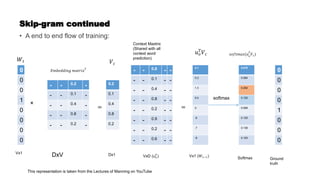
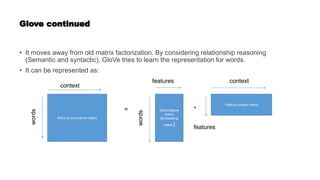
Word embeddings are numerical representations of words in a continuous vector space, crucial for natural language processing (NLP) tasks. These embeddings capture semantic relationships and can be generated through techniques like co-occurrence matrices, dimensionality reduction, and neural networks. Popular models include word2vec and GloVe, each with representation approaches that impact context understanding and embedding efficiency.



![Vector space model continued
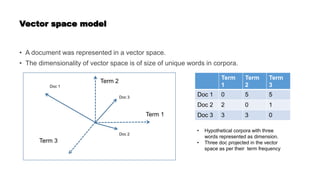
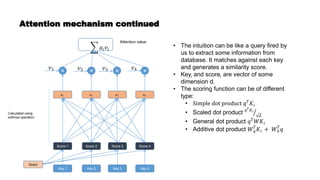
• The document got a numerical vector representation in a vector space represented by words.
• E.g.
• Doc 1 -> [0, 5, 5]
• Doc 2 -> [2, 0, 1]
• This representation is sparse in nature. Because, in real life scenario the dimensionality of a corpus
shoots up to millions.
• It is based on term frequency.
• TF-IDF normalization is applied to reduce the weightage of frequent words like ‘the’, ‘are’ , and etc.
• One-hot encoding is a similar technique to represent a sentence/document in vector space.
• This representation gather limited information and fails to capture the context of the word.](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-5-320.jpg)
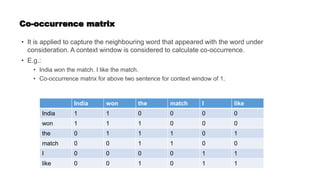

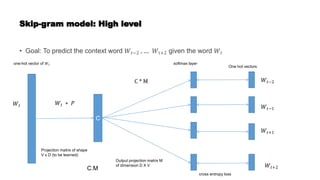
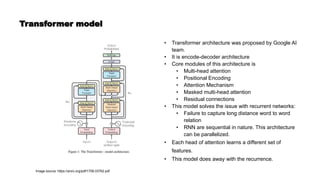
![Prediction based word embeddings
• It is a method to learn dense representation of word from a very high dimensional
representation.
• It is a modular representation, where a sparse vector is fed to generate a dense
representation
Word
Word
embedding
Model
One hot encoded representation - India
= [0, 1, 0, .... 0]
[0, 1, 0, .... 0]
V(India) = [0.1, 2.3, -2.1, ...., 0.1]](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-8-320.jpg)























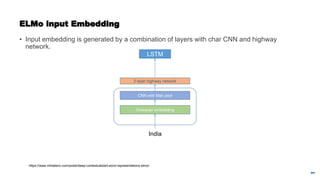
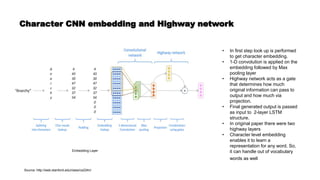
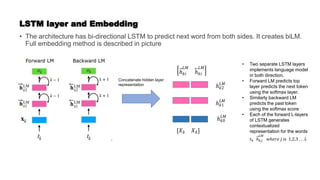


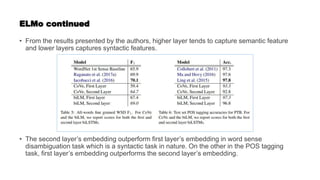





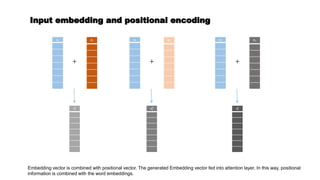
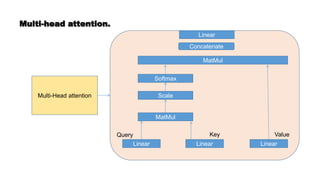
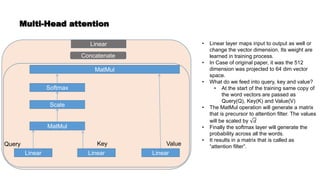




