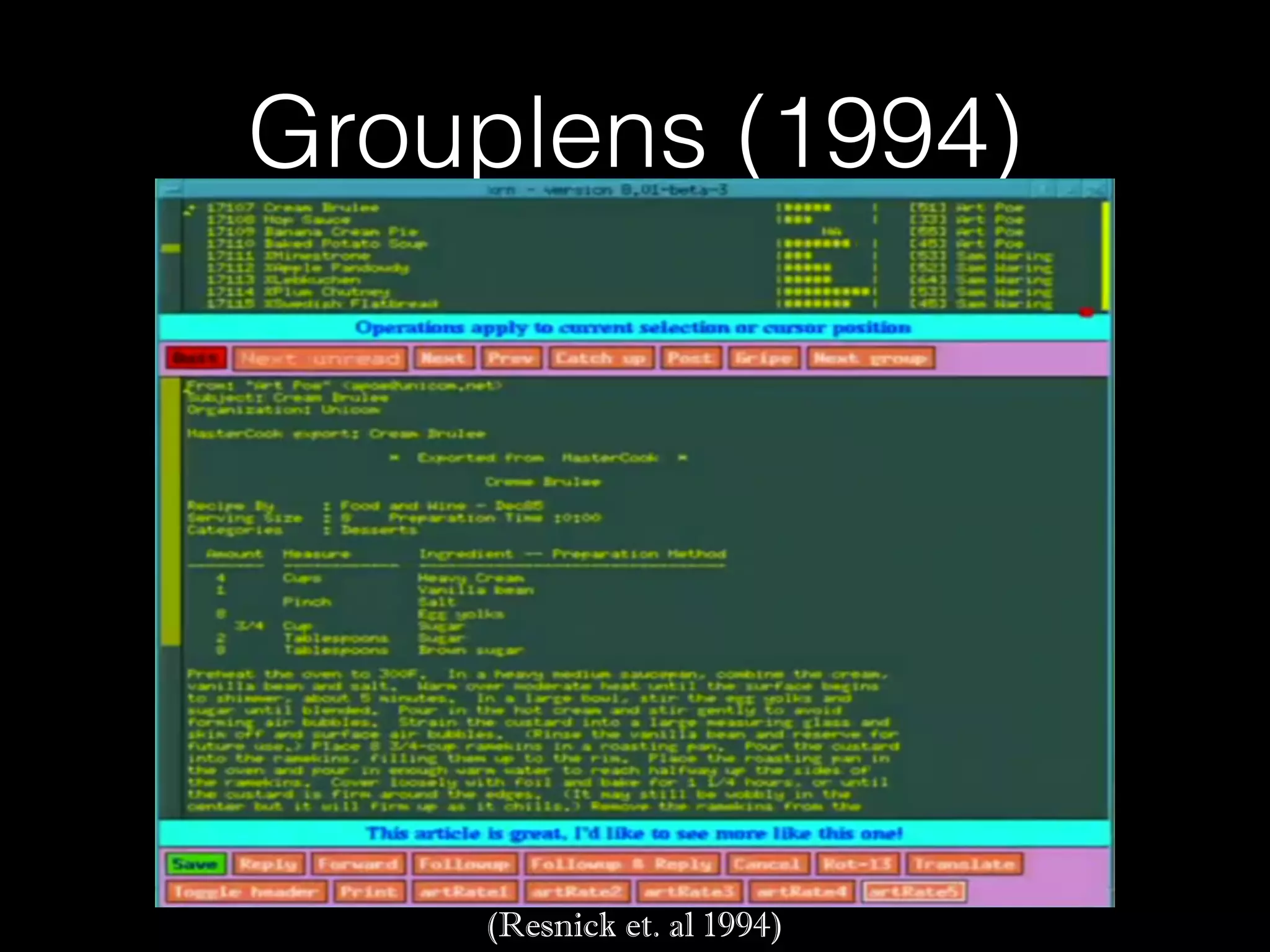
Downloaded 268 times








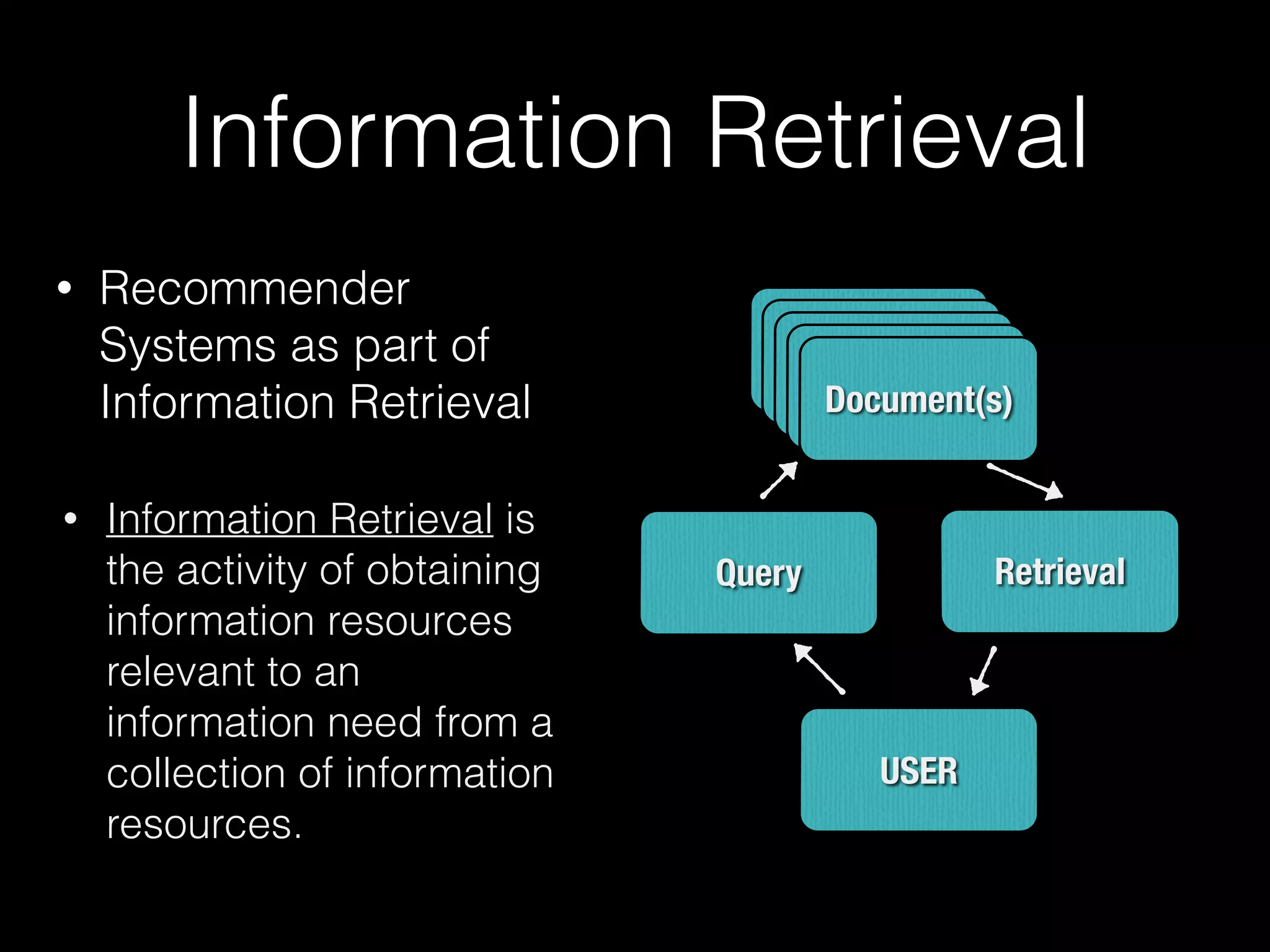




























![• similarity/distance measures:
• Euclidean distance
• Jaccard distance
• Cosine distance
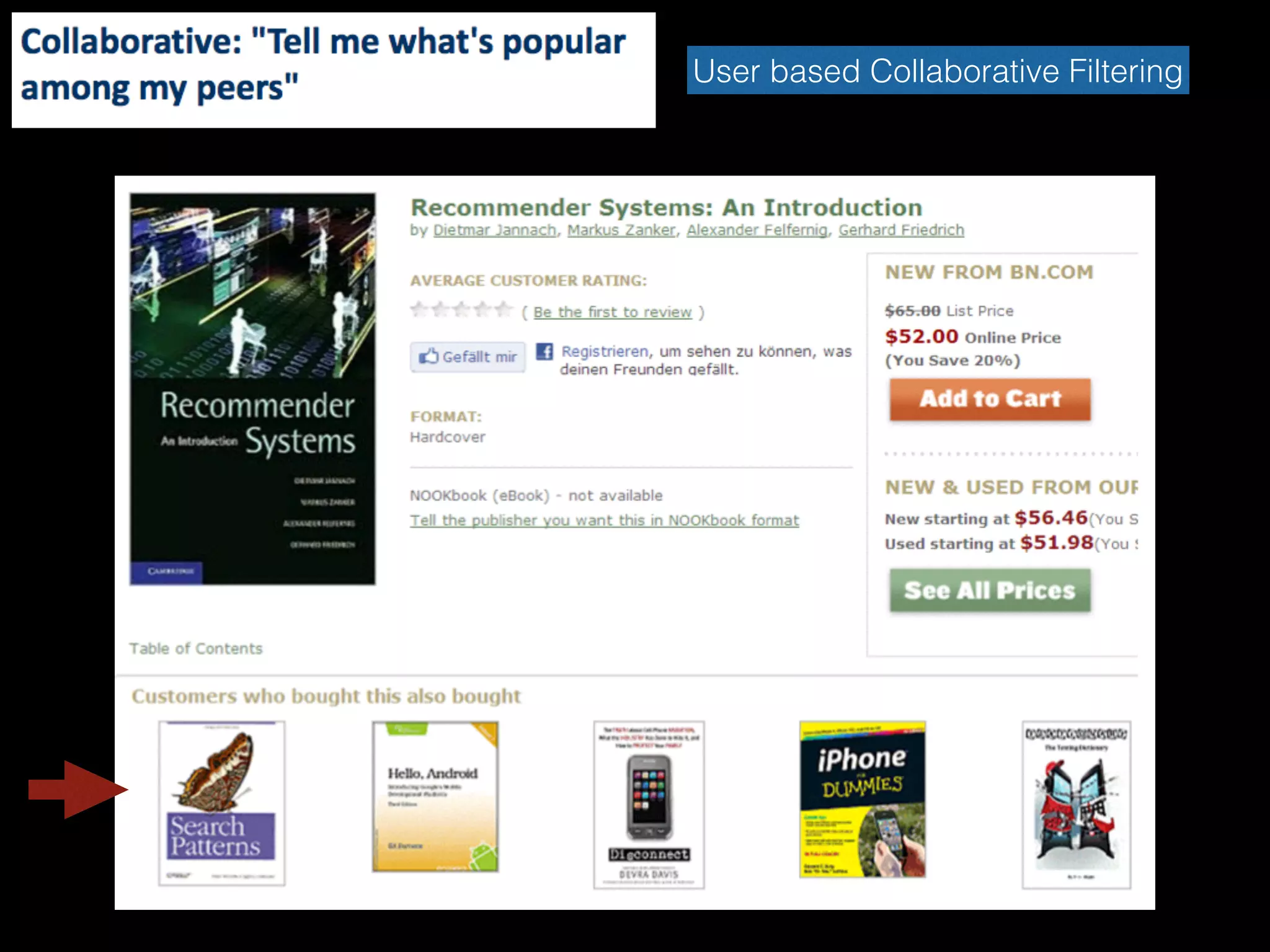
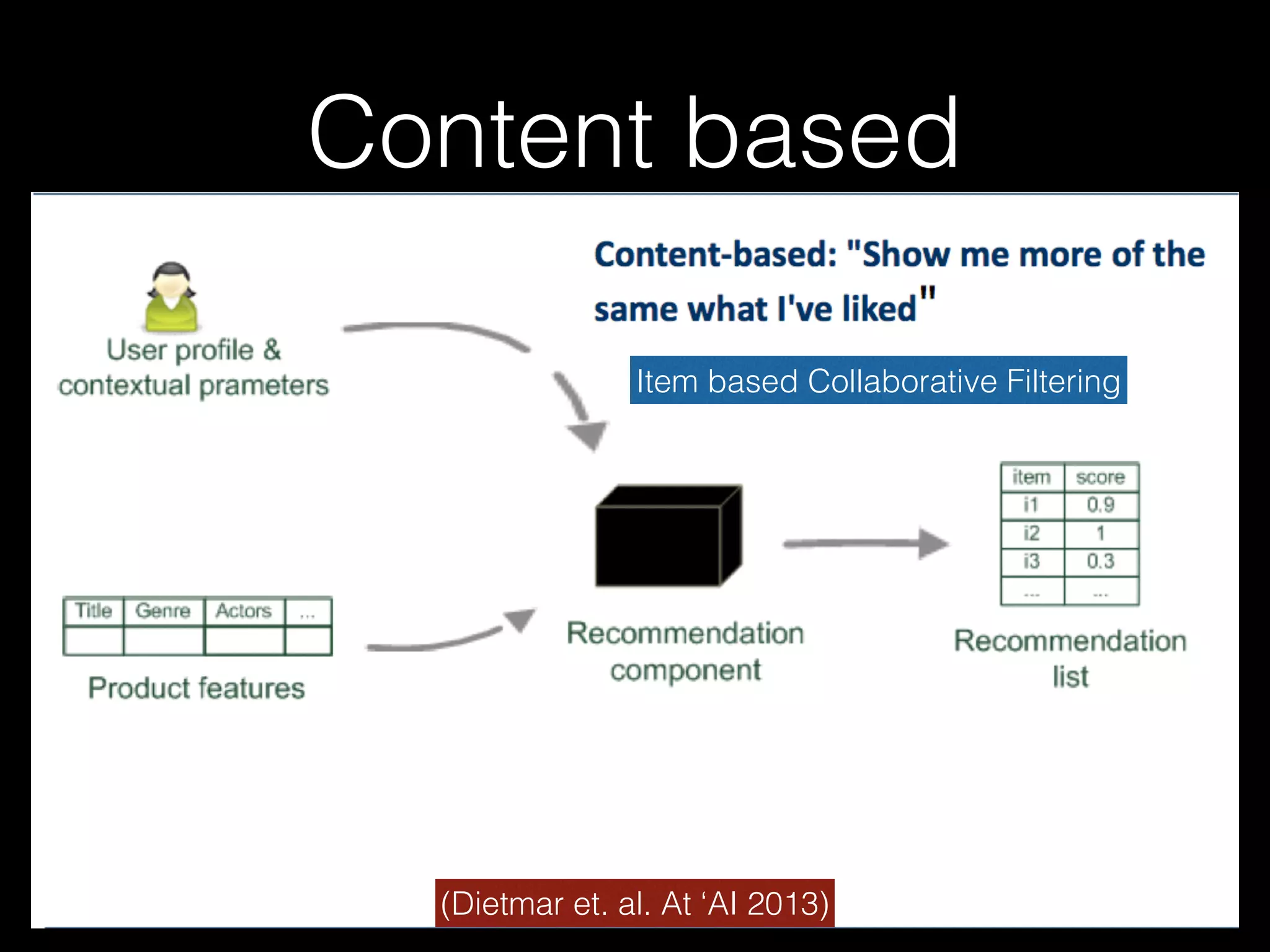
