This document discusses fine-tuning the BERT model with PyTorch and the Transformers library. It provides an overview of BERT, how it was trained, its special tokens, the Transformers library, preprocessing text for BERT, using the BertModel class, the approach to fine-tuning BERT for a task, creating a dataset and data loaders, and training and validating the model.



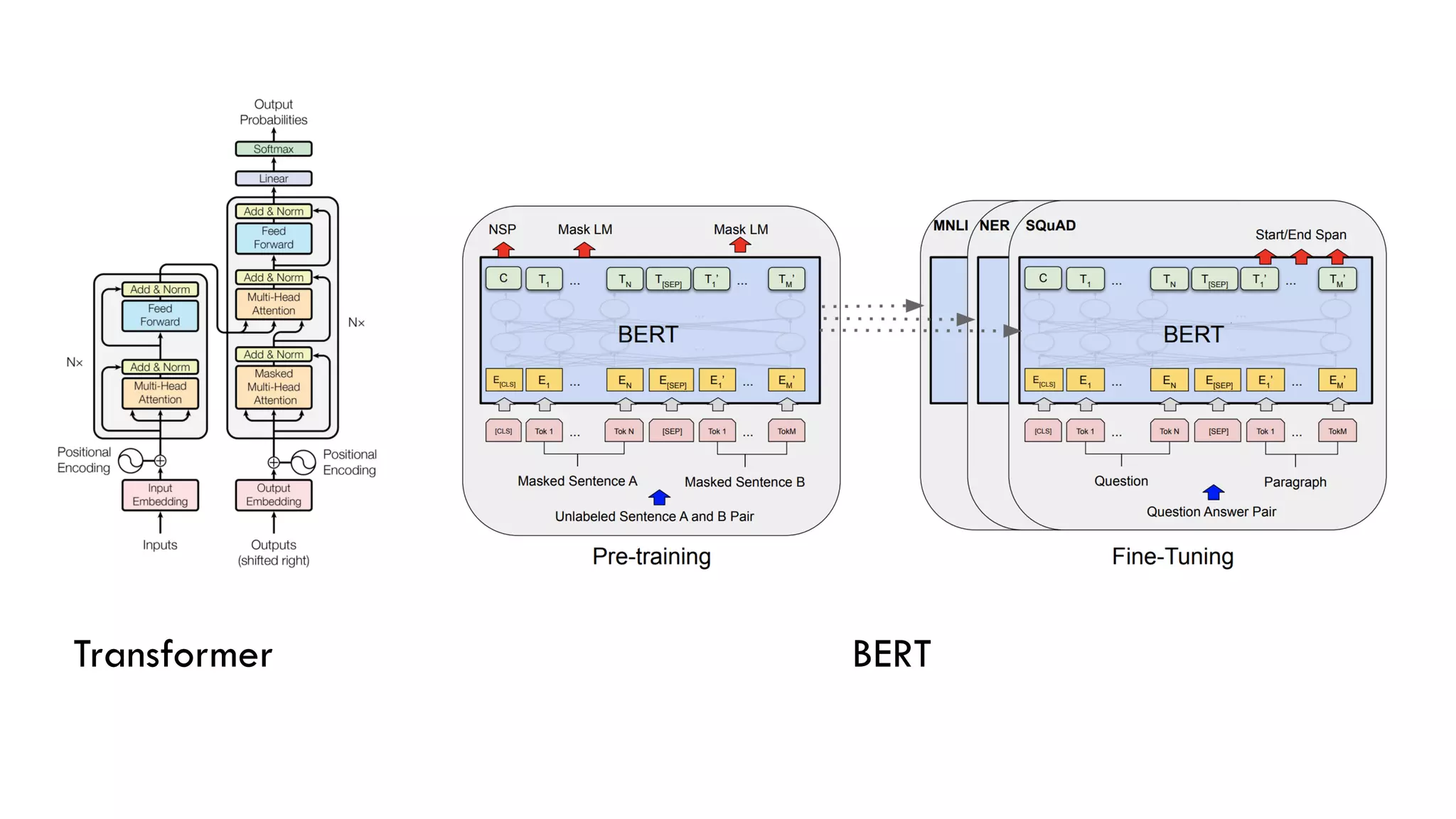
![HOW BERT WAS TRAINED?
[CLS] my dog is cute [SEP] he likes playing [SEP] YES
[CLS] my dog is cute [SEP] the river is flowing [SEP] NO
Next Sentence Prediction (NSP)
Masked Language Model (MLM)
[CLS] my dog is [MASK] [SEP] he [MASK] playing [SEP]](https://image.slidesharecdn.com/bertpresentation-200327164927/75/BERT-Finetuning-Webinar-Presentation-5-2048.jpg)
![SPECIAL TOKENS OF BERT
[CLS] : The first token of every sequence is always a special classification token ([CLS]). The
final hidden state corresponding to this token is used as the aggregate sequence
representation for classification tasks. Sentence pairs are packed together into a single
sequence.
[SEP] : It is basically a sequence delimiter. Must be used when sequence pair tasks are
required. When a single sequence is used it is just appended at the end.
[MASK] : Token used for masked words. Only used for pre-training.
[PAD] : Token used for padding.](https://image.slidesharecdn.com/bertpresentation-200327164927/75/BERT-Finetuning-Webinar-Presentation-6-2048.jpg)

![PREPROCESSING TEXT FOR BERT
1. Tokenization
2. Adding Special Tokens
3. Padding
4. Attention Mask
5. Segment IDs (for sequence pairs)
6. Convert sequence to integers
The dog is cute He likes to play
‘The’ ‘dog’ ‘is’ ‘cute’ ‘he’ ‘likes’ ‘to’ ‘play’
[CLS] ‘The’ ‘dog’ ‘is’ ‘cute’ [SEP] ‘he’ ‘likes’ ‘to’ ‘play’ [SEP]
[CLS] ‘The’ ‘dog’ ‘is’ ‘cute’ [SEP] ‘he’ ‘likes’ ‘to’ ‘play’ [SEP] [PAD]
1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 1 1 1 1 1
[101, 1996, 3899, 2003, 10140, 102, 2002, 7777, 2000, 2377,
102, 0]](https://image.slidesharecdn.com/bertpresentation-200327164927/75/BERT-Finetuning-Webinar-Presentation-8-2048.jpg)
![BERT MODEL CLASS
BERT Model
Sequence
Representations
[CLS]
representation
passed through
linear and tanh
Attentions
(optional)
Hidden states
(optional)
Input sequence Attention Masks
Segment IDs
(only for pairs)](https://image.slidesharecdn.com/bertpresentation-200327164927/75/BERT-Finetuning-Webinar-Presentation-9-2048.jpg)
![OUR APPROACH TO FINE-TUNING
BERT Model
Take the
representation
of the first
token i.e. [CLS]
Sequence
Representations
[CLS]
representation
passed through
linear and tanh
Linear layer](https://image.slidesharecdn.com/bertpresentation-200327164927/75/BERT-Finetuning-Webinar-Presentation-10-2048.jpg)








![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)













![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)