Downloaded 1,708 times






![Challenges in (neural) IR [slide 1/3]
• Vocabulary mismatch
Q: How many people live in Sydney?
Sydney’s population is 4.9 million
[relevant, but missing ‘people’ and ‘live’]
Hundreds of people queueing for live music in Sydney
[irrelevant, and matching ‘people’ and ‘live’]
• Need to interpret words based on context (e.g., temporal)
Today Recent In older (1990s)
TREC data
query:
“uk prime minister”
Vocab mismatch:
• Worse for short texts
• Still an issue for long texts](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-10-320.jpg)
![Challenges in (neural) IR [slide 2/3]
• Q and D vary in length
• Models must handle
variable length input
• Relevant docs have
irrelevant sections
https://en.wikipedia.org/wiki/File:Size_distribution_among_Featured_Articles.png](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-11-320.jpg)
![Challenges in (neural) IR [slide 3/3]
• Need to learn Q-D relationship
that generalizes to the tail
• Unseen Q
• Unseen D
• Unseen information needs
• Unseen vocabulary
• Efficient retrieval over many
documents
• KD-Tree, LSH, inverted files, …
Figure from: Goel, Broder, Gabrilovich, and Pang. Anatomy of the long tail:
ordinary people with extraordinary tastes. WWW Conference 2010](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-12-320.jpg)








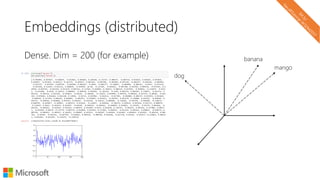





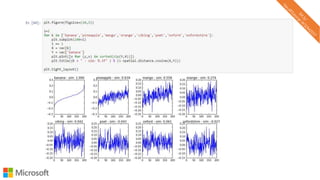
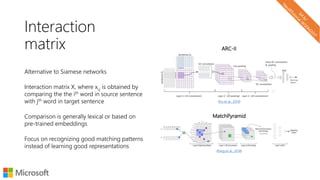
![Word analogies
with word2vec
[king] – [man] + [woman] ≈ [queen]
(Mikolov et al., 2013)](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-35-320.jpg)
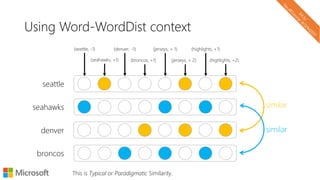
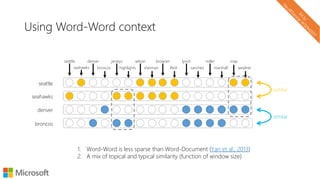
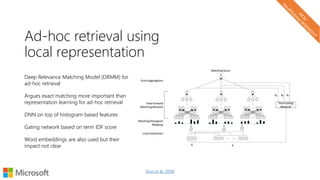
![Word analogies can work in underlying data too
seattle
seattle denver
seahawks broncos
jerseys
highlights
wilson
sherman
seahawks
denver
broncos
similar
browner
lfedi
lynch
sanchez
miller
marshall
[seahawks] – [seattle] + [Denver]
map
weather
Sparse vectors can work well for an analogy task:
Levy, Goldberg and Ramat-Gan. Linguistic Regularities in Sparse and Explicit Word Representations. CoNLL 2014](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-36-320.jpg)














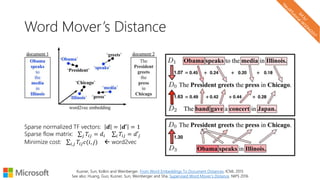
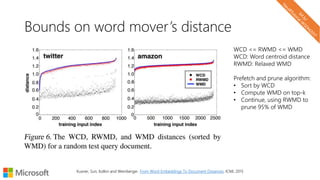
![Centroid and related techniques
• Goal: Bag of vectors Single fixed size vector
• Centroid, weighted centroid (or sum [Vulic and Moens, 2015])
• Aggregate using a Fisher Kernel
• Clinchant and Perronnin. Aggregating continuous word embeddings for information retrieval.
(ACL) Workshop on Continuous Vector Space Models and their Compositionality, 2013
• Using Fisher Kernel from Jaakkola and Haussler (1999)](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-56-320.jpg)





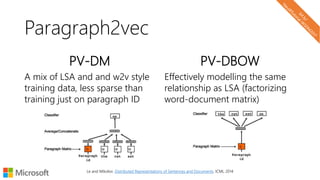
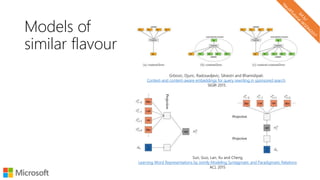




