


![Ongoing and Future Work on the Connector
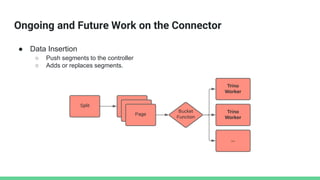
● Pinot Segments Deletion
● Table & Column Creation/Alter/Drop
CREATE TABLE DIMTABLE
(LONG_COL bigint, STRING_COL varchar)
WITH (
PRIMARY_KEY_COLUMNS = ARRAY['long_col'],
OFFLINE_CONFIG = '{
"tableName": "dimtable",
"tableType": "OFFLINE",
"isDimTable": true,
"segmentsConfig": {
"segmentPushType": "REFRESH",
"replication": "1"
},
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP"
}
}’
);](https://image.slidesharecdn.com/trinosummit2021real-timeanalyticswithprestoandapachepinot-220208001605/85/Real-time-Analytics-with-Trino-and-Apache-Pinot-22-320.jpg)

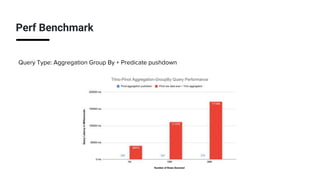

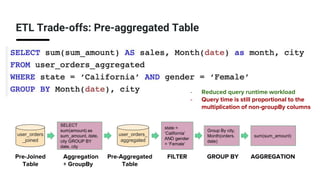
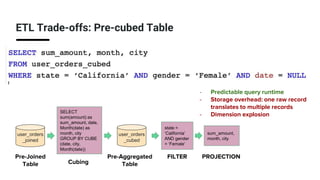
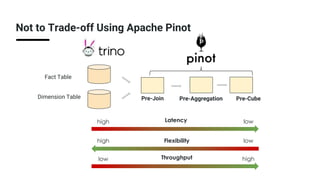
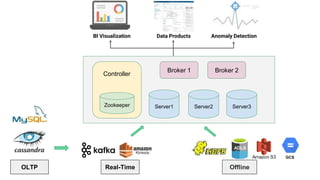
The document discusses real-time analytics using Trino and Apache Pinot, focusing on balancing latency and flexibility without sacrificing performance. It covers various ETL trade-offs like pre-joined, pre-aggregated, and pre-cubed tables, and highlights Apache Pinot's capabilities in handling high query loads and fast ingestion. It also details the Trino Pinot connector's functionalities, including aggregation pushdown and the configuration of data handling for optimized query performance.