Downloaded 116 times




















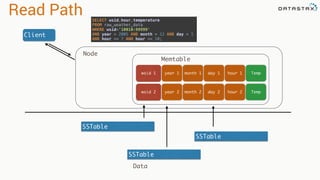





![CQL List
• Ordered by insertion
• Use with caution
list_example list<text>
Collection name Collection type
INSERT INTO collections_example (id, list_example)
VALUES(1, ['1-one', '2-two']);
CQLType](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/85/Introduction-to-Data-Modeling-with-Apache-Cassandra-43-320.jpg)
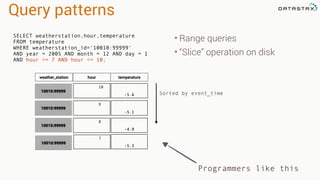
![CQL List Operations
• Adding an element to the end of a list
• Adding an element to the beginning of a list
• Deleting an element from a list
UPDATE collections_example
SET list_example = list_example + ['3-three']
WHERE id = 1;
UPDATE collections_example
SET list_example = ['0-zero'] + list_example
WHERE id = 1;
UPDATE collections_example
SET list_example = list_example - ['3-three'] WHERE id = 1;](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/85/Introduction-to-Data-Modeling-with-Apache-Cassandra-44-320.jpg)

![CQL Map Operations
• Add an element to the map
• Update an existing element in the map
• Delete an element in the map
UPDATE collections_example
SET map_example[3] = 'three'
WHERE id = 1;
UPDATE collections_example
SET map_example[3] = 'tres'
WHERE id = 1;
DELETE map_example[3]
FROM collections_example
WHERE id = 1;](https://image.slidesharecdn.com/introduction-to-data-modeling-with-apache-cassandra-160219183514/85/Introduction-to-Data-Modeling-with-Apache-Cassandra-46-320.jpg)









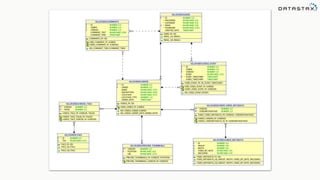
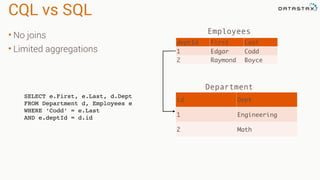
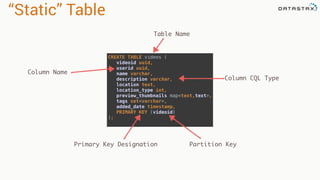
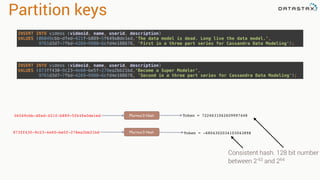
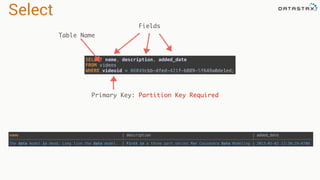
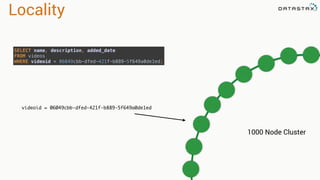
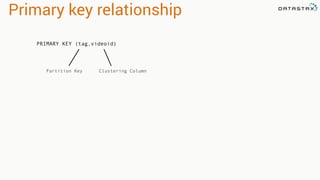
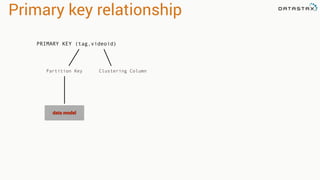
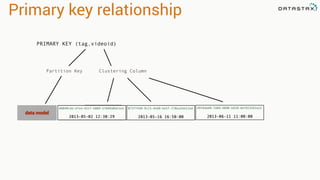
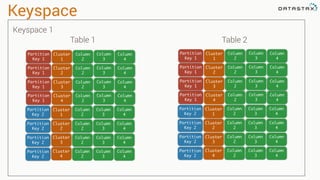
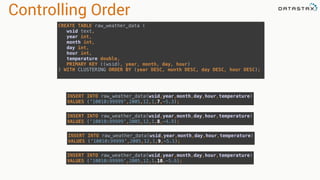
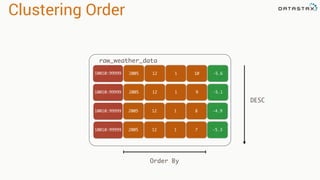
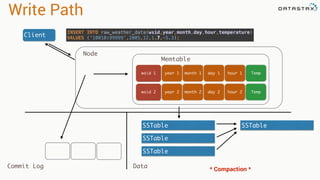
This document provides an introduction to data modeling with Apache Cassandra. It discusses how Cassandra data models are designed based on the queries an application will perform, unlike relational databases which are designed based on normalization rules. Key aspects covered include avoiding joins by denormalizing data, using a partition key to group related data on nodes, and controlling the clustering order of columns. The document provides examples of modeling time series and tag data in Cassandra.









































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