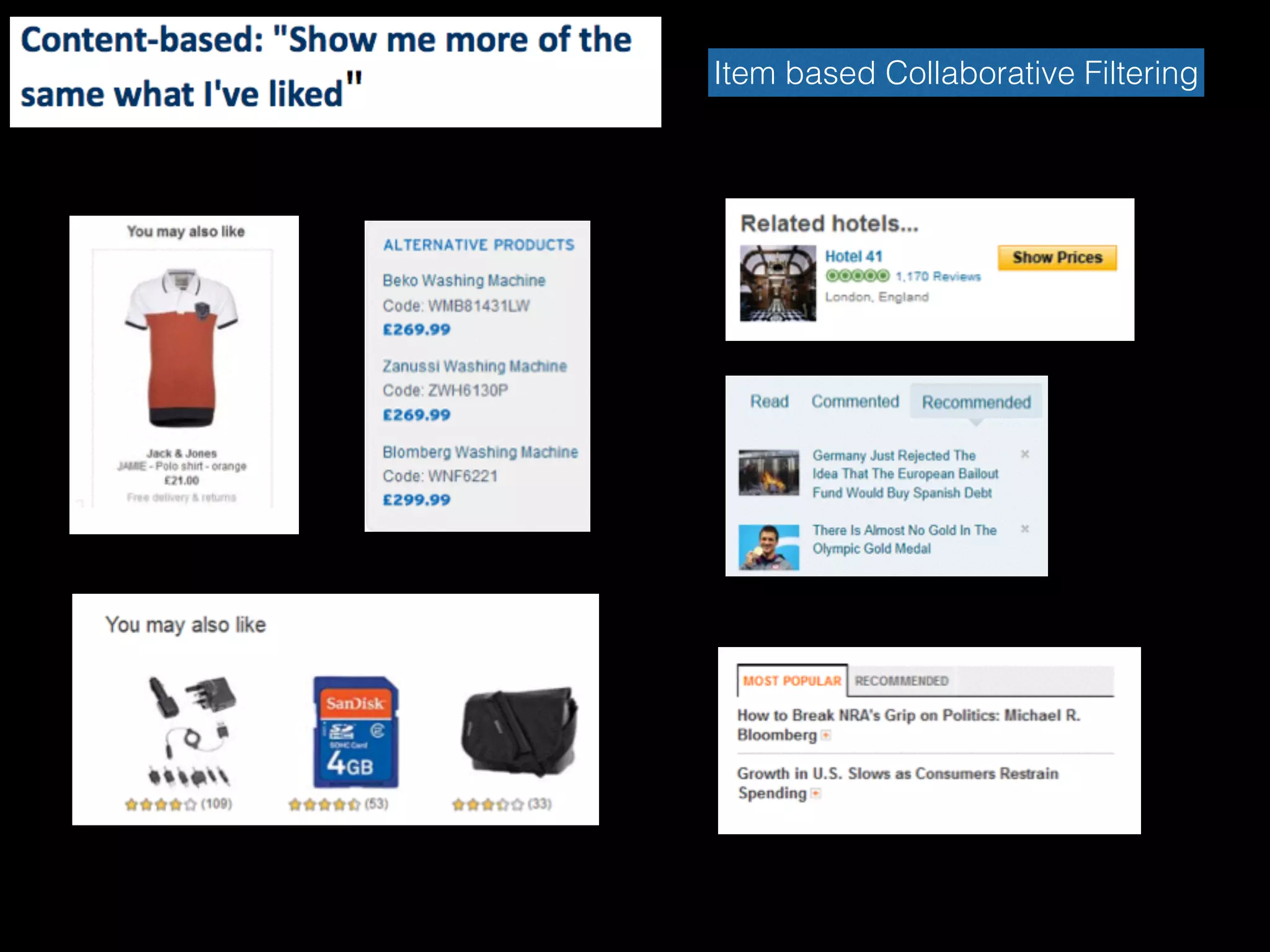
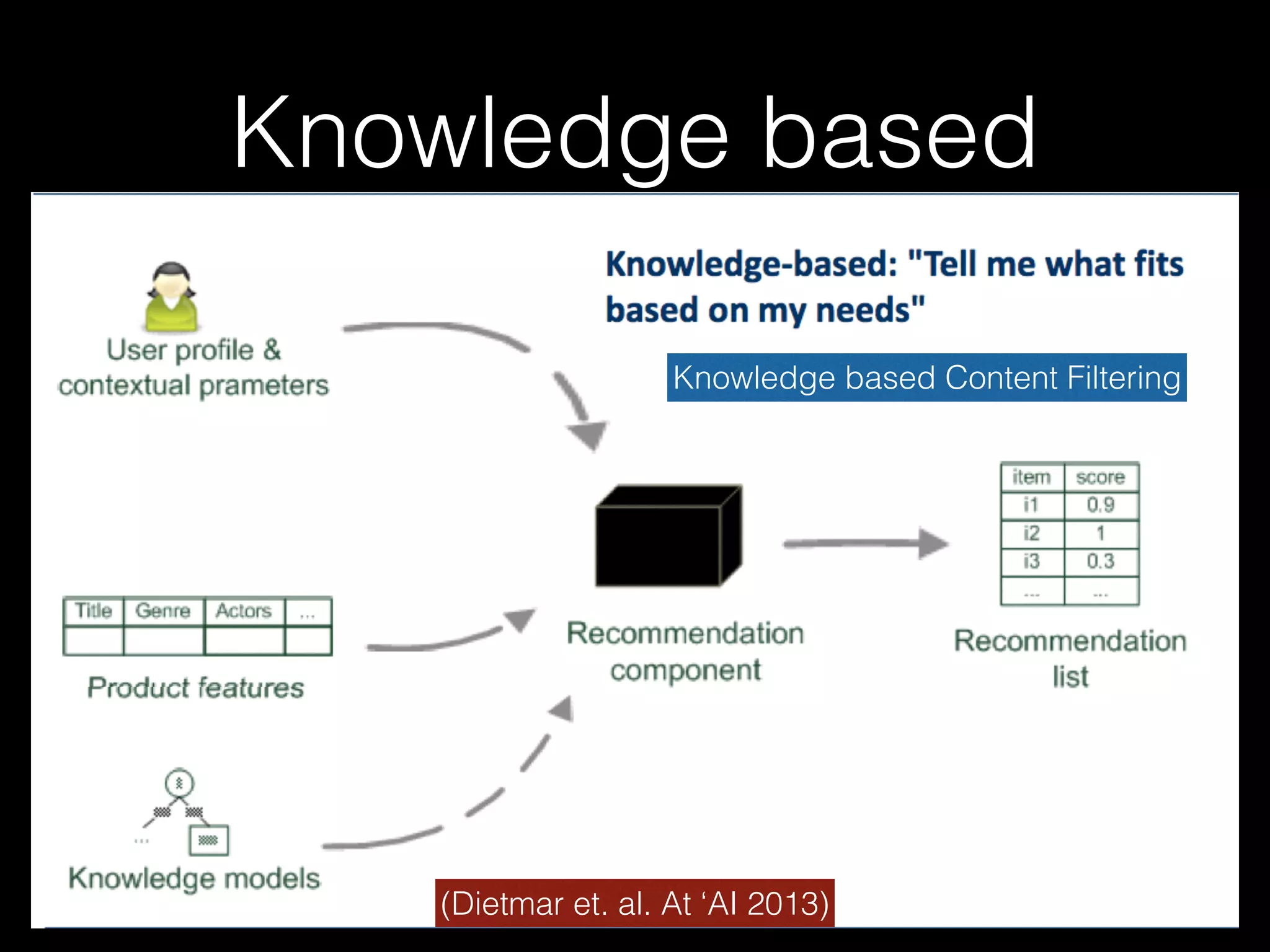
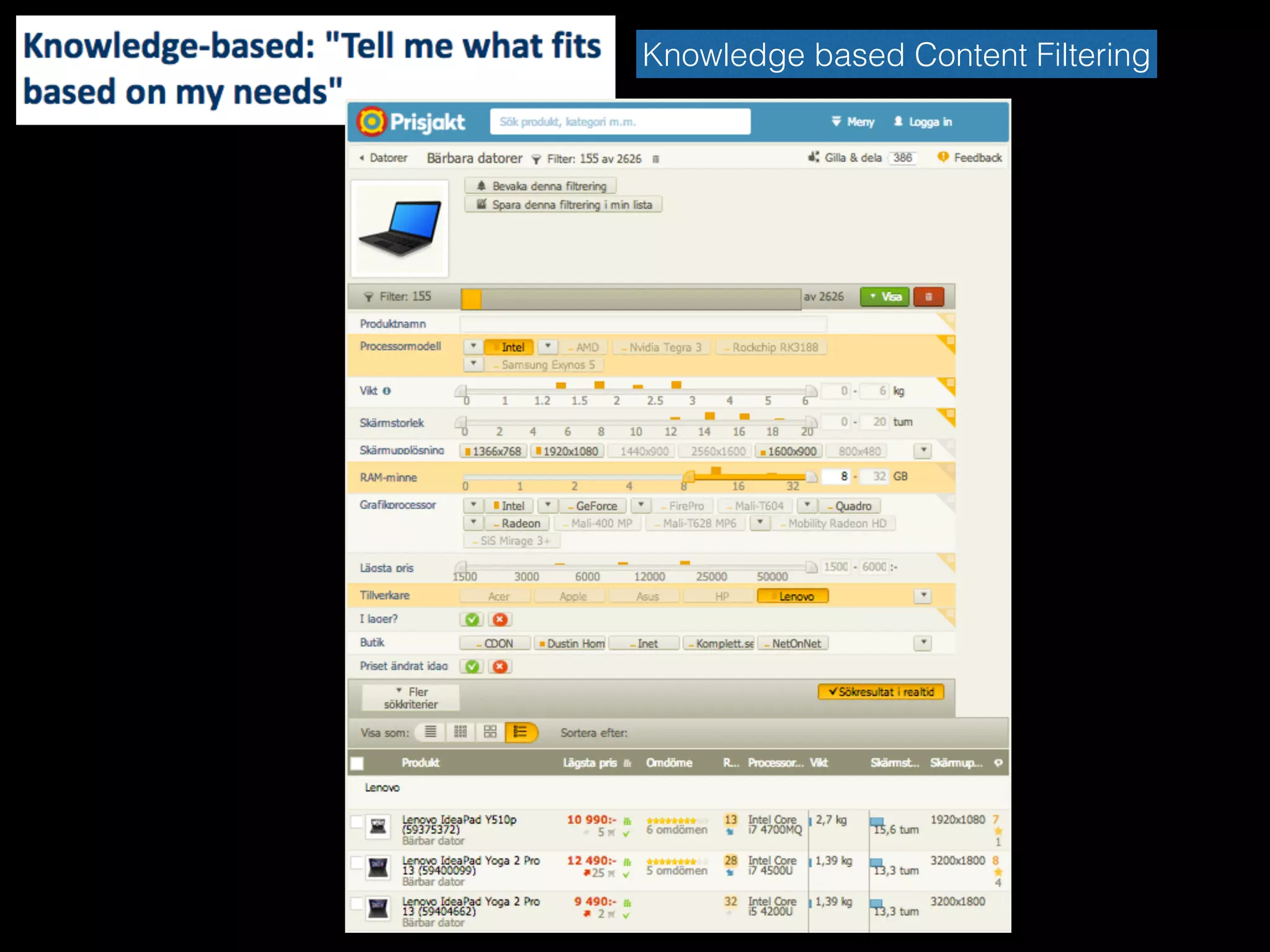
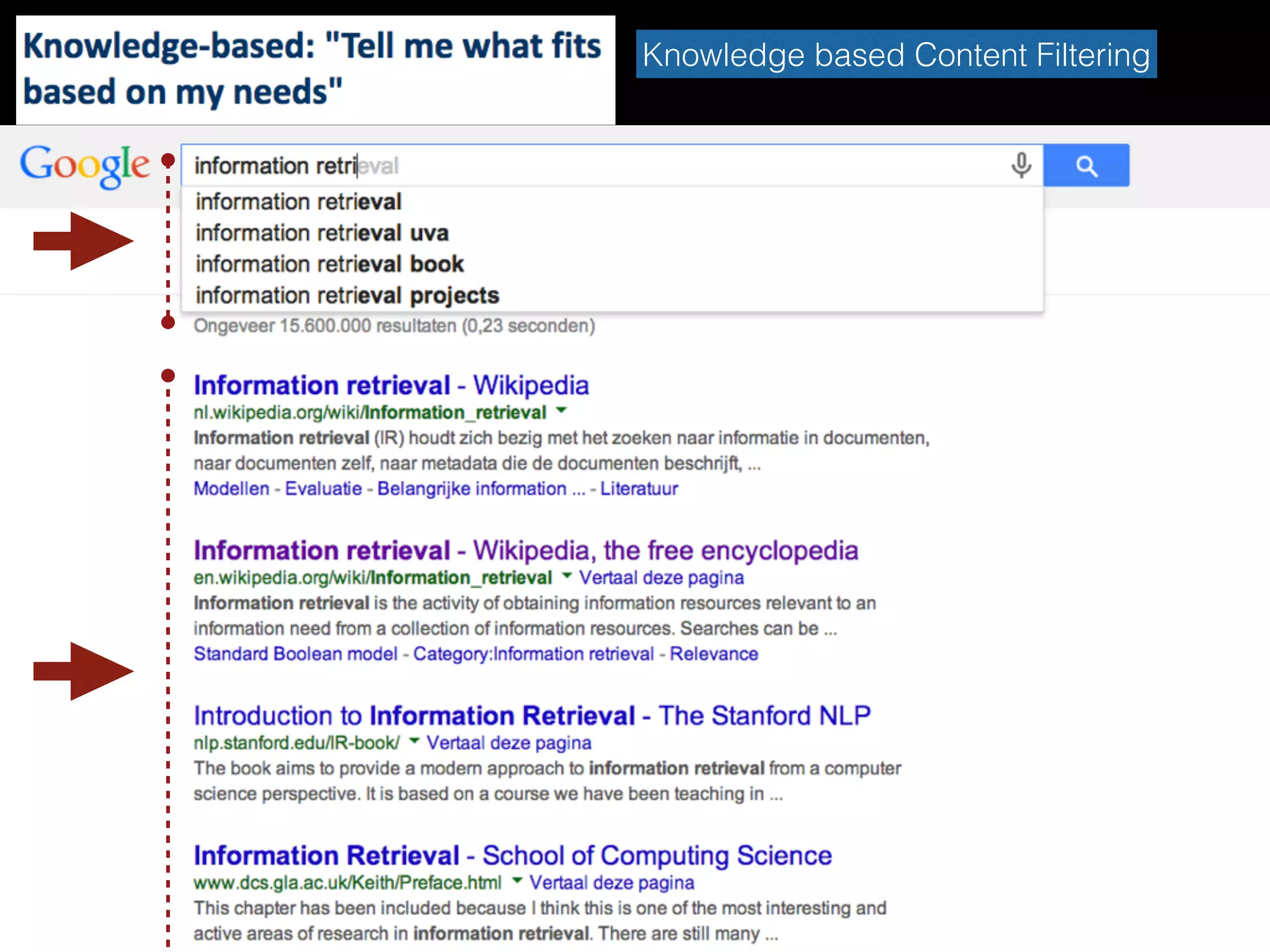
Content-based Filtering
dot product x.y is
1 × 2 + 2 × 1 + (−1) × 1 = 3
x = [1,2, −1] and = [2,1,1].
L2-norm =
√12 + 22 + (−1)2 = 6
ie:](https://image.slidesharecdn.com/recsysprephd2pub-140520033122-phpapp02/75/Recommender-Systems-Matrices-and-Graphs-48-2048.jpg)
![• similarity/distance measures:
• Euclidean distance
• Jaccard distance
• Cosine distance
Content-based Filtering
dot product x.y is
1 × 2 + 2 × 1 + (−1) × 1 = 3
x = [1,2, −1] and = [2,1,1].
