Downloaded 33 times




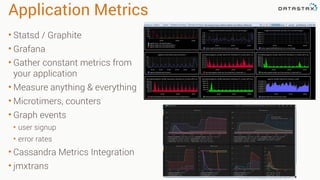
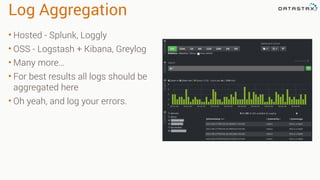
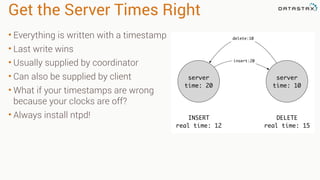

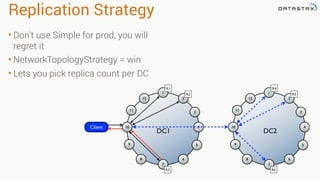




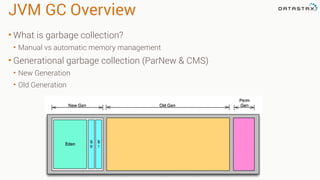
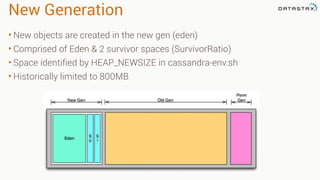

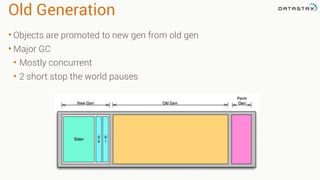

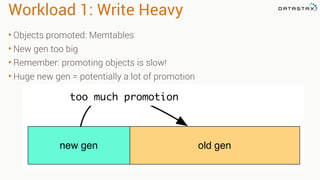
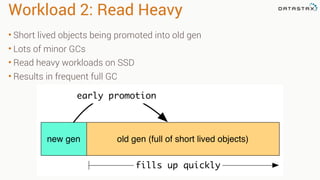
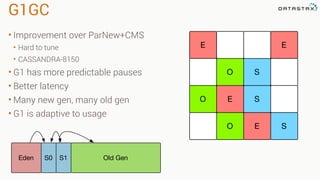

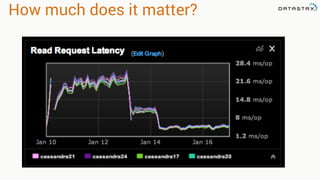


This document provides guidance on setting up server monitoring, application metrics, log aggregation, time synchronization, replication strategies, and garbage collection for a Cassandra cluster. Key recommendations include: 1. Use monitoring tools like Monit, Munin, Nagios, or OpsCenter to monitor processes, disk usage, and system performance. Aggregate all logs centrally with tools like Splunk, Logstash, or Greylog. 2. Install NTP to synchronize server times which are critical for consistency. 3. Use the NetworkTopologyStrategy replication strategy and avoid SimpleStrategy for production. 4. Avoid shared storage and focus on low latency and high throughput using multiple local disks. 5. Understand























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


