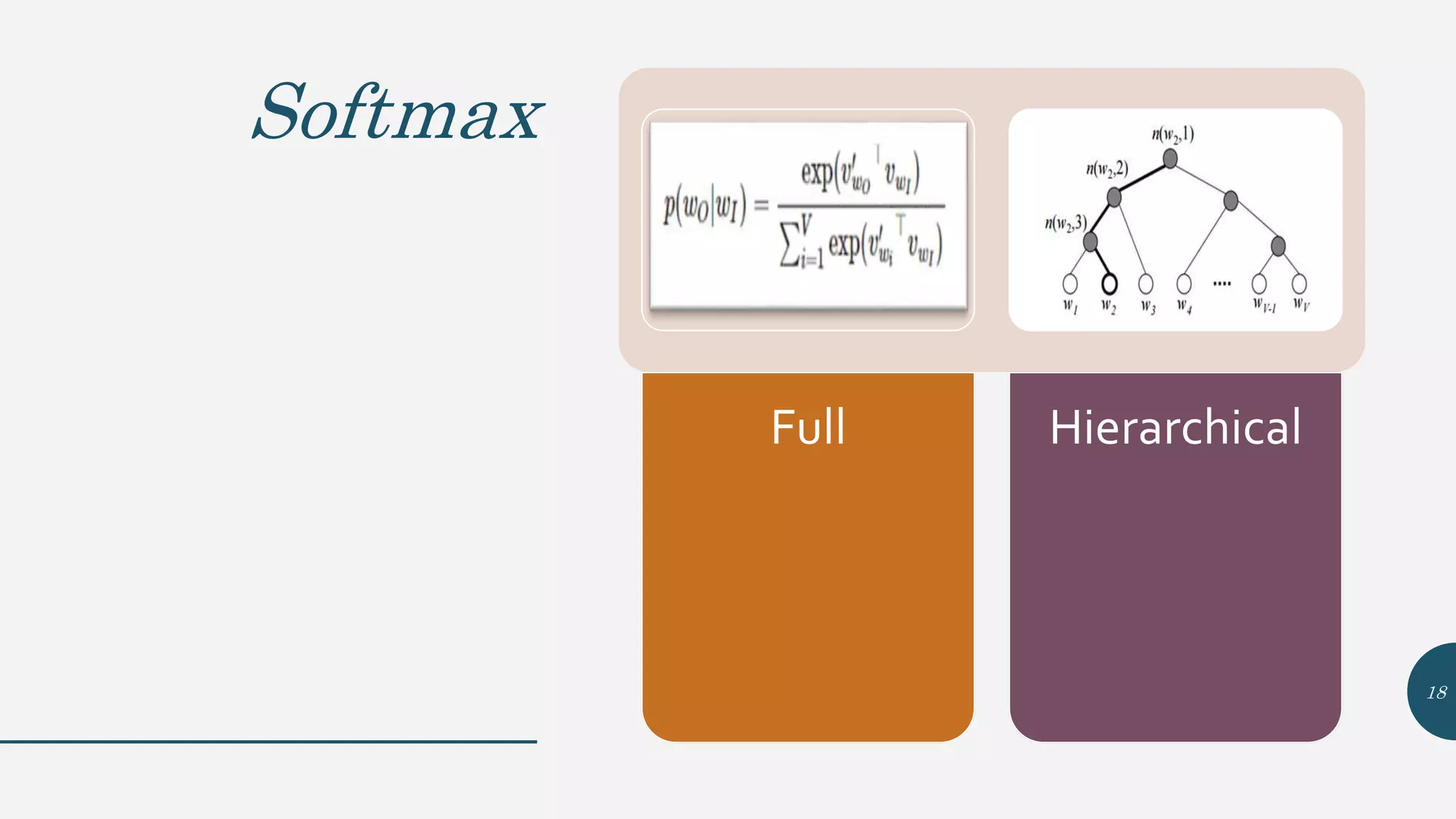
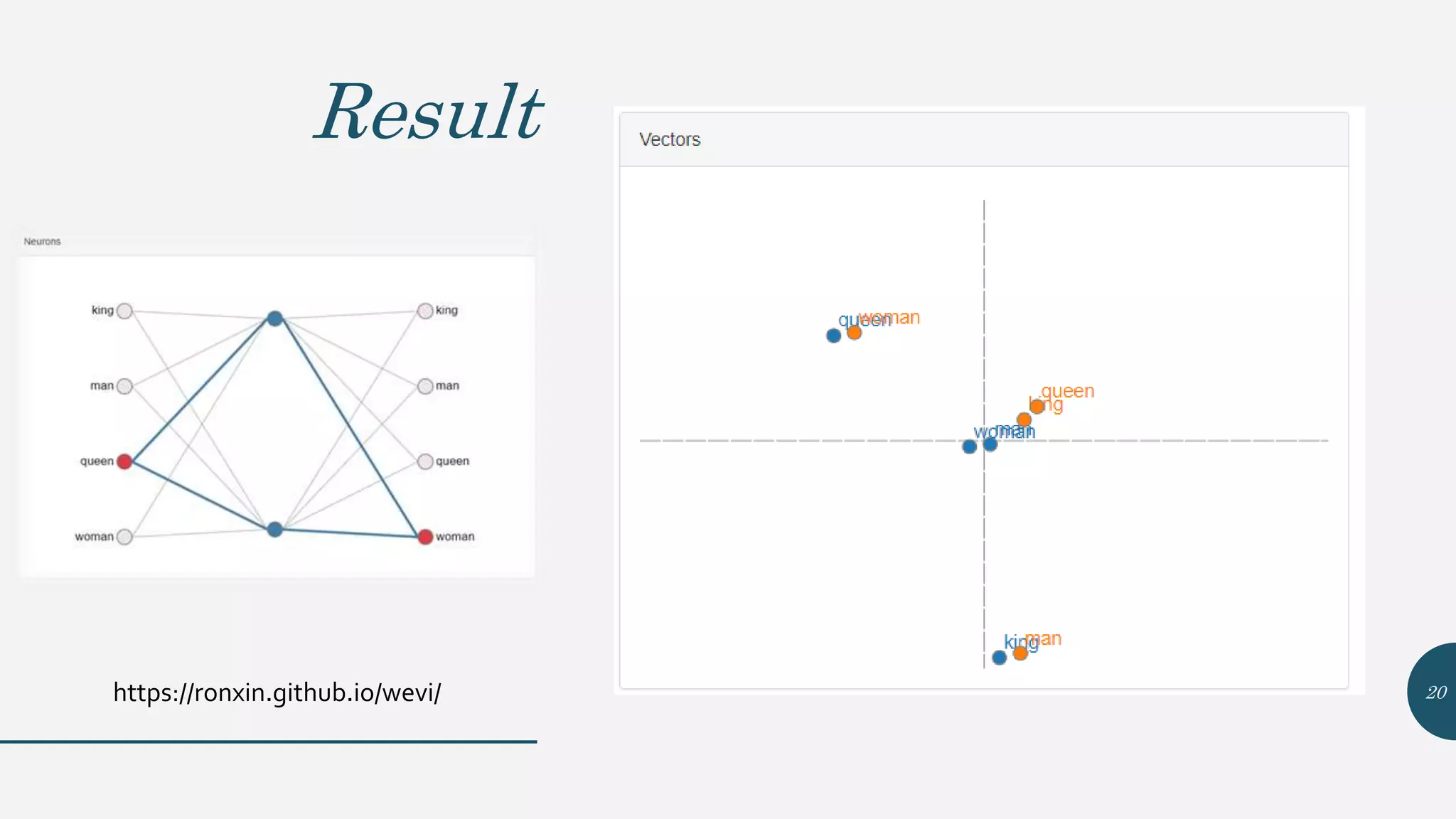
This document provides an overview of Word2Vec, a neural network model for learning word embeddings developed by researchers led by Tomas Mikolov at Google in 2013. It describes the goal of reconstructing word contexts, different word embedding techniques like one-hot vectors, and the two main Word2Vec models - Continuous Bag of Words (CBOW) and Skip-Gram. These models map words to vectors in a neural network and are trained to predict words from contexts or predict contexts from words. The document also discusses Word2Vec parameters, implementations, and other applications that build upon its approach to word embeddings.