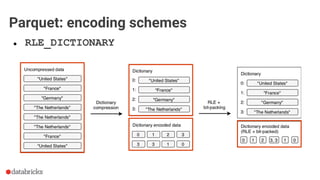
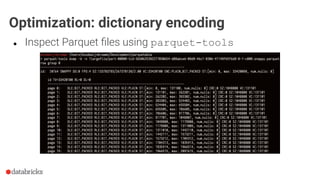
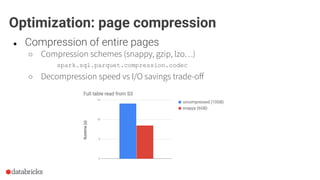
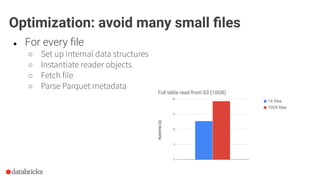
Download as PDF, PPTX










![SELECT * FROM table WHERE x > 5
Row-group 0: x: [min: 0, max: 9]
Row-group 1: x: [min: 3, max: 7]
Row-group 2: x: [min: 1, max: 4]
…
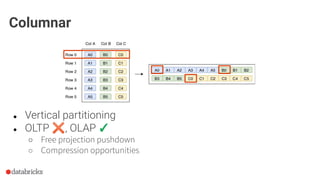
● Leverage min/max statistics
spark.sql.parquet.filterPushdown
Optimization: predicate pushdown](https://image.slidesharecdn.com/boudewijnbraams-191031203910/85/The-Parquet-Format-and-Performance-Optimization-Opportunities-21-320.jpg)

![Optimization: predicate pushdown
SELECT * FROM table WHERE x = 5
Row-group 0: x: [min: 0, max: 9]
Row-group 1: x: [min: 3, max: 7]
Row-group 2: x: [min: 1, max: 4]
…
● Dictionary filtering!
parquet.filter.dictionary.enabled](https://image.slidesharecdn.com/boudewijnbraams-191031203910/85/The-Parquet-Format-and-Performance-Optimization-Opportunities-23-320.jpg)


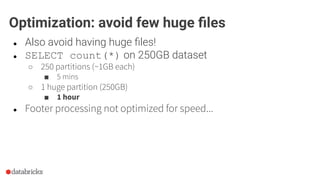






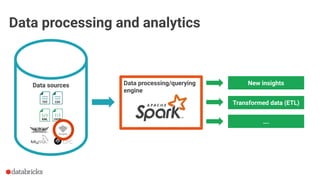
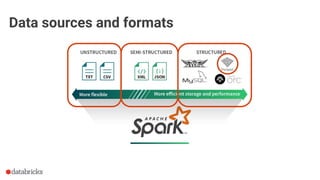
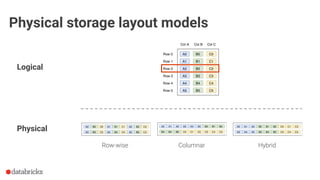
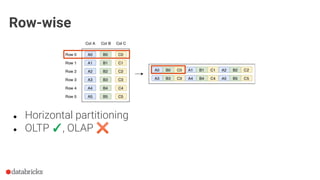
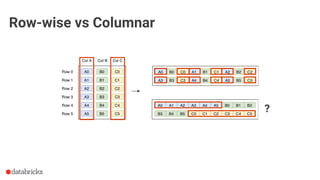
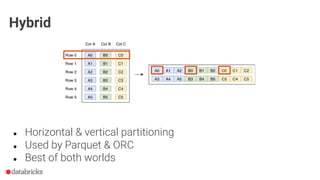
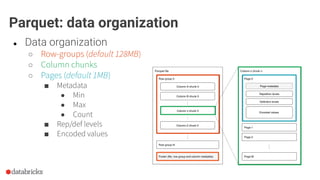
The document discusses optimization opportunities for data storage and processing using the Parquet format, emphasizing its hybrid storage model and efficient data organization strategies. Key points include the significance of handling row-wise and columnar data, minimizing I/O operations through techniques like predicate pushdown and partitioning, and the advantages of using Delta Lake for managing data at scale. It serves as a guide for software engineers in understanding performance improvements in data analytics workflows.























































































