Downloaded 109 times


















![DO IT YOURSELF
model.most_similar(‘apple’)
[(’banana’, 0.8571481704711914), ...]
model.doesnt_match("breakfast cereal dinner lunch".split())
‘cereal’
model.similarity(‘woman’, ‘man’)
0.73723527
Suzan Verberne](https://image.slidesharecdn.com/2018-03-23w2vtutorial-180323120733/85/Tutorial-on-word2vec-25-320.jpg)



![WHAT CAN YOU DO WITH IT?
Mining knowledge about natural language
Selecting out-of-the-list words
Example: which word does not belong in [monkey, lion, dog, truck]
Selectional preferences
Example: predict typical verb-noun pairs: people as subject of eating is more
likely than people as object of eating
Imrove NLP applications:
Sentence completion/text prediction
Bilingual Word Embeddings for Phrase-Based Machine Translation
Suzan Verberne](https://image.slidesharecdn.com/2018-03-23w2vtutorial-180323120733/85/Tutorial-on-word2vec-30-320.jpg)

![DEAL WITH PHRASES
Entities as single words:
during pre-processing: find collocations (e.g. Wikipedia anchor texts),
and feed them as single ‘words’ to the neural network.
Bigrams (built-in function)
bigram = gensim.models.Phrases(sentence_stream)
term_list = list(bigram[sentence_stream])
model = gensim.models.Word2Vec(term_list)
Suzan Verberne](https://image.slidesharecdn.com/2018-03-23w2vtutorial-180323120733/85/Tutorial-on-word2vec-32-320.jpg)





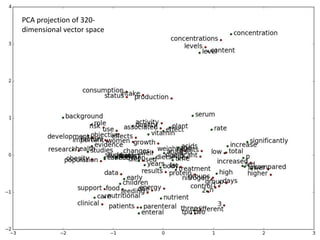
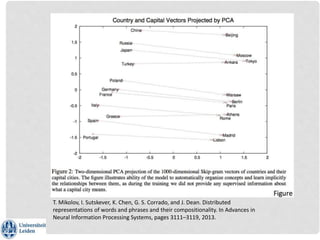
The document is a tutorial on word2vec, a computational model for learning word embeddings from raw text, designed to map similar words to nearby points in a vector space. It covers the background of the distributional hypothesis, vector space models, and various techniques for training word embeddings, including advantages and applications in NLP. Hands-on practical sessions using the Python package gensim exemplify how to implement and evaluate word2vec models.
















































