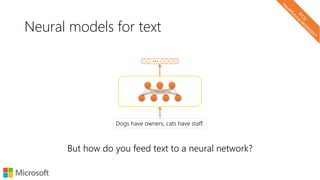
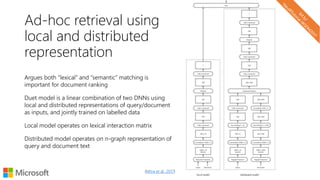
![Local representations of input text
Char-level models
d o g s h a v e o w n e r s c a t s h a v e s t a f f
one-hotvectors
concatenate
channels
[chars x channels]](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-73-320.jpg)
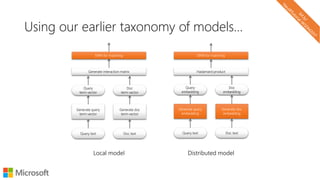
![Local representations of input text
Word-level models w/ bag-of-chars per word
d o g s h a v e o w n e r s c a t s h a v e s t a f f
one-hotvectors
concatenate
sum sum sum sum sum sum
channels
[words x channels]](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-74-320.jpg)
![# d o g s # # h a v e # # o w n e r s # # c a t s # # h a v e # # s t a f f #
Local representations of input text
Word-level models w/ bag-of-trigraphs per word
one-hotvectors
concatenate or sum
sum sum sum sum sum sum
channels
[words x channels] or [1 x channels]](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-75-320.jpg)
![Local representations of input text
Word-level models w/ pre-trained embeddings
d o g s h a v e o w n e r s c a t s h a v e s t a f f
pre-trained
embeddings
concatenate or sum
channels
[words x channels] or [1 x channels]](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-76-320.jpg)

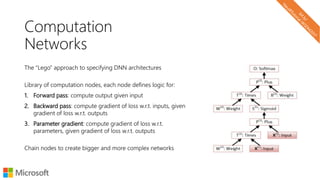
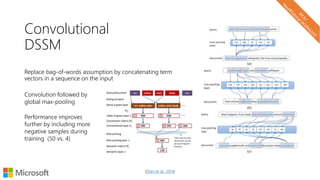
![Convolution
Move the window over the input space each time
applying the same cell over the window
A typical cell operation can be,
ℎ = 𝜎 𝑊𝑋 + 𝑏
Full Input [words x in_channels]
Cell Input [window x in_channels]
Cell Output [1 x out_channels]
Full Output [1 + (words – window) / stride x out_channels]
𝑋
ℎ output](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-78-320.jpg)
![Pooling
Move the window over the input space each time
applying an aggregate function over each dimension in
within the window
ℎ𝑗 = 𝑚𝑎𝑥𝑖∈𝑤𝑖𝑛 𝑋𝑖,𝑗 𝑜𝑟 ℎ𝑗 = 𝑎𝑣𝑔𝑖∈𝑤𝑖𝑛 𝑋𝑖,𝑗
Full Input [words x channels]
Cell Input [window x channels]
Cell Output [1 x channels]
Full Output [1 + (words – window) / stride x channels]
𝑋
ℎ outputmax -pooling average -pooling](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-79-320.jpg)
![Convolution w/
Global Pooling
Stacking a global pooling layer on top of a convolutional
layer is a common strategy for generating a fixed length
embedding for a variable length text
Full Input [words x in_channels]
Full Output [1 x out_channels]
convolutionpooling
output](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-80-320.jpg)
![Recurrent
Neural Network
Similar to a convolution layer but additional dependency
on previous hidden state
A simple cell operation shown below but others like
LSTM and GRUs are more popular in practice,
ℎ𝑖 = 𝜎 𝑊𝑋𝑖 + 𝑈ℎ𝑖−1 + 𝑏
Full Input [words x in_channels]
Cell Input [window x in_channels] + [1 x out_channels]
Cell Output [1 x out_channels]
Full Output [1 x out_channels]
𝑋𝑖
ℎ𝑖ℎ𝑖−1
output](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-81-320.jpg)
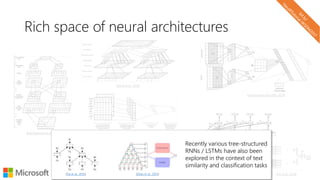
![Recursive NN
or Tree-RNN
Shared weights among all a levels of the tree
Cell can be an LSTM or as simple as
ℎ = 𝜎 𝑊𝑋 + 𝑏
Full Input [words x channels]
Cell Input [window x channels]
Cell Output [1 x channels]
Full Output [1 x channels]
output](https://image.slidesharecdn.com/neuirtutorial-wsdm2017-170206010405/85/Neural-Text-Embeddings-for-Information-Retrieval-WSDM-2017-82-320.jpg)



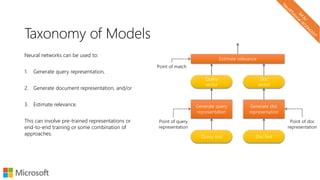
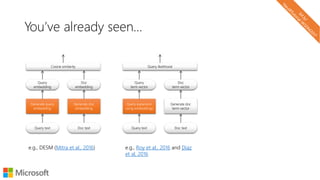
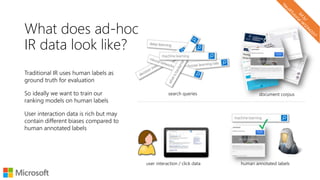