cosine of angle:
3/(√6√6) =1/2
cos distance of 1/2:
60 degrees,
L2-norm =
√12 + 22 + (−1)2 = 6
ie:](https://image.slidesharecdn.com/recsysprephd2pub-140520033122-phpapp02/75/Recommender-Systems-Matrices-and-Graphs-49-2048.jpg)










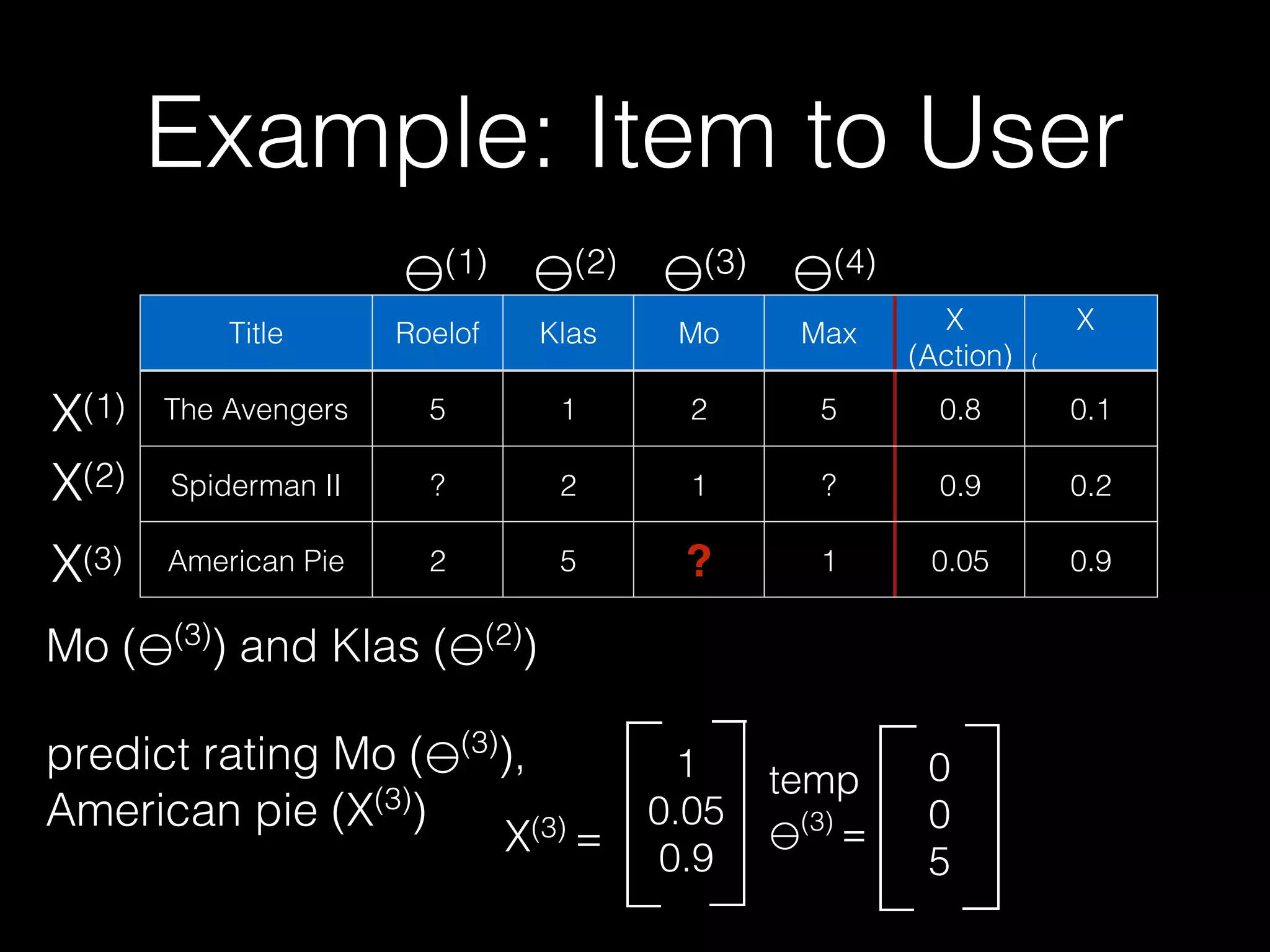
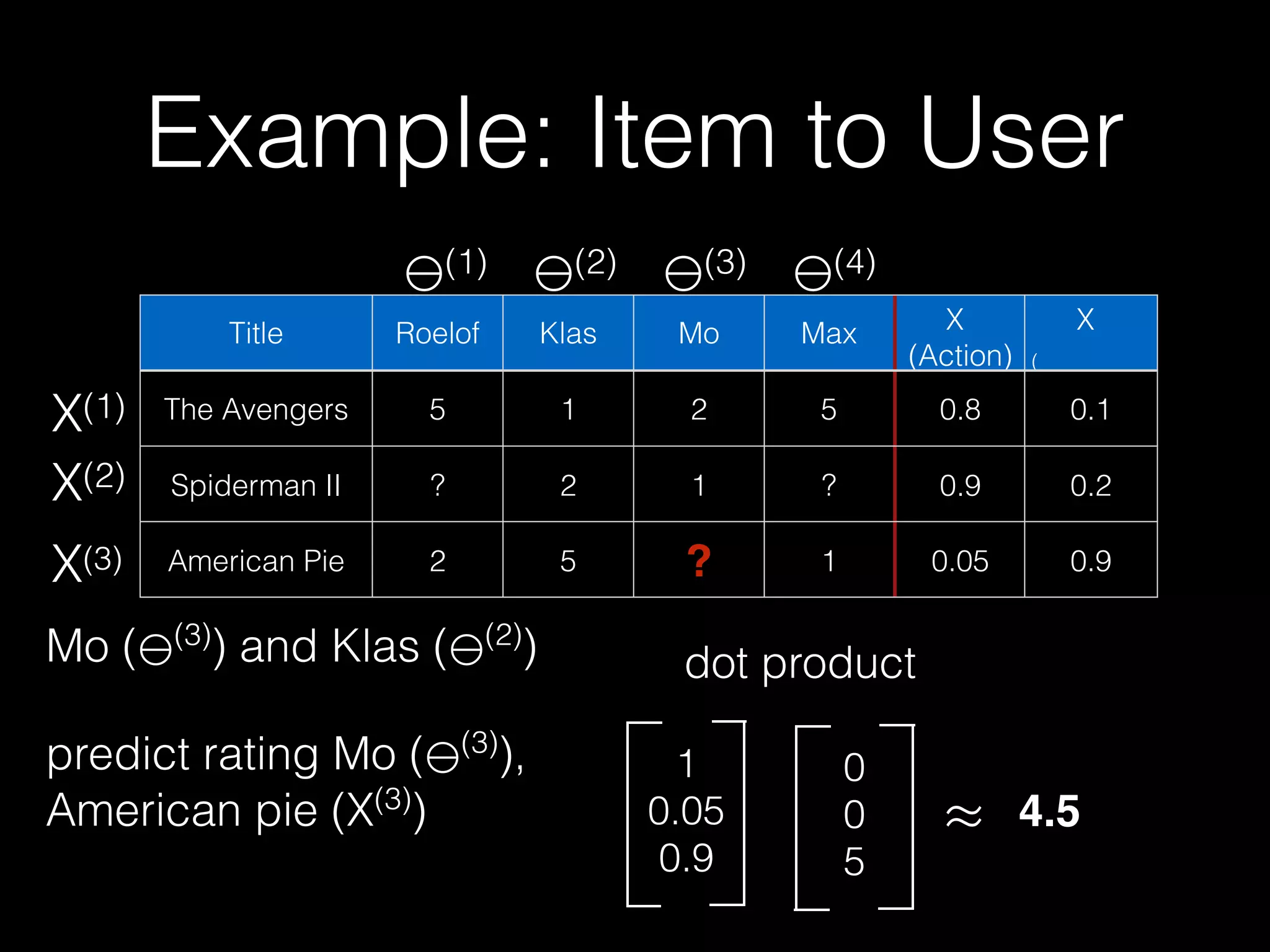
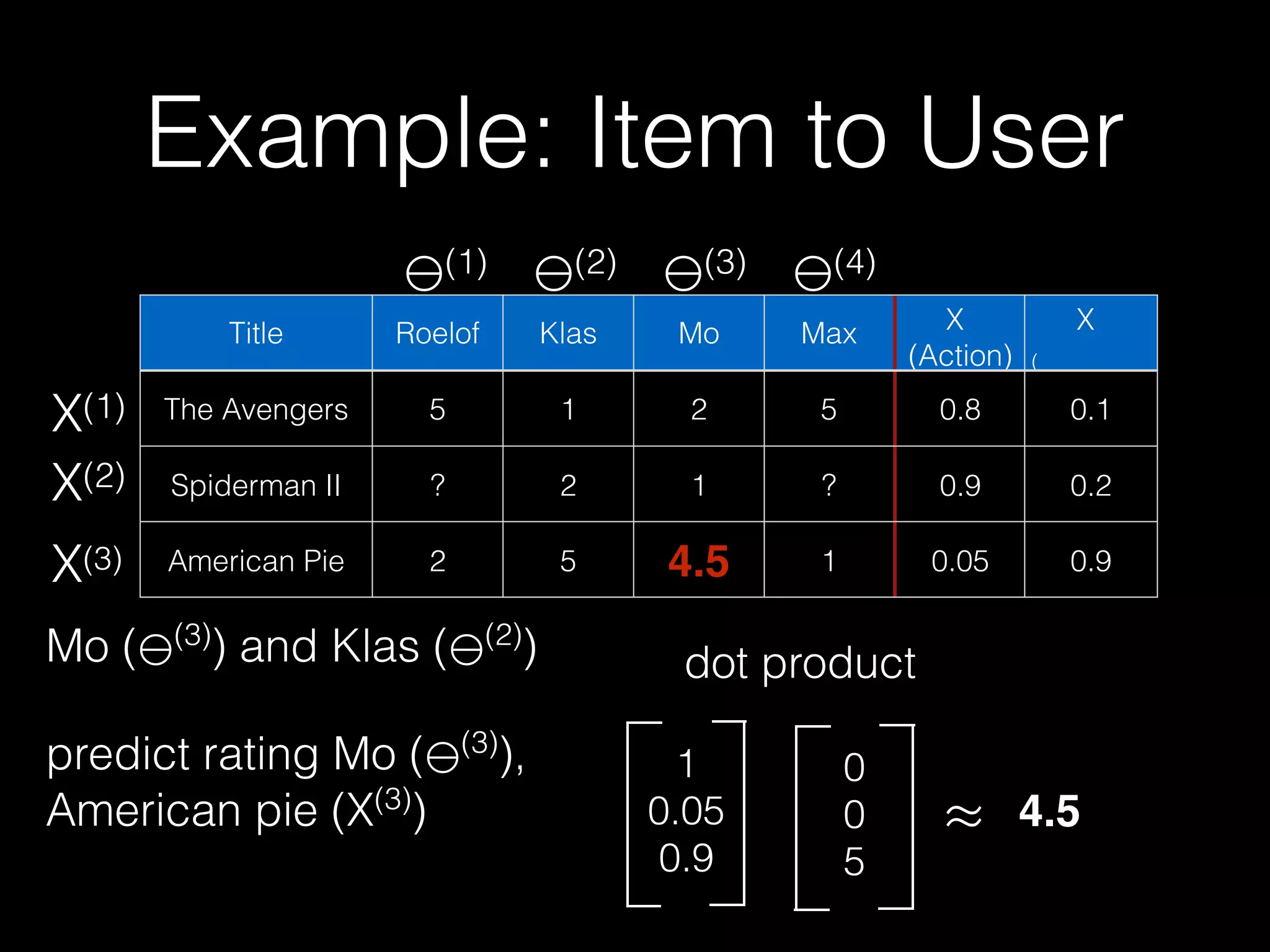
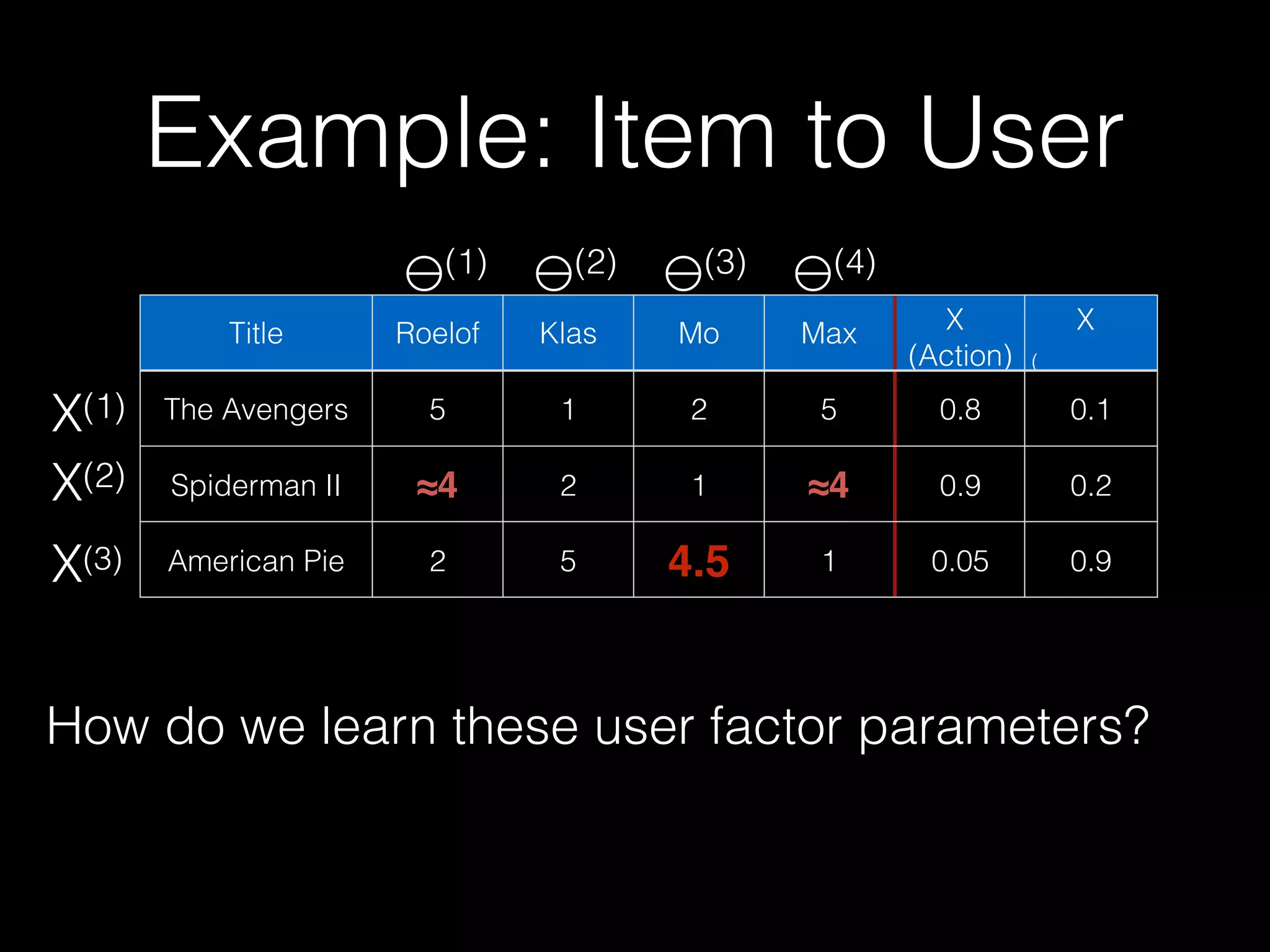





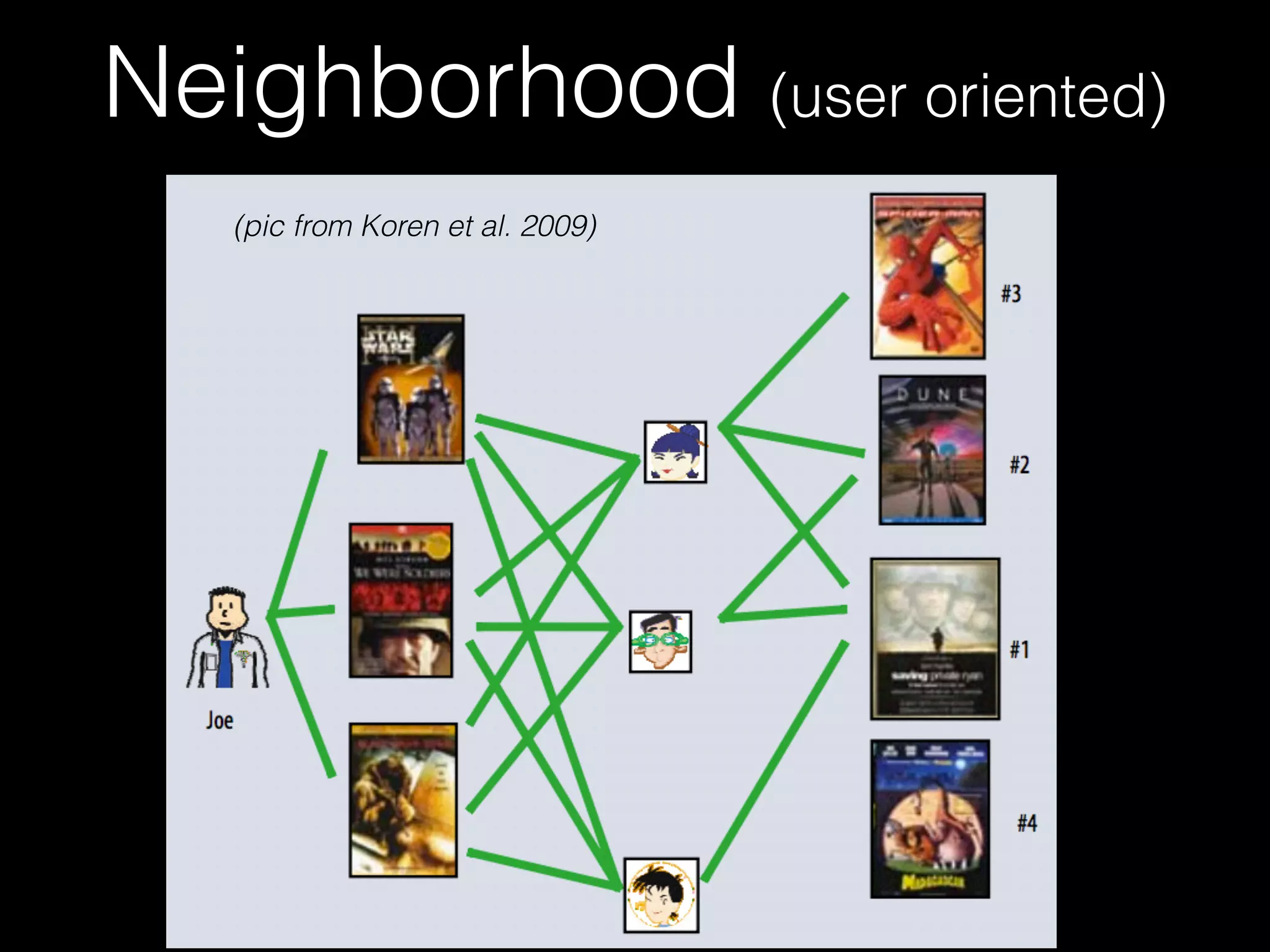
















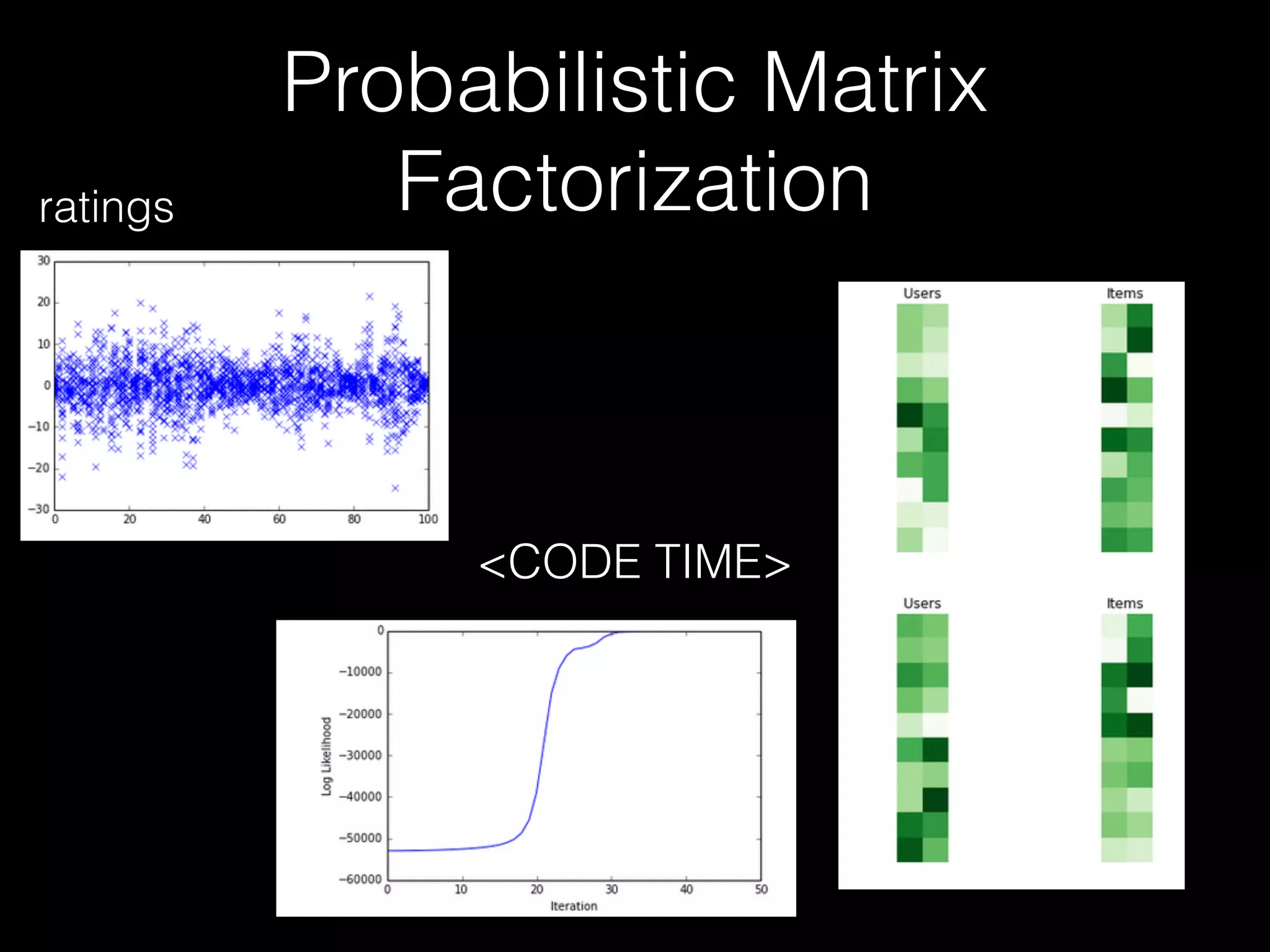
![Probabilistic Matrix
Factorization
• This could be represented by the PMF model by using three
dimensional vectors to describe each user and each movie.
• example latent vectors: • AV: [0, 0.3]
• SPII: [1, 0.3]
• AP [1, 0.3]
• SH [1, 0.3]
• Roelof: [0, 3]
• Klas: [8, 3]
• Mo [10, 3]
• Max [10, 3]
• predict rating by dot product
of user vector with the item
vector
• So predicting Klas’ rating for
Spiderman II = 8*1 + 3*0.3 =
• But descriptions of users
and movies not known
ahead of time.
