Download as PDF, PPTX
















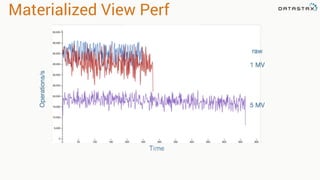
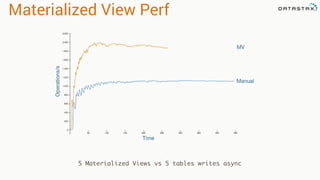
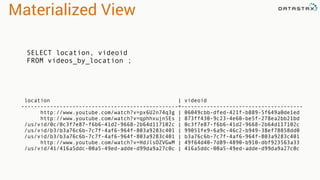
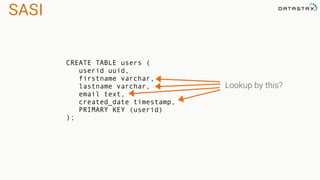





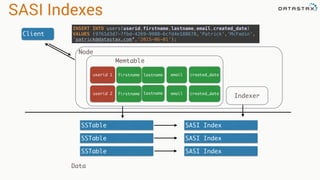





The document discusses the evolution of Cassandra's data modeling capabilities over different versions of CQL. It covers features introduced in each version such as user defined types, functions, aggregates, materialized views, and storage attached secondary indexes (SASI). It provides examples of how to create user defined types, functions, materialized views, and SASI indexes in CQL. It also discusses when each feature should and should not be used.























































































