Downloaded 118 times






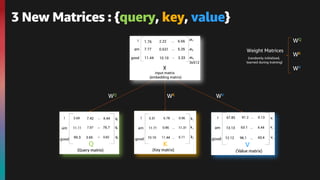
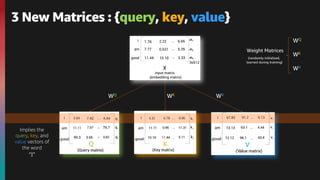
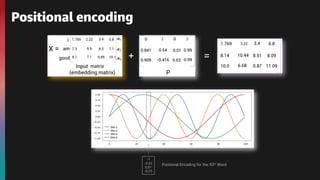
![The embedding of the word I is :
x1 = [1.76, 2.22, … ,6.66]
The embedding of the word am is :
x2 = [7.77, 0.631, … ,5.35]
The embedding of the word good is :
x3 = [11.44, 10.10, … ,3.33]
I am good
*embedding dimension be 512](https://image.slidesharecdn.com/transformers-bert-v0-210825061646/85/An-introduction-to-the-Transformers-architecture-and-BERT-10-320.jpg)









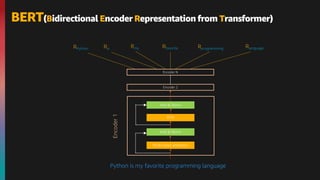
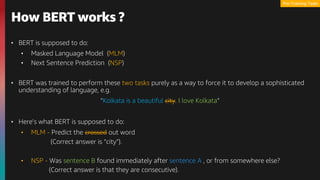
![How BERT works ?
[CLS] Kolkata is a beautiful [MASK] [SEP] I love Kolkata [SEP]
Encoder Layer 1
Encoder Layer 1
Encoder Layer 12
E[CLS] EKolkata Eis Ea Ebeautiful E[SEP] EI Elove EKolkata E[SEP]
Token Embeddings
EA EA EA EA EA EA EB EB EB EB
Segment Embeddings
E0 E1 E2 E3 E4 E6 EB7 E8 E9 E10
Position Embeddings
INPUT
E[MASK]
EA
E5
R[CLS] RKolkata Ris Ra Rbeautiful R[MASK] R[SEP] R[SEP]
RI Rlove RKolkata
OUTPUT
(Enhanced Embedding)
Pre-Training Tasks](https://image.slidesharecdn.com/transformers-bert-v0-210825061646/85/An-introduction-to-the-Transformers-architecture-and-BERT-30-320.jpg)
![How BERT works ?
Pre-Training & Fine-Tuning
[CLS] Suman loves Kolkata [SEP]
Encoder Layer 1
Encoder Layer 1
Encoder Layer 12
INPUT
R[CLS] R[SEP]
RSuman Rloves RKolkata
OUTPUT
(Enhanced Embedding)](https://image.slidesharecdn.com/transformers-bert-v0-210825061646/85/An-introduction-to-the-Transformers-architecture-and-BERT-31-320.jpg)
![How BERT works ?
Pre-Training & Fine-Tuning
.9
.1
Positive
Negative
FFN
+
Softmax
(Sentiment Analysis)
[CLS] Suman loves Kolkata [SEP]
Encoder Layer 1
Encoder Layer 1
Encoder Layer 12
INPUT
R[CLS] R[SEP]
RSuman Rloves RKolkata
OUTPUT
(Enhanced Embedding)](https://image.slidesharecdn.com/transformers-bert-v0-210825061646/85/An-introduction-to-the-Transformers-architecture-and-BERT-32-320.jpg)
![How BERT works ?
Pre-Training & Fine-Tuning
[CLS] Suman loves Kolkata [SEP]
Encoder Layer 1
Encoder Layer 1
Encoder Layer 12
INPUT
OUTPUT
(Enhanced Embedding)
R[CLS] R[SEP]
RSuman Rloves RKolkata
Classifier
PERSON LOCATION
(Name entity recognition)
.9
.1
Positive
Negative
FFN
+
Softmax
(Sentiment Analysis)
[CLS] Suman loves Kolkata [SEP]
Encoder Layer 1
Encoder Layer 1
Encoder Layer 12
INPUT
R[CLS] R[SEP]
RSuman Rloves RKolkata
OUTPUT
(Enhanced Embedding)](https://image.slidesharecdn.com/transformers-bert-v0-210825061646/85/An-introduction-to-the-Transformers-architecture-and-BERT-33-320.jpg)



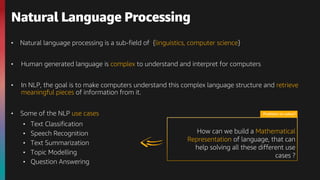
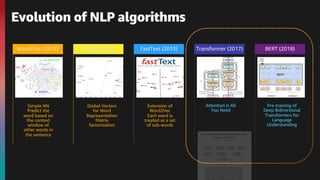
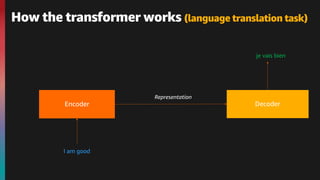
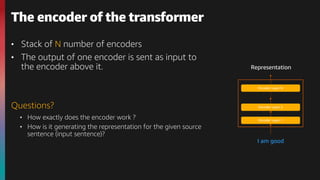
The document provides an overview of natural language processing (NLP) and the evolution of its algorithms, particularly focusing on the transformer architecture and BERT. It explains how these models work, highlighting key components such as the encoder mechanisms, attention processes, and pre-training tasks. Additionally, it addresses various use cases of NLP, including text classification, summarization, and question answering.





![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)

































































