Downloaded 12 times








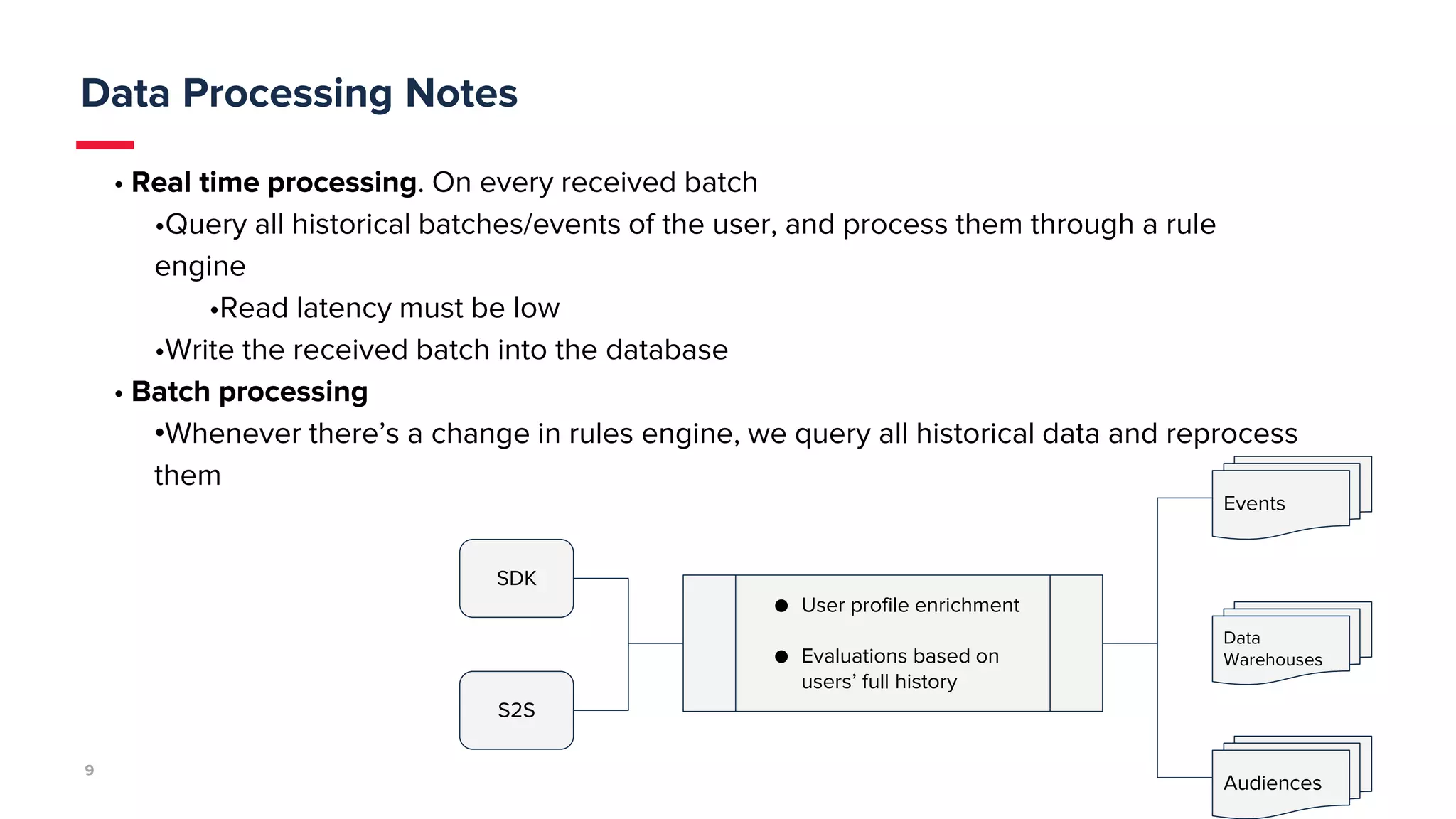


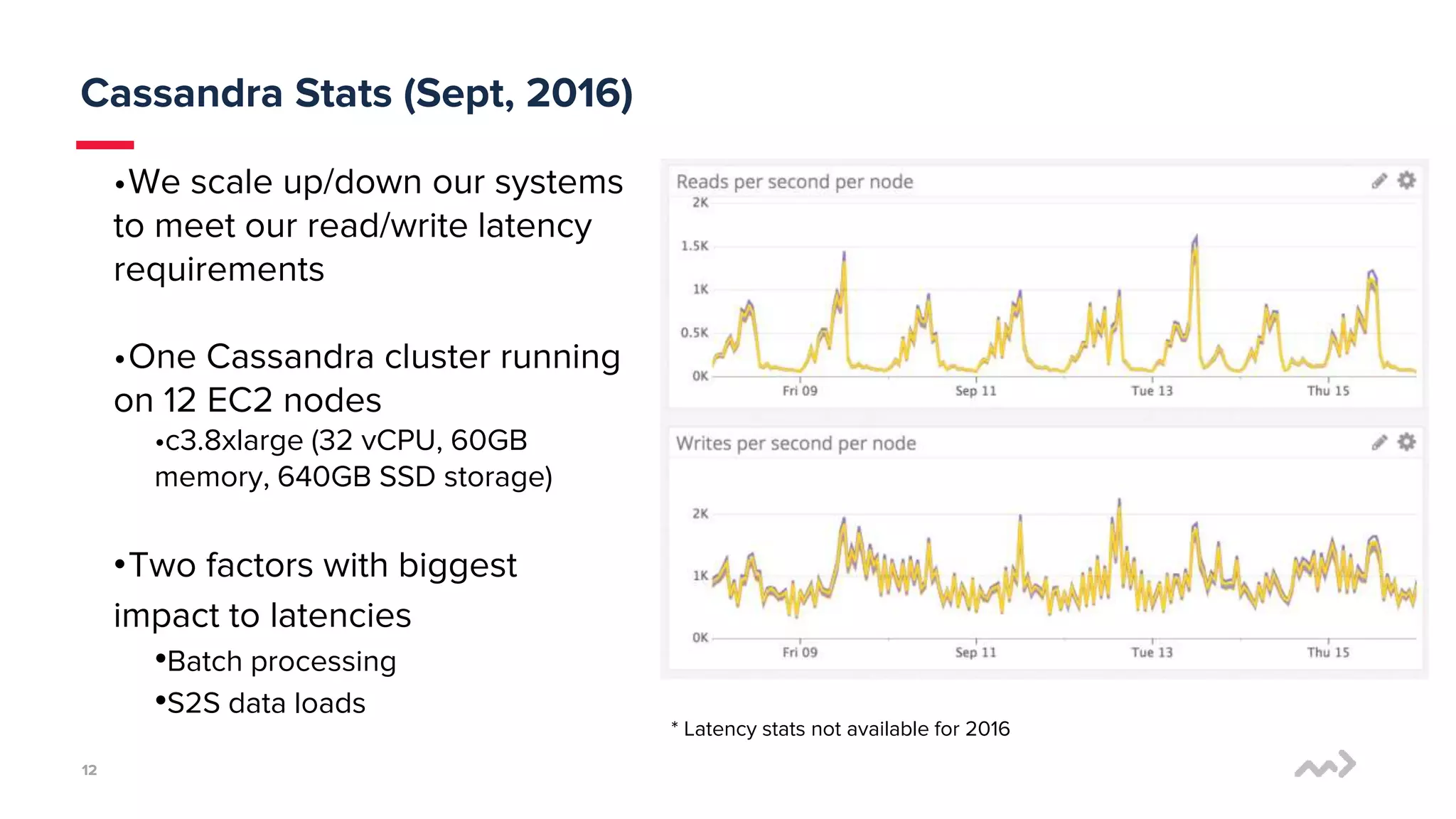
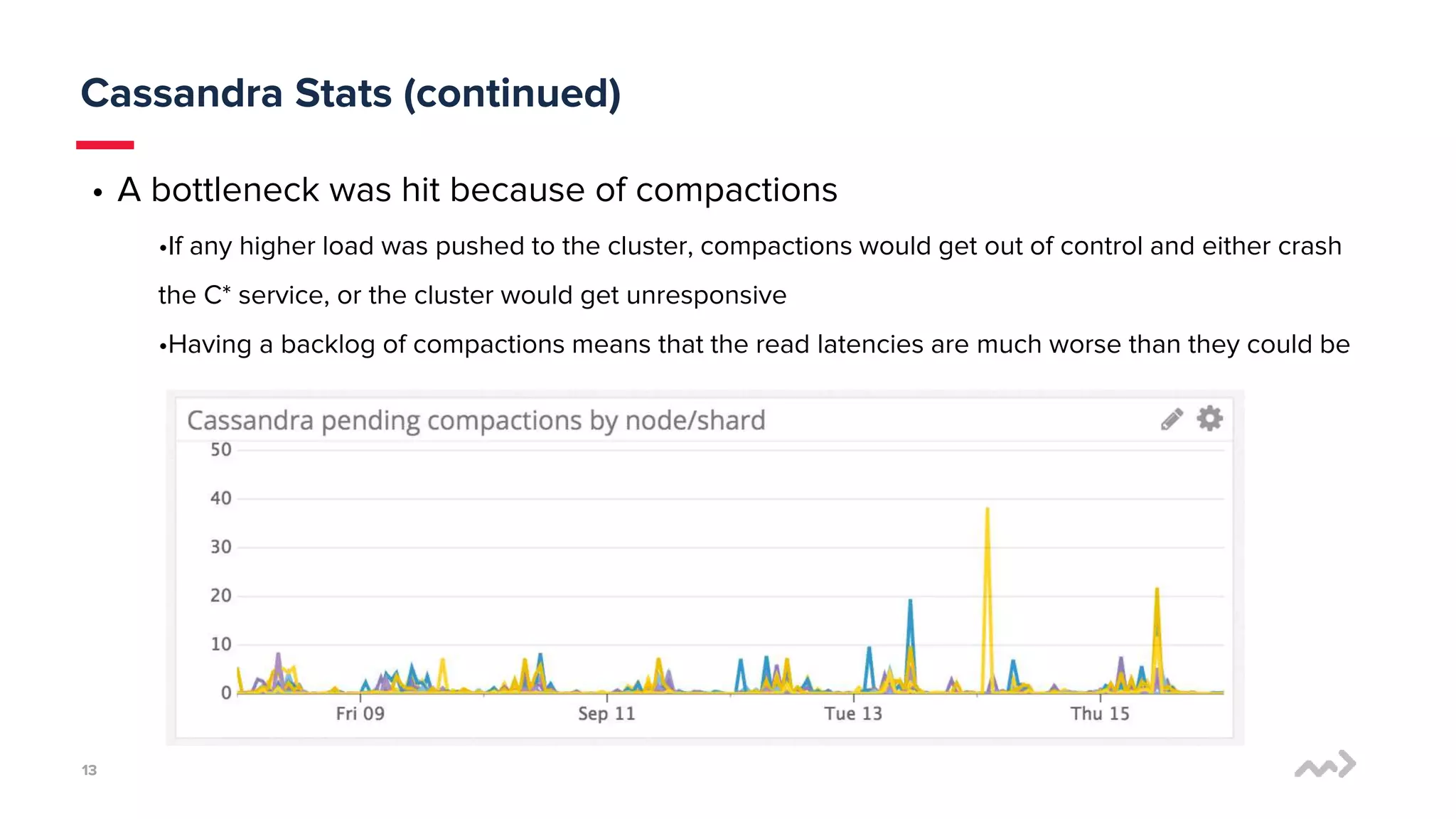

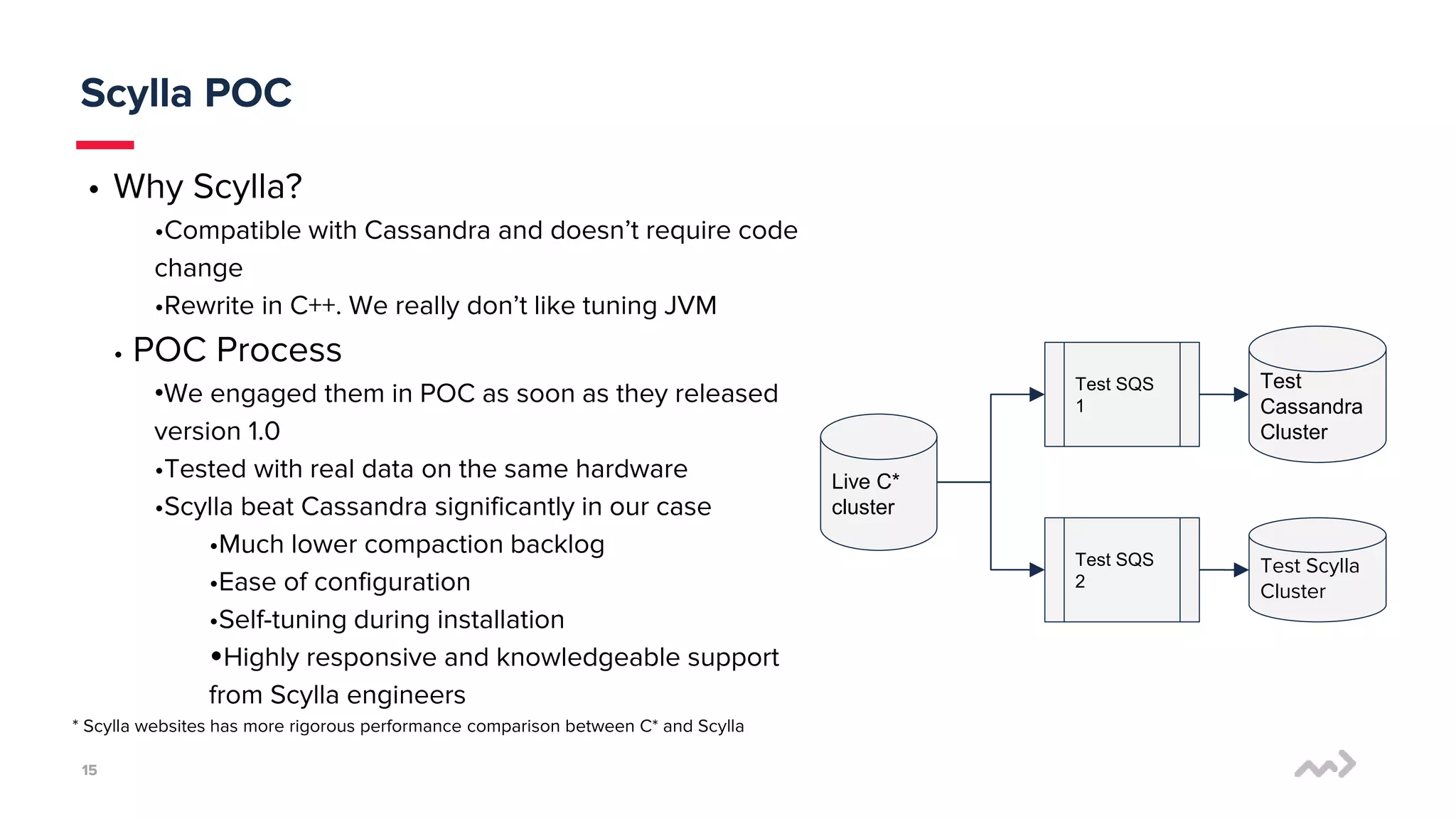