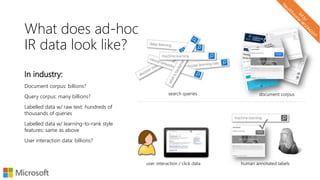



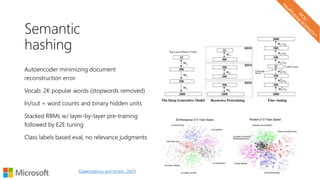

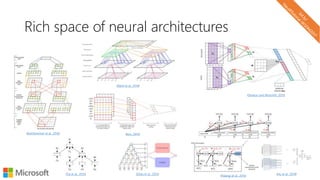
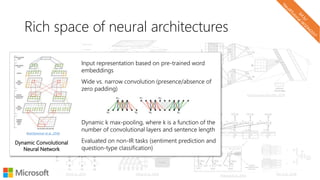
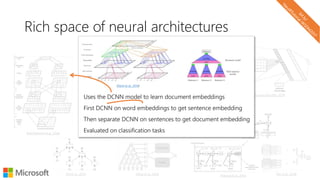
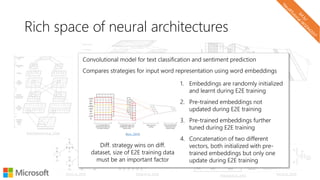
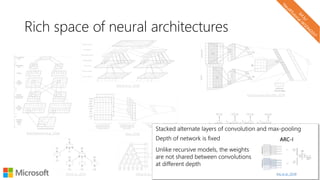
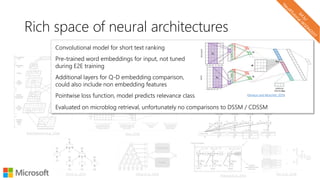
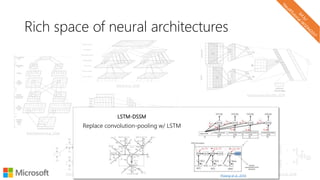






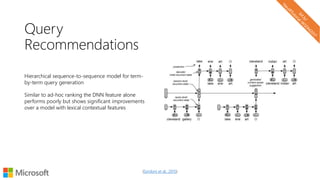




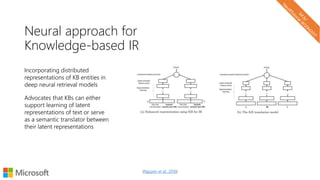
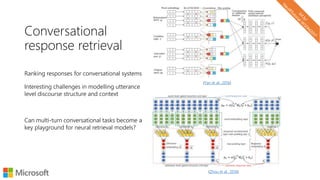




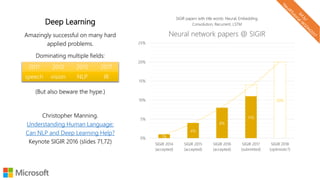
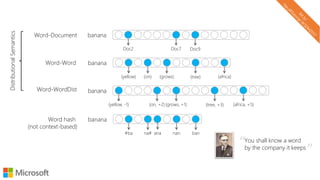
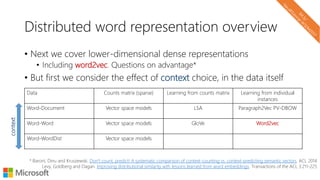
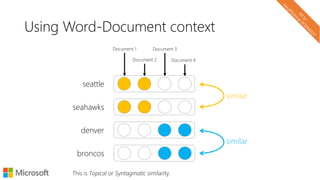
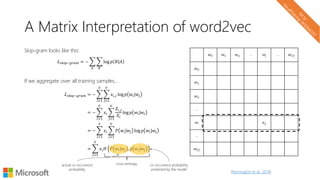
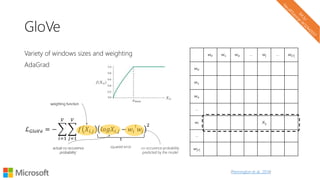
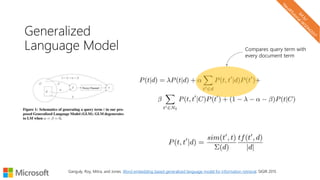
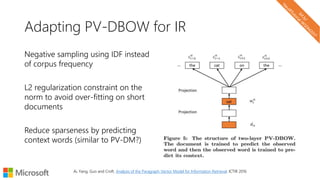
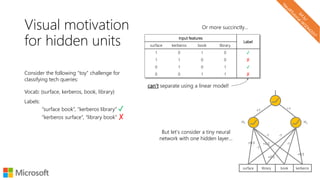
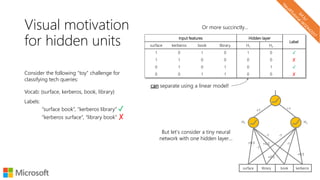
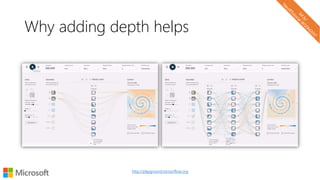
The document describes a tutorial on using neural networks for information retrieval. It discusses an agenda for the tutorial that includes fundamentals of IR, word embeddings, using word embeddings for IR, deep neural networks, and applications of neural networks to IR problems. It provides context on the increasing use of neural methods in IR applications and research.










































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
