Downloaded 579 times








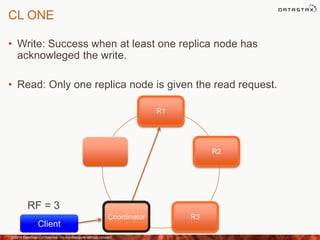
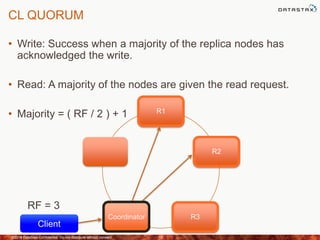
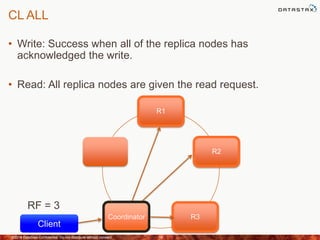
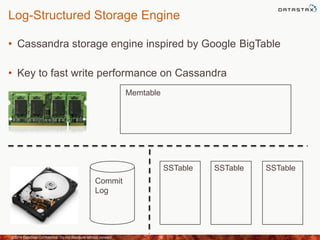

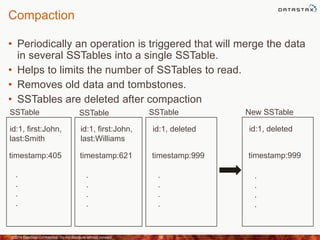




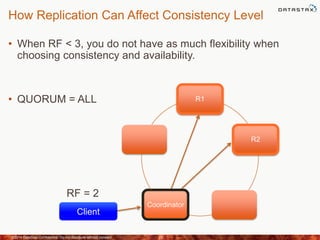



















This document discusses how to size a Cassandra cluster based on replication factor, data size, and performance needs. It describes that replication factor, data size, data velocity, and hardware considerations like CPU, memory, and disk type should all be examined to determine the appropriate number of nodes. The goal is to have enough nodes to store data, achieve target throughput levels, and maintain performance and availability even if nodes fail.






















































