• PGM discovers such latent
characteristics](https://image.slidesharecdn.com/recsysprephd2pub-140520033122-phpapp02/75/Recommender-Systems-Matrices-and-Graphs-92-2048.jpg)






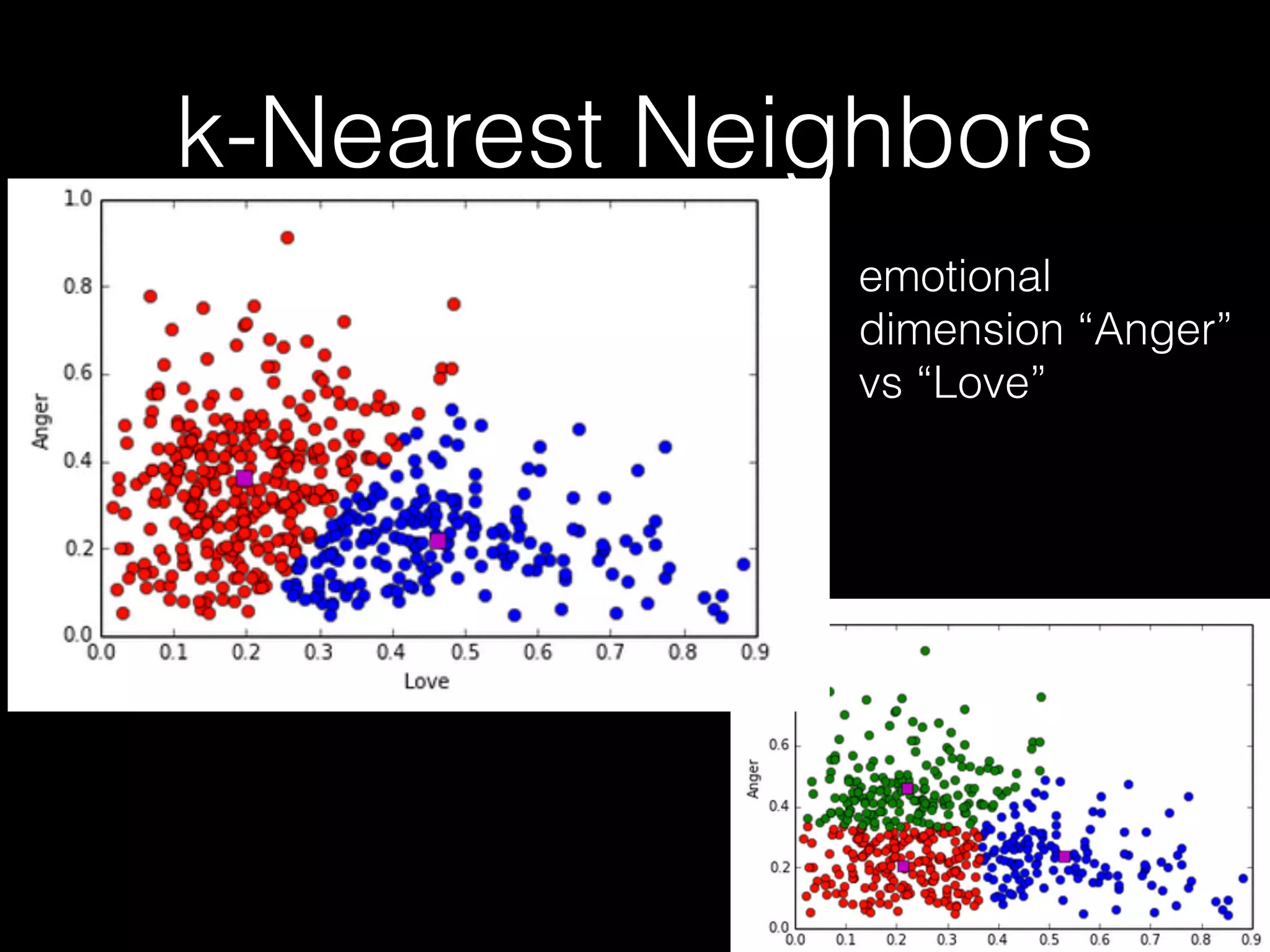
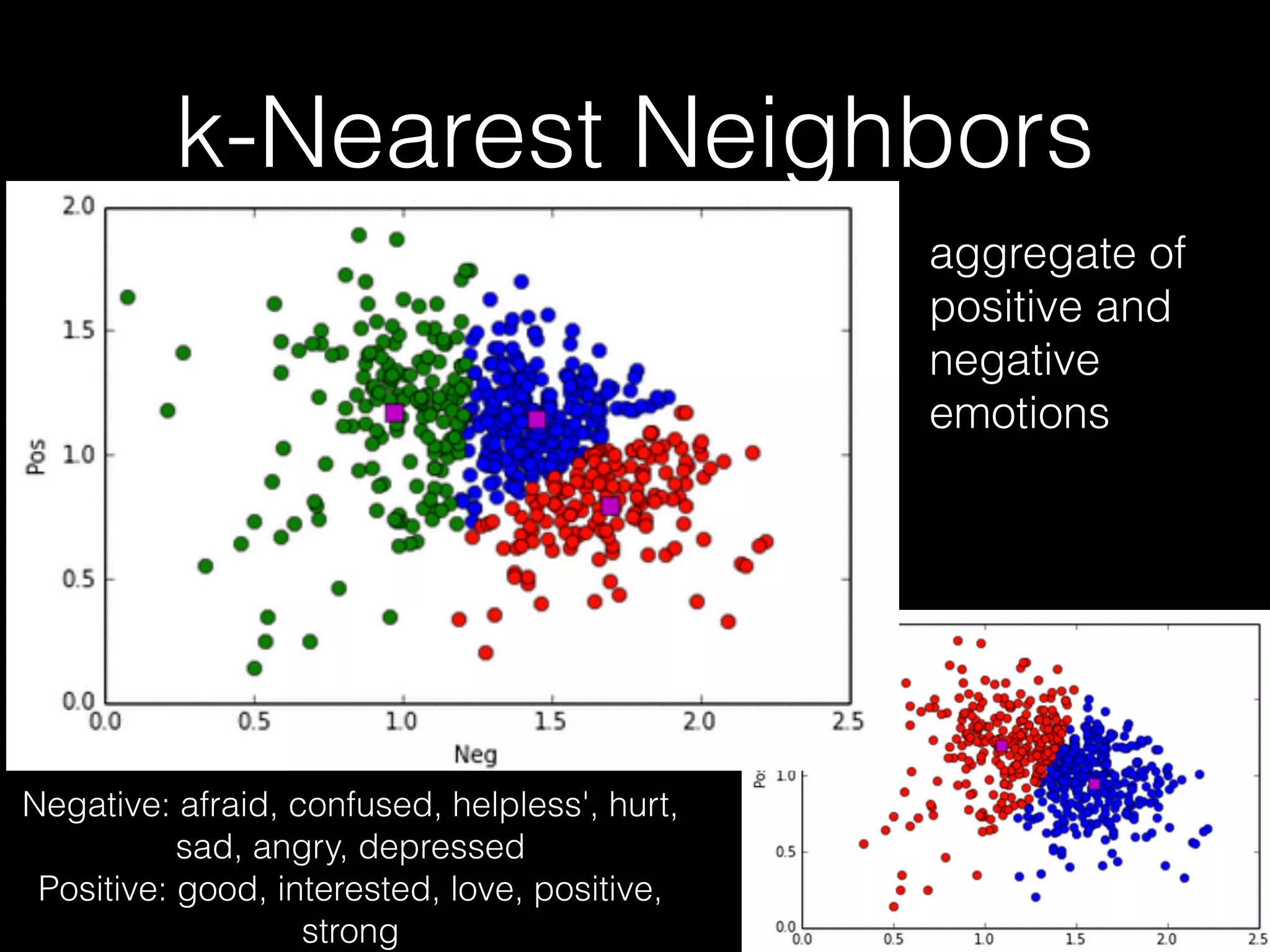









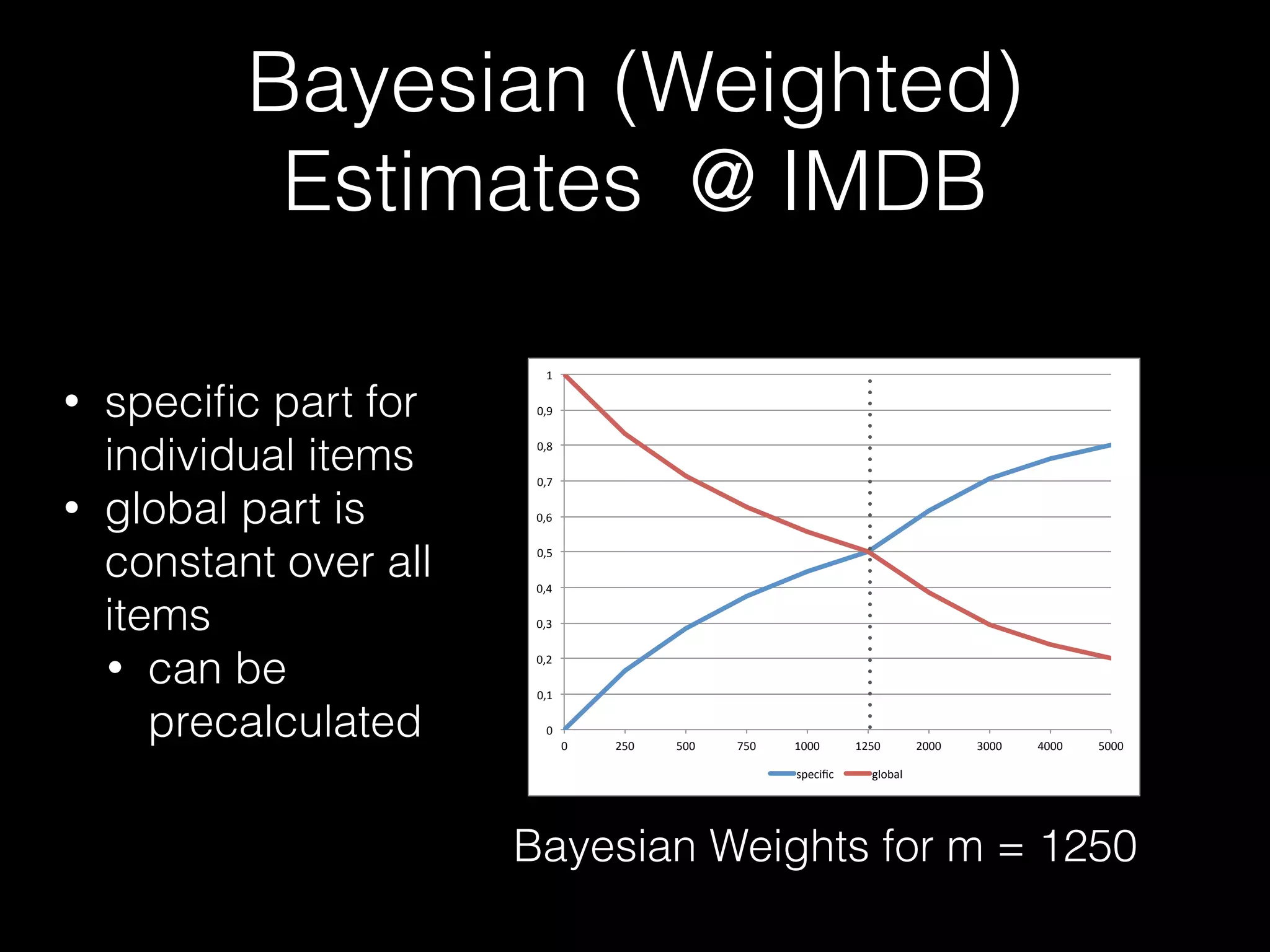
