Download as PDF, PPTX






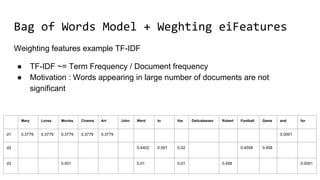





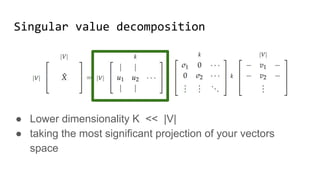




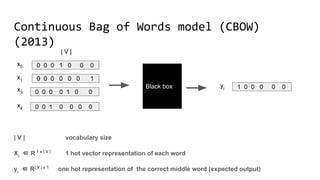
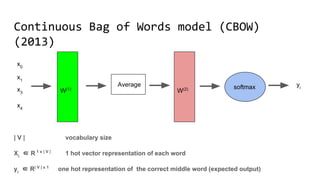
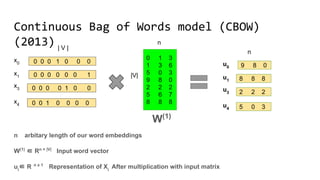
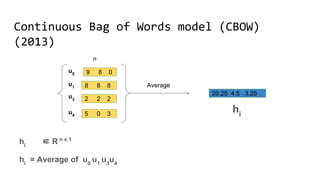
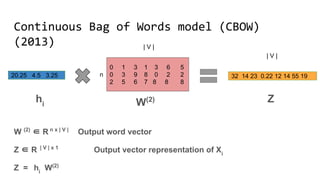











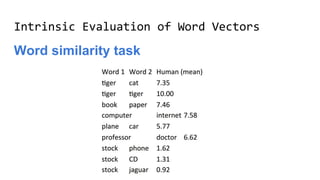
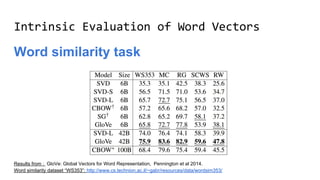


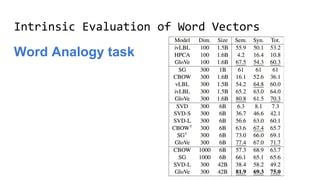

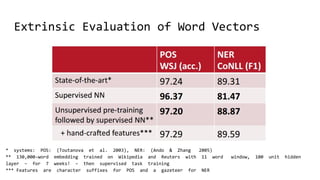


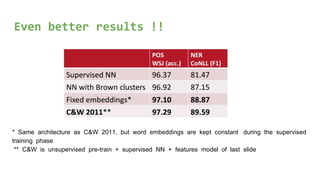








The document discusses the importance of word embeddings in natural language processing, highlighting various models such as Continuous Bag of Words (CBOW) and GloVe for representing words in a high-dimensional vector space. It addresses the challenges of conventional representations, including high dimensionality and sparsity, and introduces methods like dimensionality reduction and evaluation metrics to assess the quality of word vectors. Additionally, the document references various studies and resources for further learning in the field of deep learning and NLP.


































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)