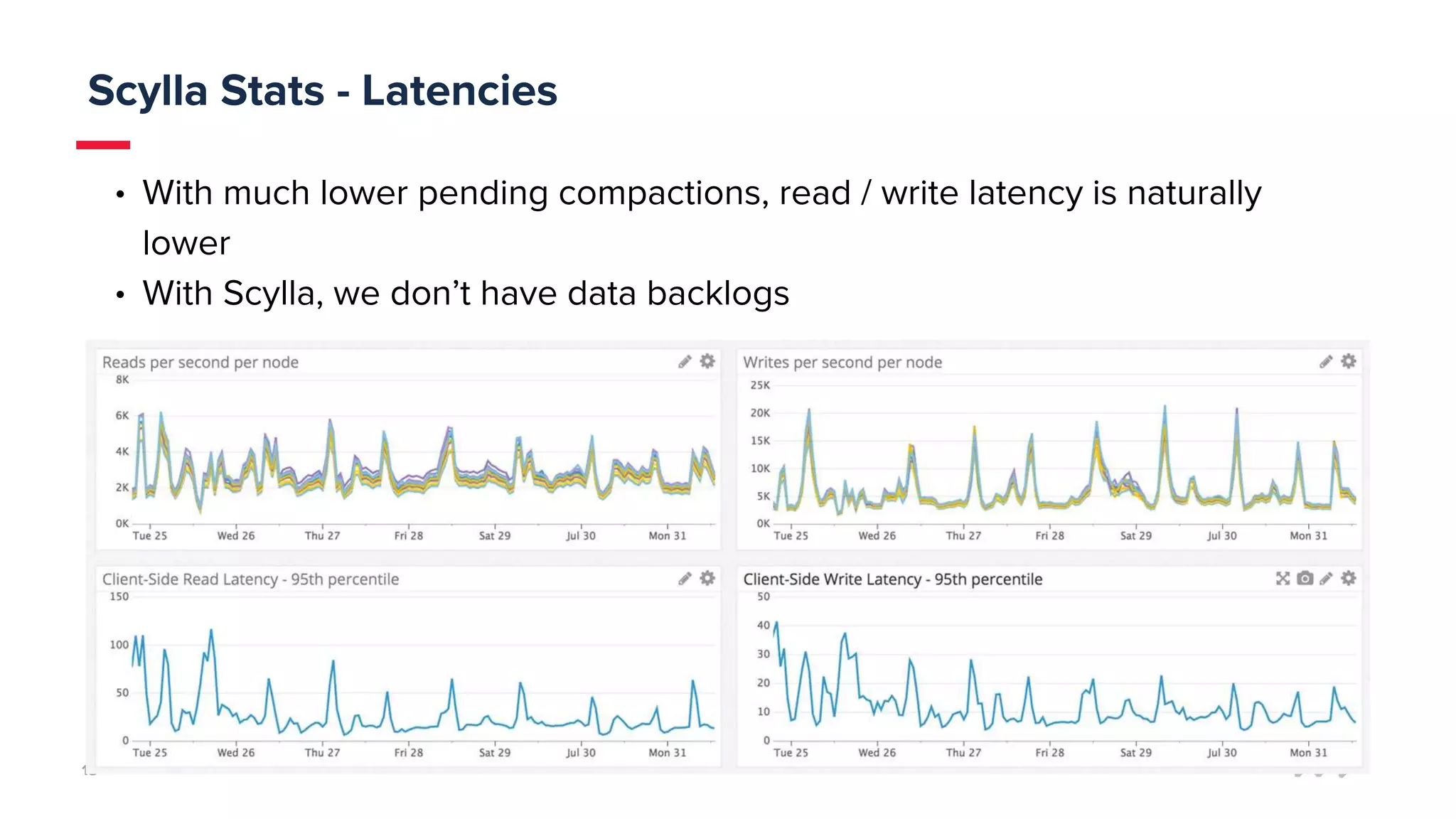






mParticle processes 50 billion monthly messages and needed a data store that provides full availability and performance. They previously used Cassandra but faced issues with high latency, complicated tuning, and backlogs of up to 20 hours. They tested Scylla and found it provided significantly lower latency and compaction backlogs with minimal tuning needed. Scylla also offered knowledgeable support. mParticle migrated their data from Cassandra to Scylla, which immediately kept up with their data loads with little to no backlog.











































































