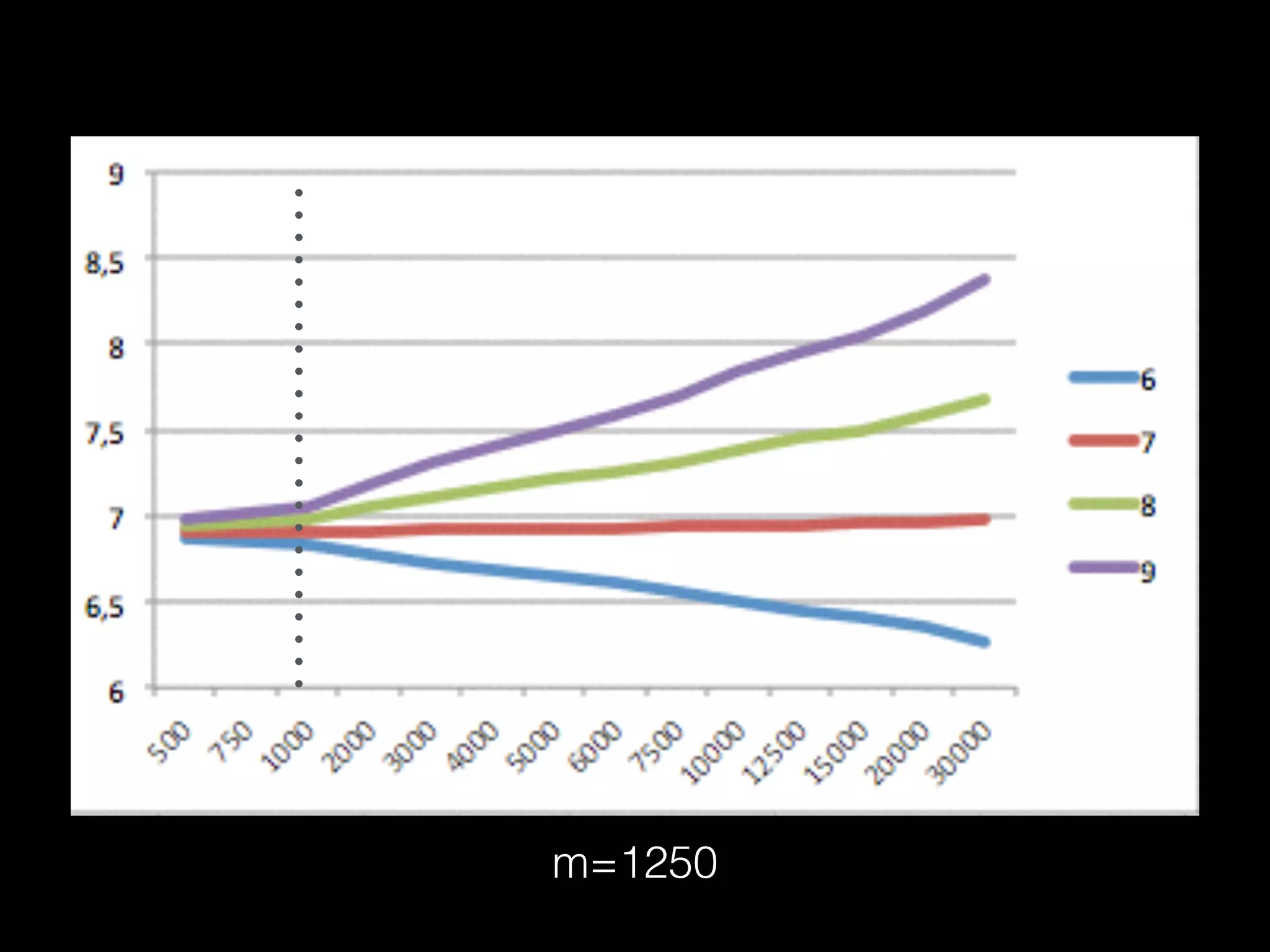






















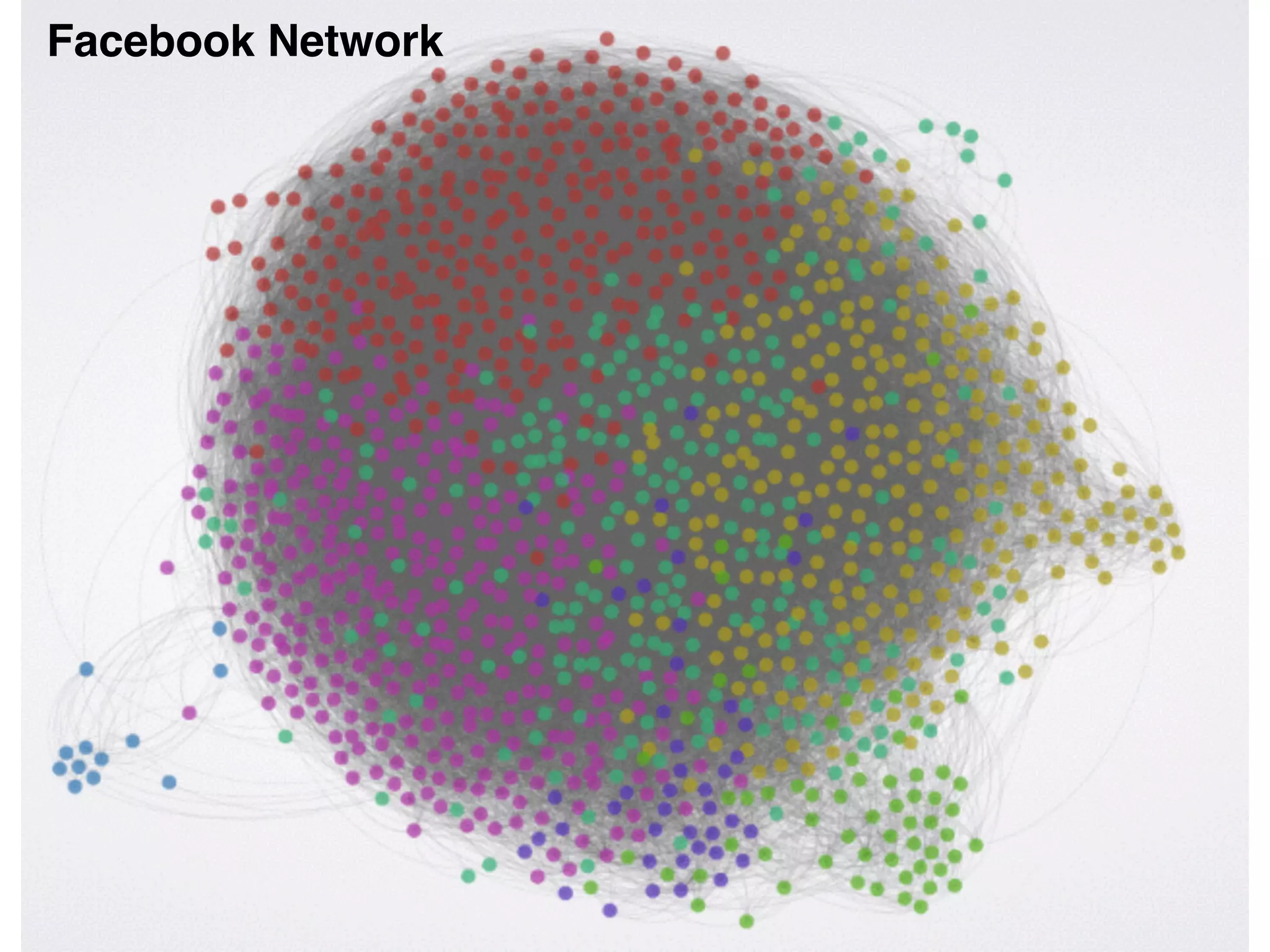
![Friend
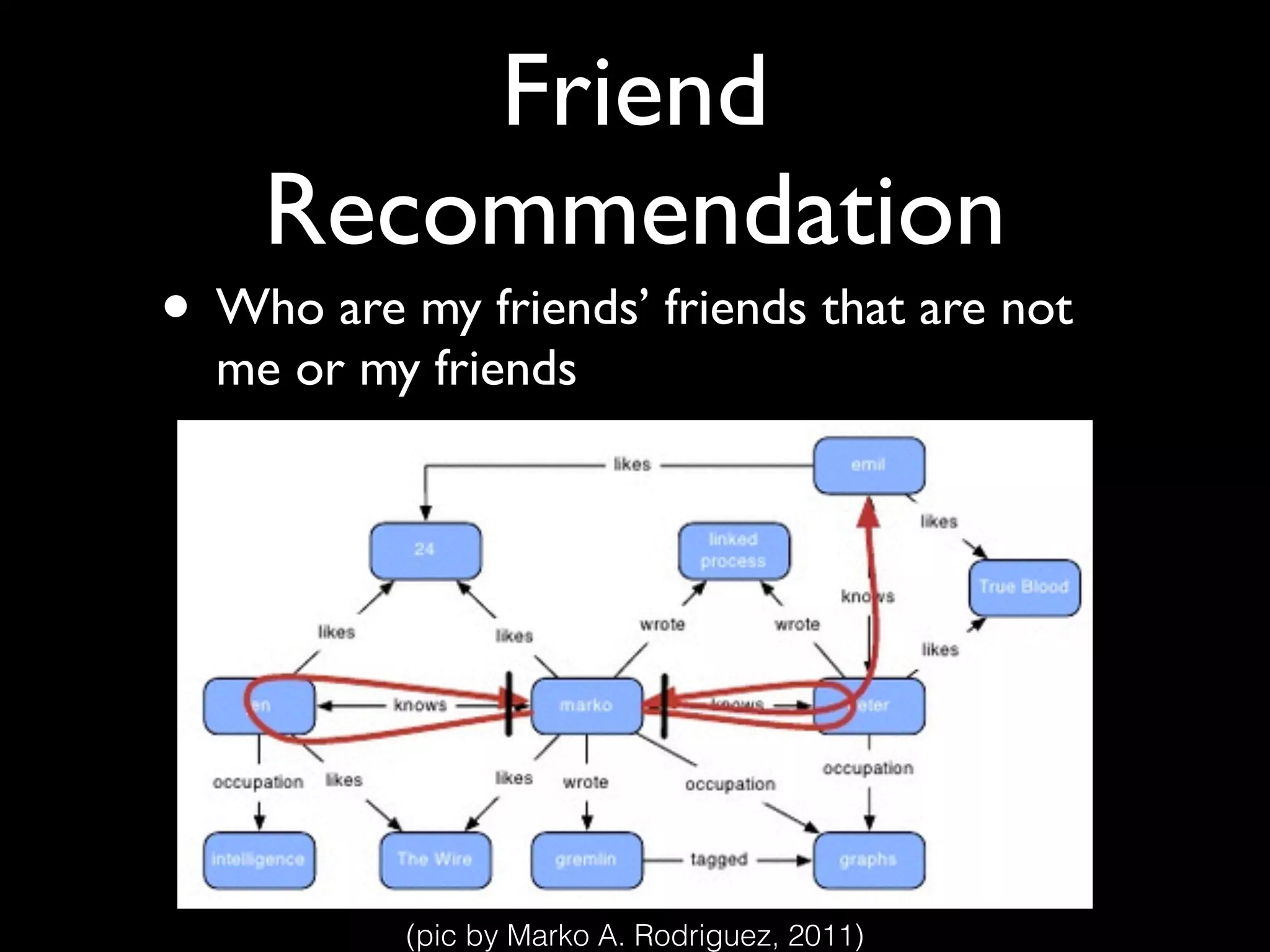
Recommendation
• Who are my friends’ friends
• Who are my friends’ friends that are not
me or my friends
G.V(‘me’).outE[knows].inV.outE.inV
G.V(‘me’).outE[knows].inV.aggregate(x).outE.
