Downloaded 55 times




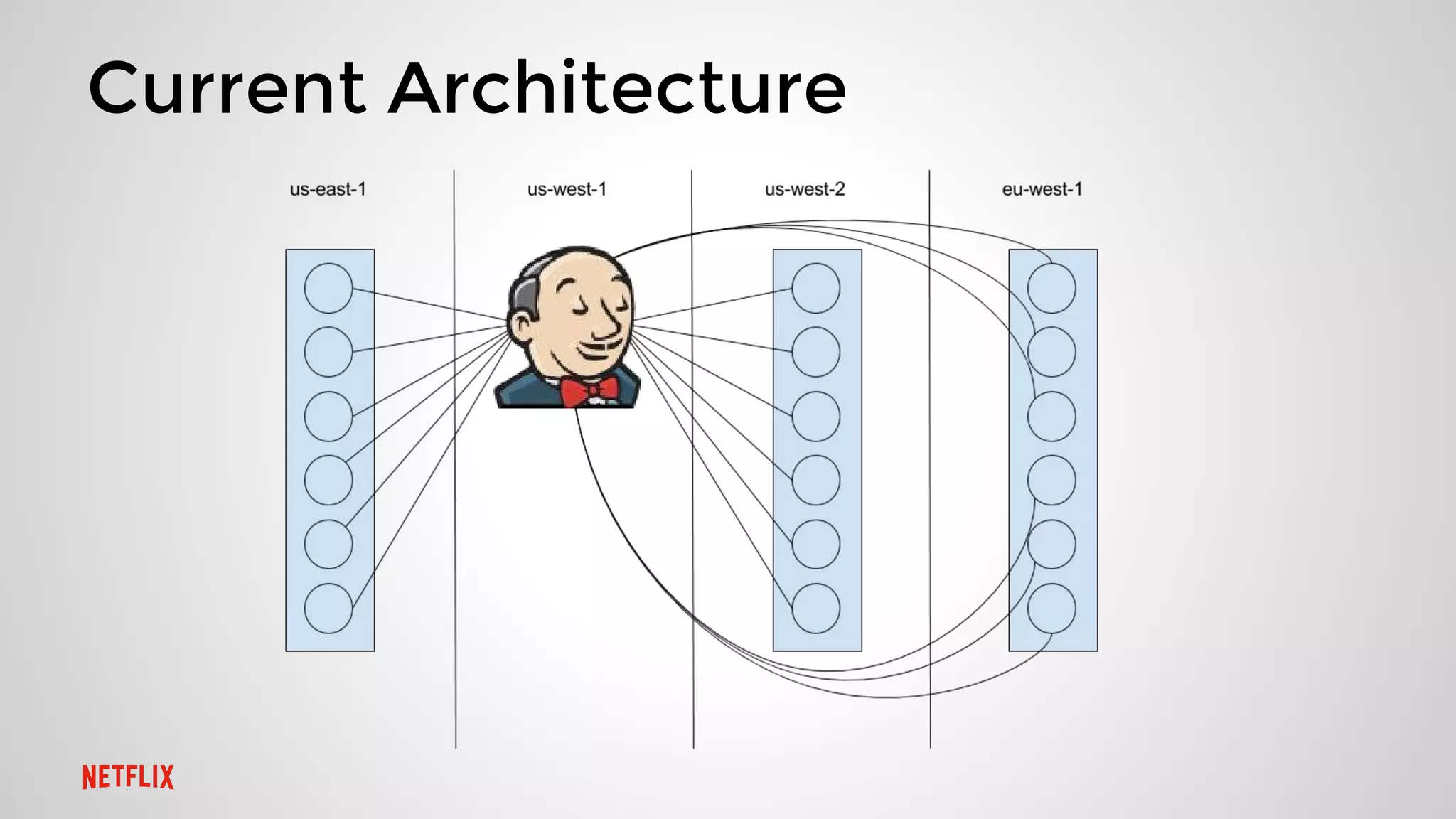


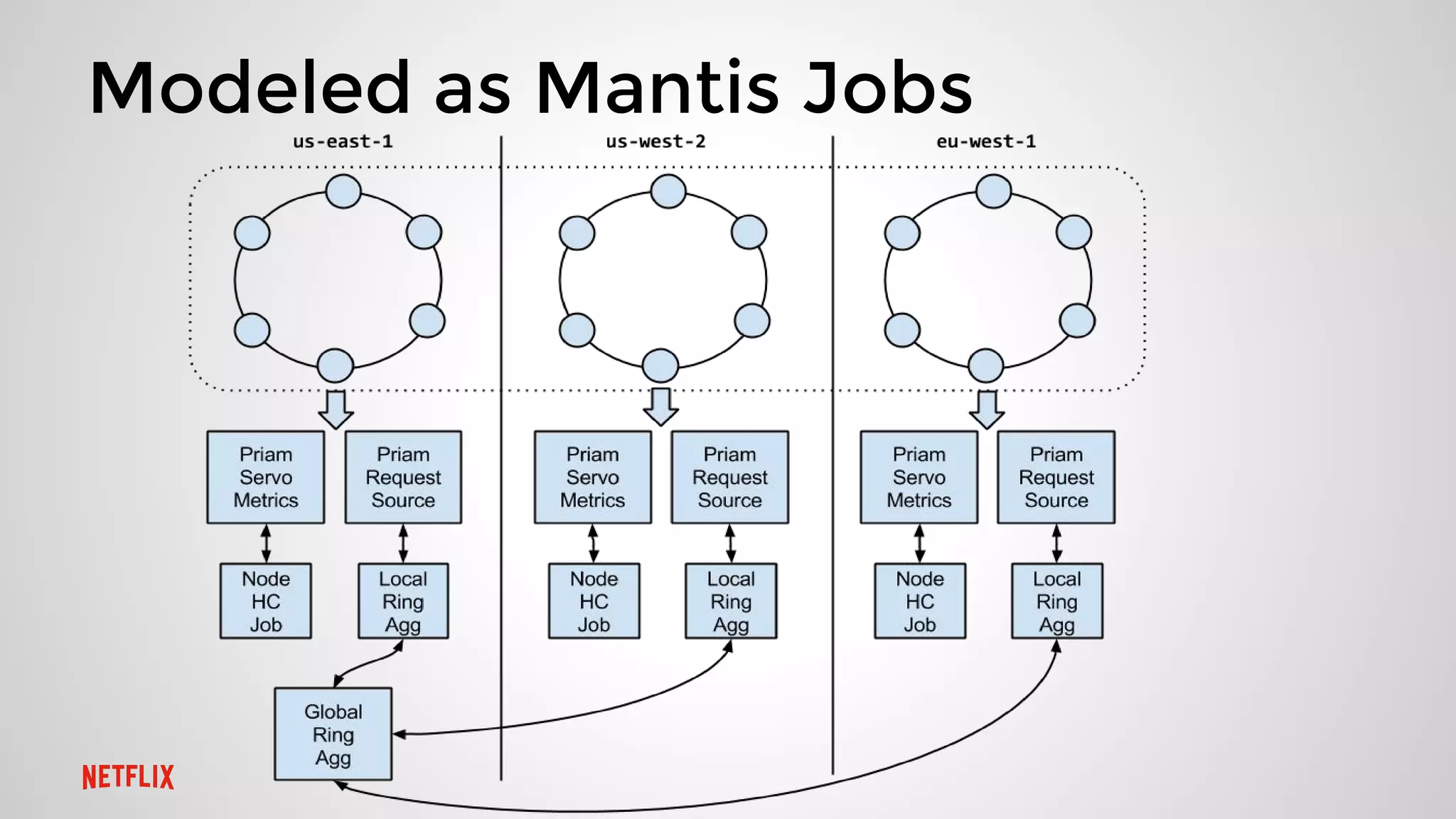
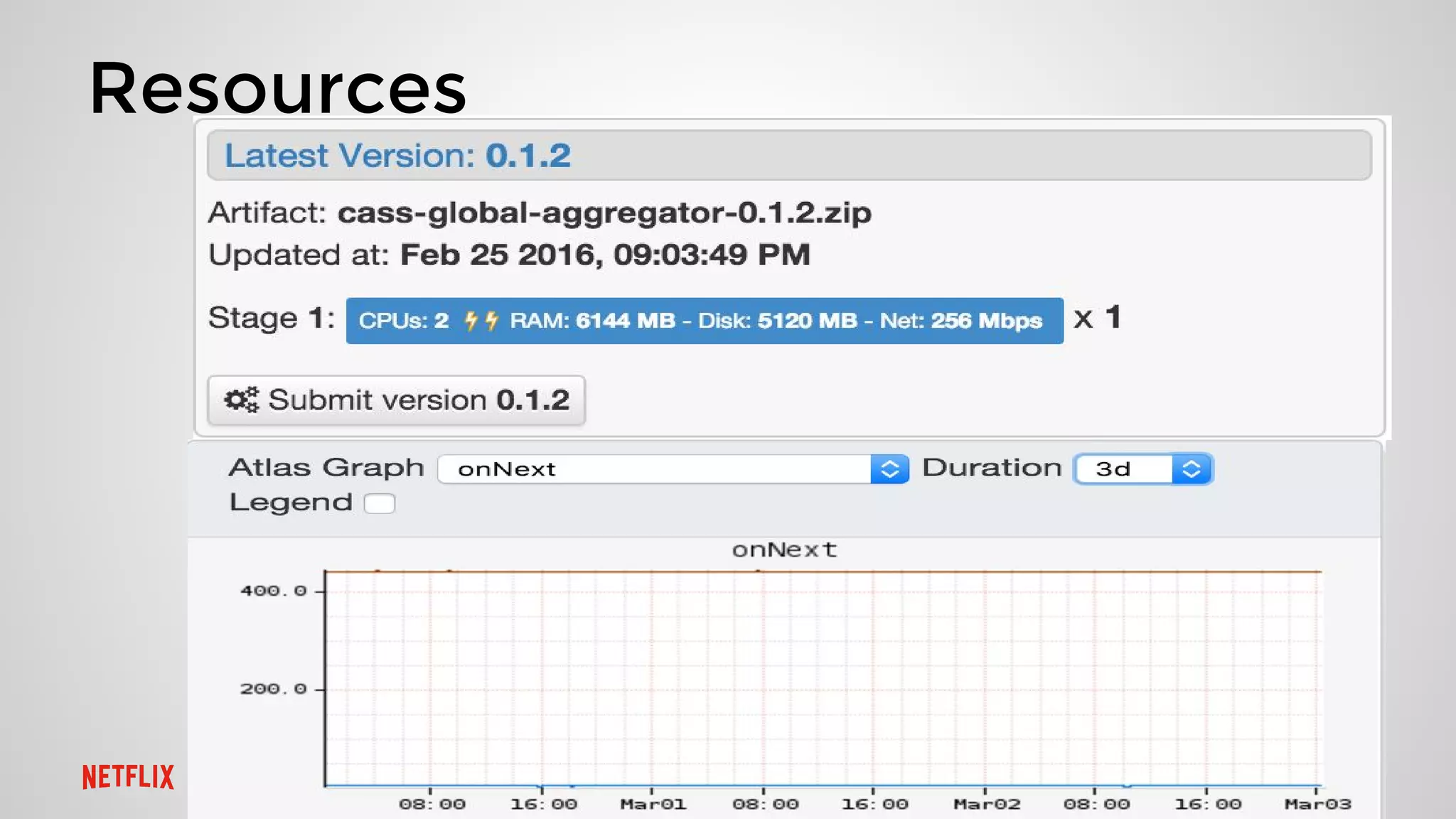
