Downloaded 16 times



![Mining Text Data: An Introduction
Data Mining / Knowledge Discovery
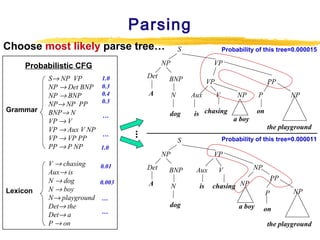
Structured Data
omeLoan (
oanee: Frank Rizzo
ender: MWF
gency: Lake View
mount: $200,000
erm: 15 years
Multimedia
Free Text
Hypertext
Frank Rizzo bought
his home from Lake
View Real Estate in
1992.
He paid $200,000
under a15-year loan
Loans($200K,[map],...) from MW Financial.
<a href>Frank Rizzo
</a> Bought
<a hef>this home</a>
from <a href>Lake
View Real Estate</a>
In <b>1992</b>.
<p>...](https://image.slidesharecdn.com/webandtext-131228044825-phpapp02/85/Web-and-text-3-320.jpg)
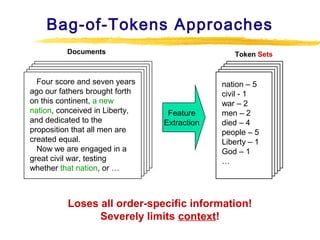
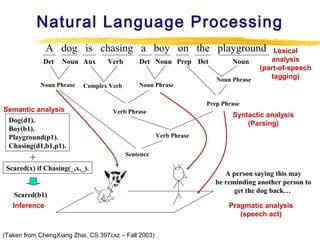


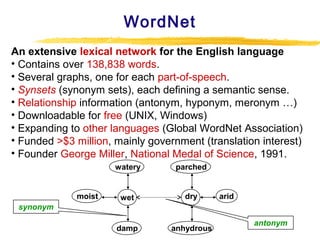
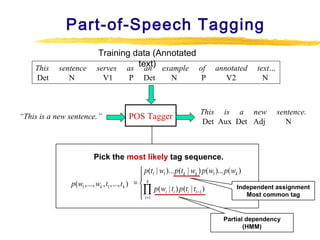




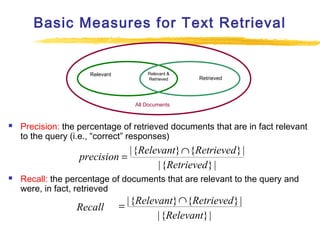










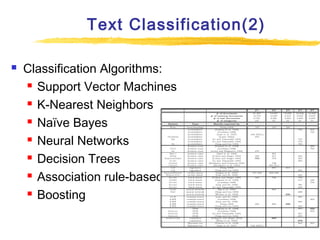

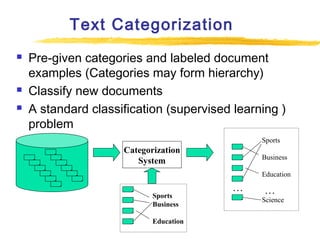



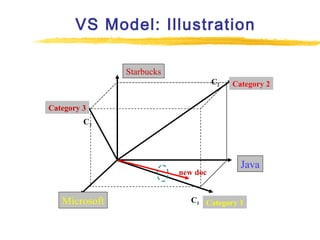






Text mining and natural language processing techniques can be used to extract useful information from text data. Common text mining tasks include text categorization to classify documents into predefined categories, document clustering to group similar documents without predefined categories, and keyword-based association analysis to find frequently co-occurring terms. Text classification algorithms such as support vector machines, naive Bayes classifiers, and neural networks are often applied to categorized documents. The vector space model is commonly used to represent documents as vectors of term weights.




























































