inV{!x.contains(it)}](https://image.slidesharecdn.com/recsysprephd2pub-140520033122-phpapp02/75/Recommender-Systems-Matrices-and-Graphs-147-2048.jpg)
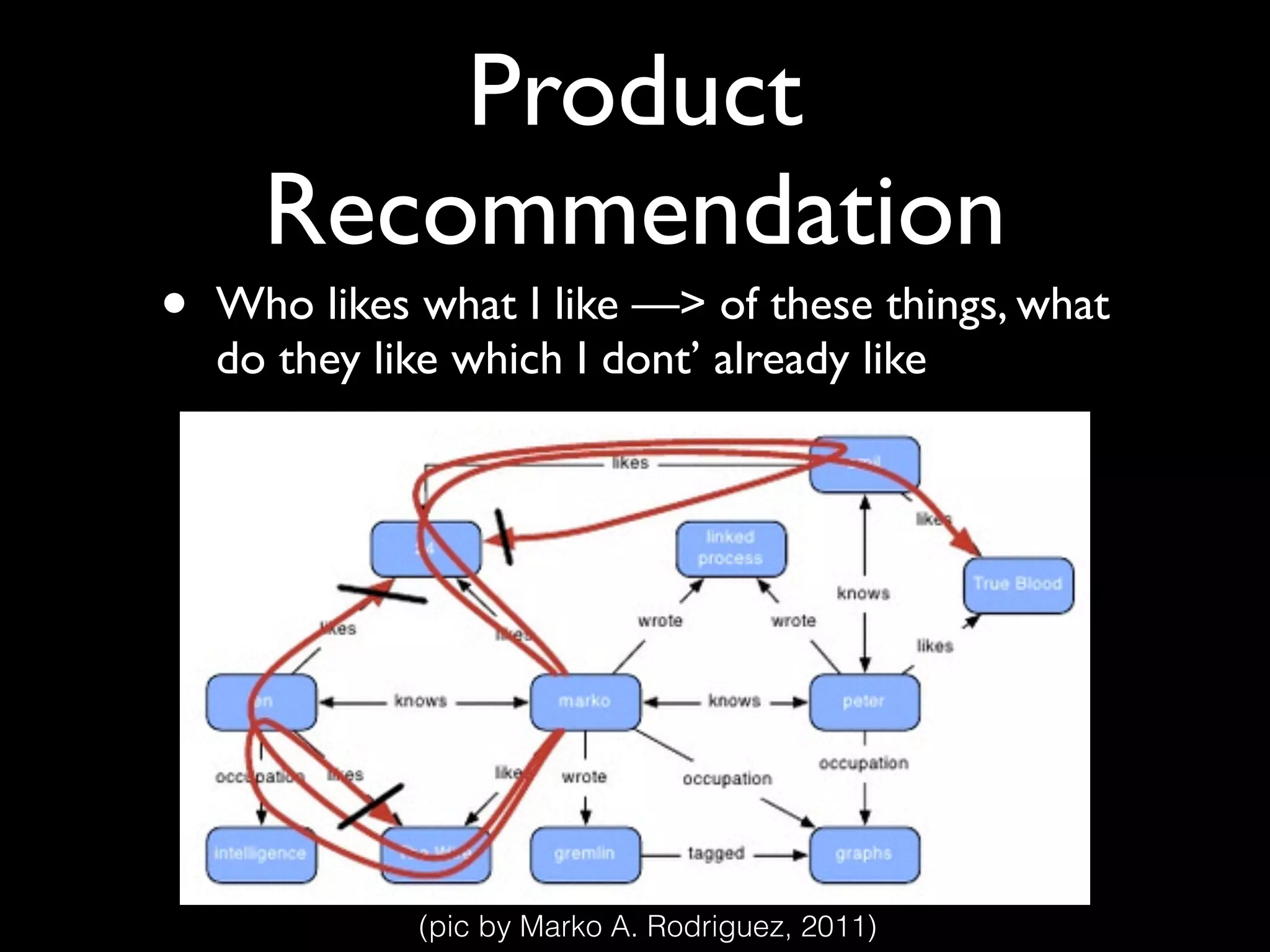
![Product
Recommendation
• Who likes what I like
• Who likes what I like —> of these things, what
do they like which I dont’ already like
• Who likes what I like —> of these things, what
do they like which I dont’ already like
G.V(‘me’).outE[likes].inV.inE[likes].outV
G.V(‘me’).outE[likes].inV.aggregate(x).inE[likes].
outV.outE[like].inV{!x.contains(it)}
G.V(‘me’).outE[likes].inV.inE[likes].outV.outE[like].inV](https://image.slidesharecdn.com/recsysprephd2pub-140520033122-phpapp02/75/Recommender-Systems-Matrices-and-Graphs-149-2048.jpg)

















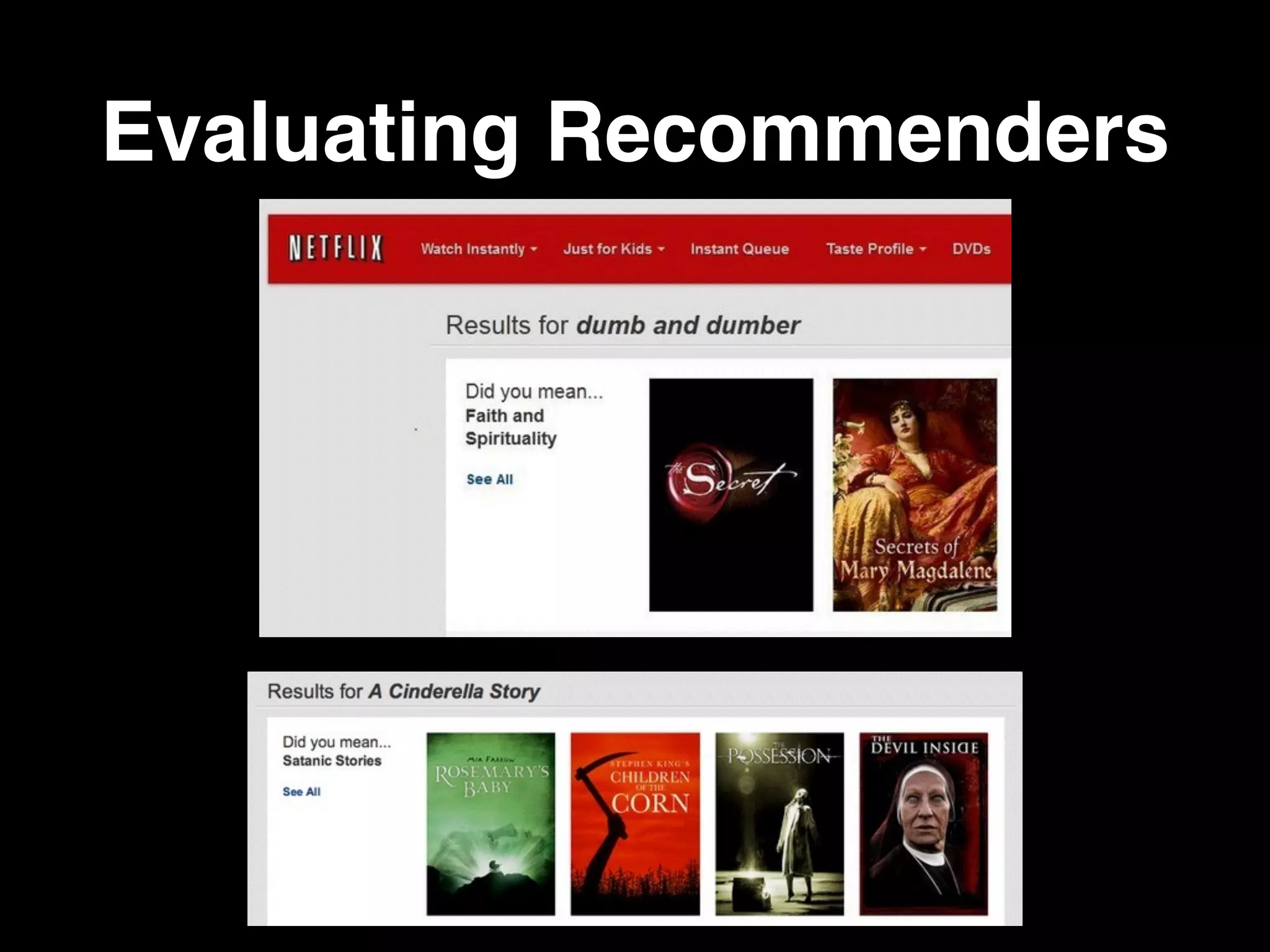
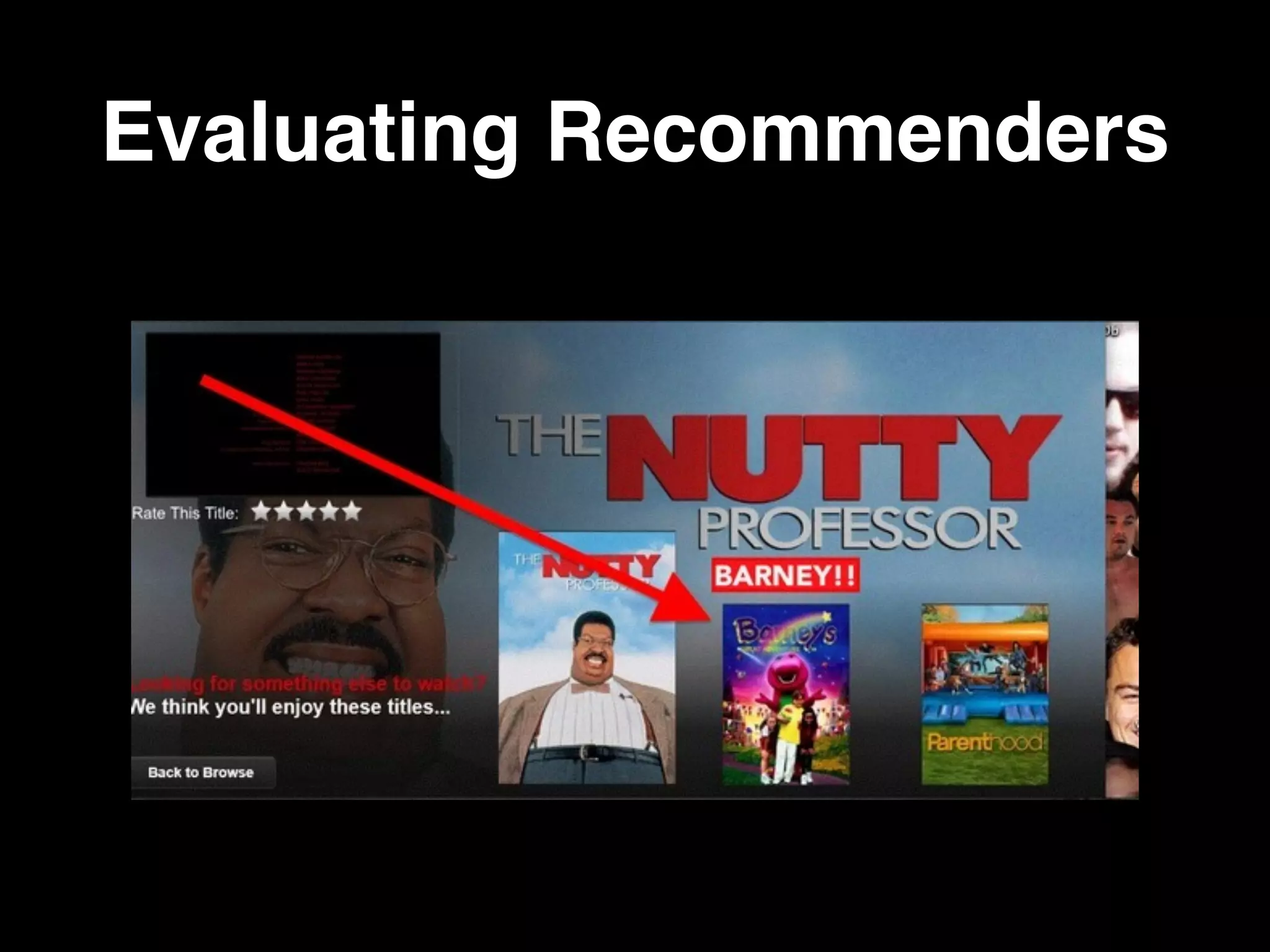
The document provides an in-depth analysis of recommender systems, outlining their algorithms, types, and applications in various domains such as movies, e-commerce, and social media. It discusses the evolution of these systems, from manual to automated techniques, and the importance of evaluation metrics like precision and recall. Key filtering methods such as collaborative, content-based, and hybrid approaches are examined, highlighting their functionality and challenges.

















![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[RIIT 2017] Identifying Grey Sheep Users By The Distribution of User Similari...](https://cdn.slidesharecdn.com/ss_thumbnails/slidegsuser-171004030338-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![bussiness communication[1].pptx work and stress](https://cdn.slidesharecdn.com/ss_thumbnails/bussinesscommunication1-251123030028-578a5e39-thumbnail.jpg?width=640&height=640&fit=bounds)