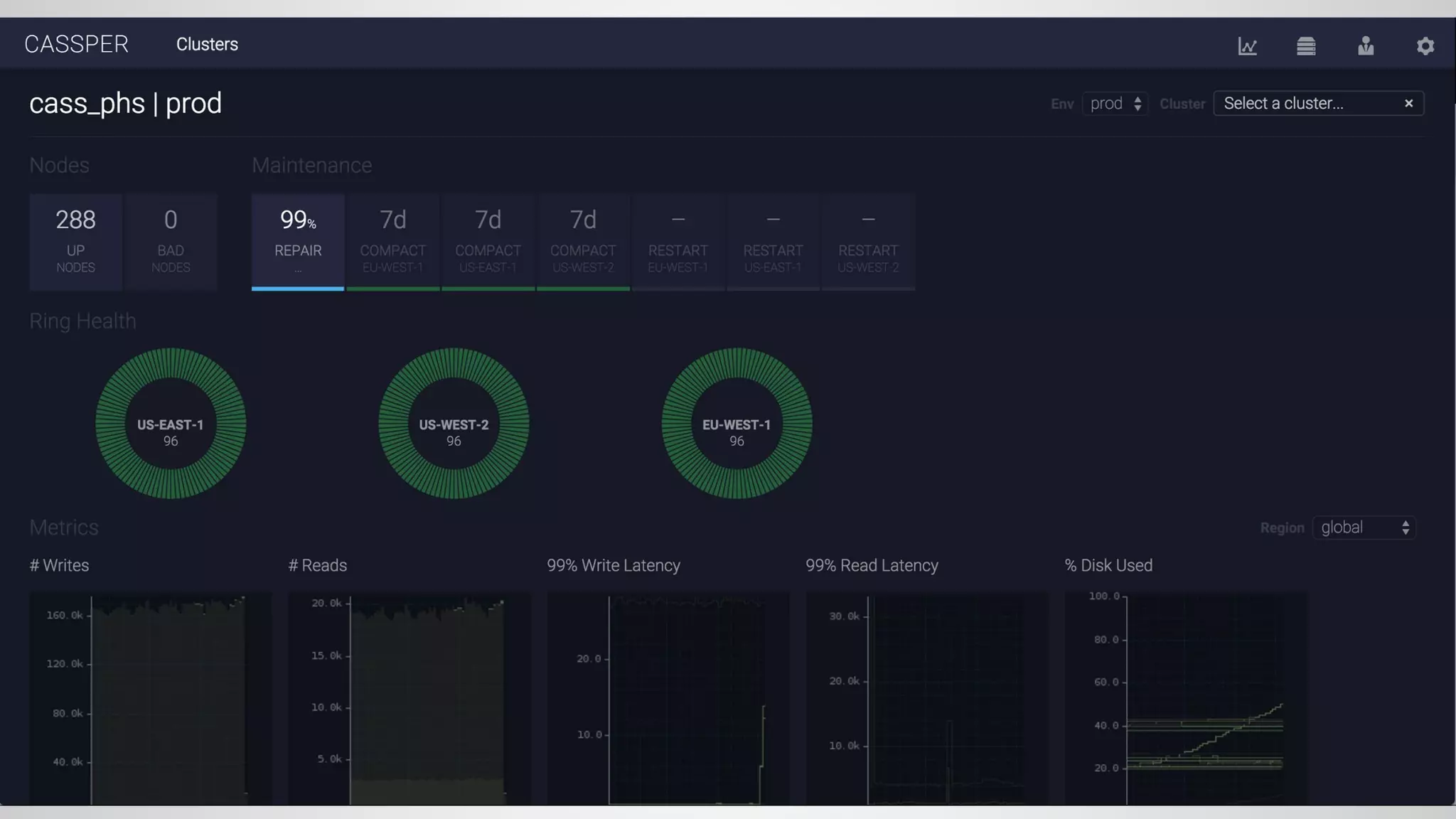
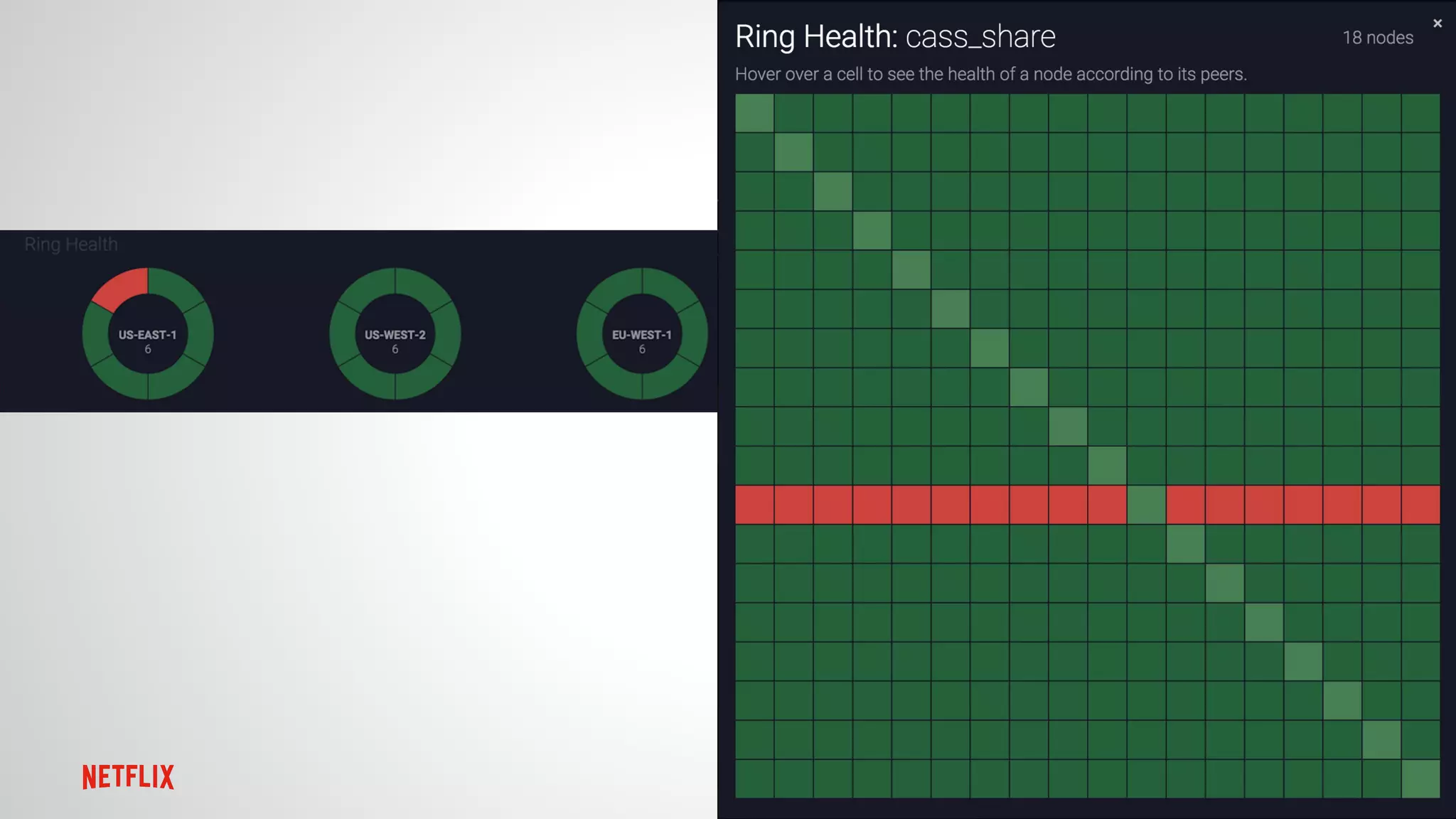





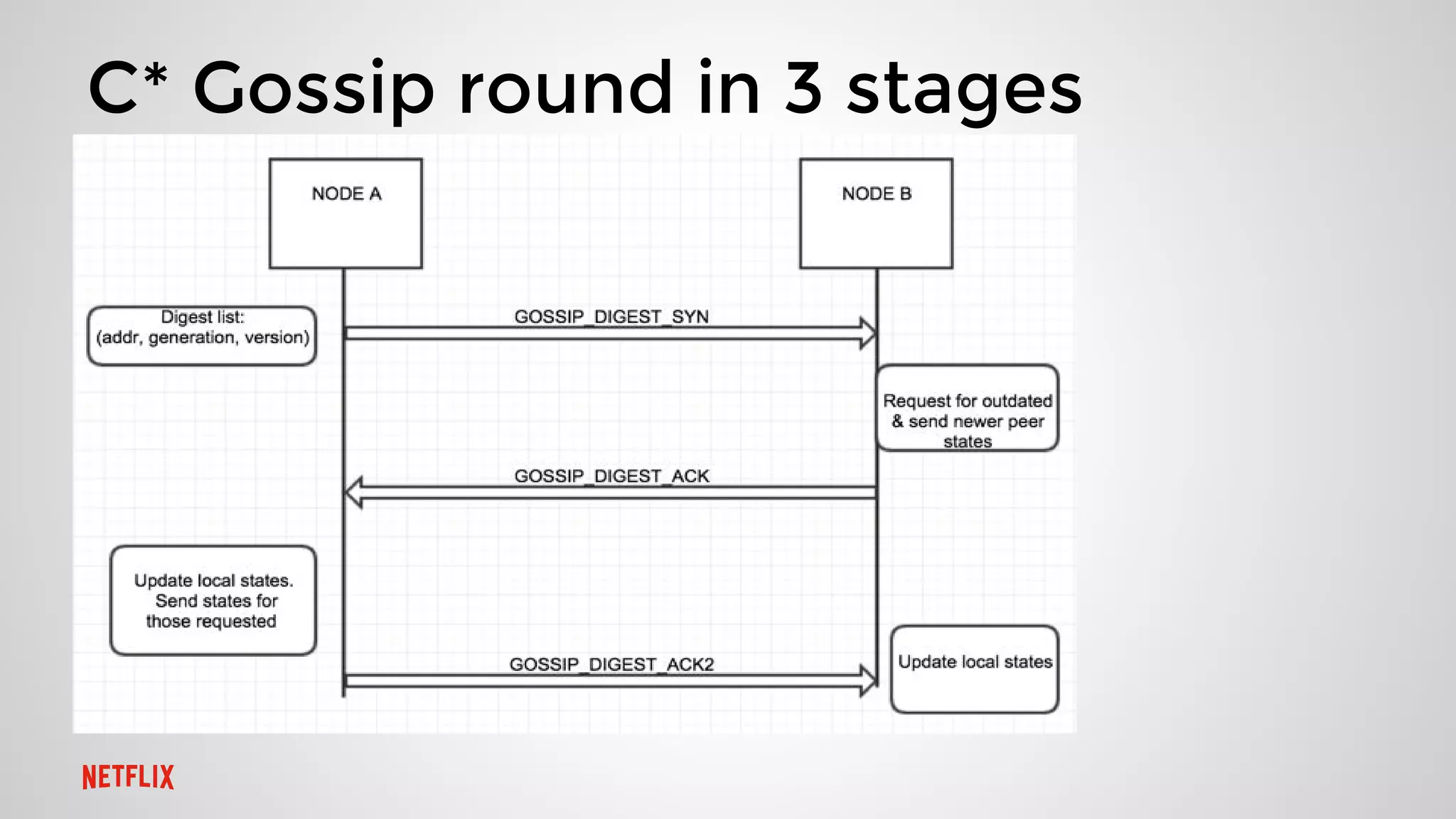