![Getting back to BERT
• Proposed by Devlin et.al. in 2019.
• It is an encoder based model.
• It is based on the transformer architecture that we discussed in previous slides.
• It has only the encoder stack from the transformer architecture.
• It is a unsupervised or semi-supervised pre-trained model, fine tuned for a specific task
like Q&A, conversational AI etc
• It is sub-word model comprises of 30000 vocabulary set. BERT tokenizer will tokenize the
words. So, representation of the tokenized word may not be similar to what we have
passed as input.
• e.g: Word “embeddings” is tokenized into [‘em’, ‘##bed’, ‘##ding’, ‘##s’]
• This approach helps to address out of vocabulary words as well.
• There are two most common architecture pre-trained models are: 𝐵𝐸𝑅𝑇𝑏𝑎𝑠𝑒, 𝐵𝐸𝑅𝑇𝑙𝑎𝑟𝑔𝑒.
• 𝐵𝐸𝑅𝑇𝑏𝑎𝑠𝑒 has 12 stacked encoders and 𝐵𝐸𝑅𝑇𝑙𝑎𝑟𝑔𝑒 has 24 stacked encoders.](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-58-320.jpg)
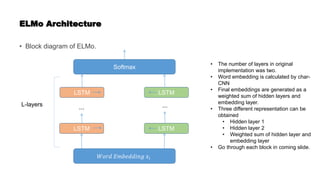
![BERT Continued
• The base version has 12 attention heads and ‘large’ version has 16 attention heads.
• The original configuration described in the paper had 6 encoder layers and 8 attention
heads. This leads to a 512 dimension representation.
• How to collect the representation from BERT?
• BERT uses two special token [CLS] and [SEP].
• [CLS] will always be the first token of the input.
• [SEP] represents the sentence segmentation.
• We need to provide the segment id as well in the input.
• Similar to original transformer model, the encoded embeddings are being passed to
subsequent encoders.
• Each of the position will output a vector representation for token of size 768 for BERTbase
and 1024 for the large model](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-59-320.jpg)
![BERT Continued
• For the classification task, we only focus on the embedding of [CLS] token.
• What would be the representation for other task:
• There are several variants of the embedding collection.
• Considering the 𝐵𝐸𝑅𝑇𝑏𝑎𝑠𝑒 with 12 encoder layer will generate 12 + 1 embeddings. One for the
input layer.
• Which layer should we use: All or some?
• There are several experiments have been performed. The best performance can be obtained by
concatenating the last 4 layer’s representation
• Next best representative would be an average of last 4 layer’s representation.
• Each layer learns different features. So, pooling strategy would be dependent upon the
specific NLP task. The above two suggestions are based on the performance on NER
tagging task.](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-60-320.jpg)

![BERT pre-training
• BERT is pretrained using two methods:
• Masked LM model:
• Unlike the masking that we discussed in Transformer architecture. In this case, some
random words are replaced with a special token [MASK ]. Approximately 15% of all the
sub-word tokens.
• Now, the prediction can be defined as a language model, given the left and right context
𝑃(𝑡𝑖|𝑡1, 𝑡2, . . , 𝑡𝑖−1, 𝑡𝑖+1, . . . , 𝑡𝑛)
• Masking strategy are further divided into three parts:
• 80% instances it is [MASK] token
• 10% times it is a random words
• 10% time there is no change](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-62-320.jpg)







![RoBERTa
• It was proposed by Facebook AI team.
• It is a training strategy to learn a better representation compare to BERT.
• Two important points that was compared to the original pre-training.
• Static masking vs dynamic masking: In original paper, [MASK] token was statically changed
before training. In this work, the data was duplicated 10 times so that different masking pattern
can be observed several times in same context. This did not improve the result.
• Training with higher batch size compared to original pre training lead to a better accuracy.
• This model dropped the next sentence prediction objective as compared to original BERT.](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-70-320.jpg)



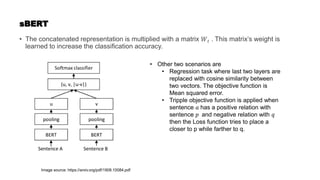
![sBERT training
• Model is trained with different hyper parameter and adopted strategies:
• Pooling strategy:
• In this case they tried to pool BERT embedding for sentence representation using three strategies -
MAX, MEAN and [CLS]
• MEAN shows the best performance.
• For classification task the vectors 𝑃 𝑎𝑛𝑃 𝑃 were concatenated in different ways. But they
achieved the best performance when |𝑃 − 𝑃| was concatenated with 𝑃 𝑎𝑛𝑃 𝑃.
• Observation:
• The need of fine tuning is required and task specific.
• Transfer learning of BERT can be used. This is fine tuning of BERT for a specific task.](https://image.slidesharecdn.com/wordembedding1-210510020848/85/Word-embedding-75-320.jpg)




















































![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)