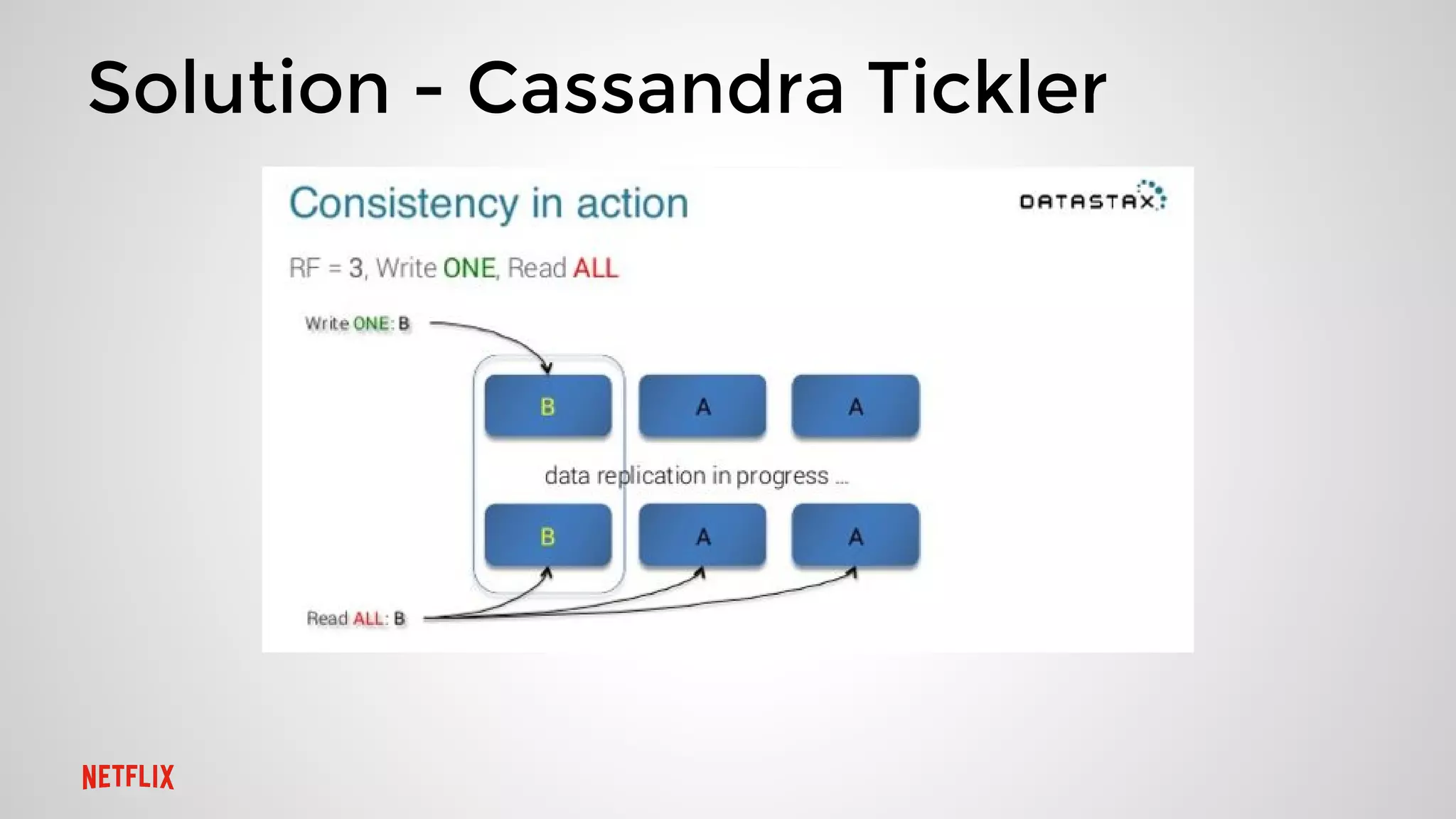



This document summarizes three presentations from a Cassandra Meetup: 1. Jason Cacciatore discussed monitoring Cassandra health at scale across hundreds of clusters and thousands of nodes using the reactive stream processing system Mantis. 2. Minh Do explained how Cassandra uses the gossip protocol for tasks like discovering cluster topology and sharing load information. Gossip also has limitations and race conditions that can cause problems. 3. Chris Kalantzis presented Cassandra Tickler, an open source tool he created to help repair operations that get stuck by running lightweight consistency checks on an old Cassandra version or a node with space issues.






















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






