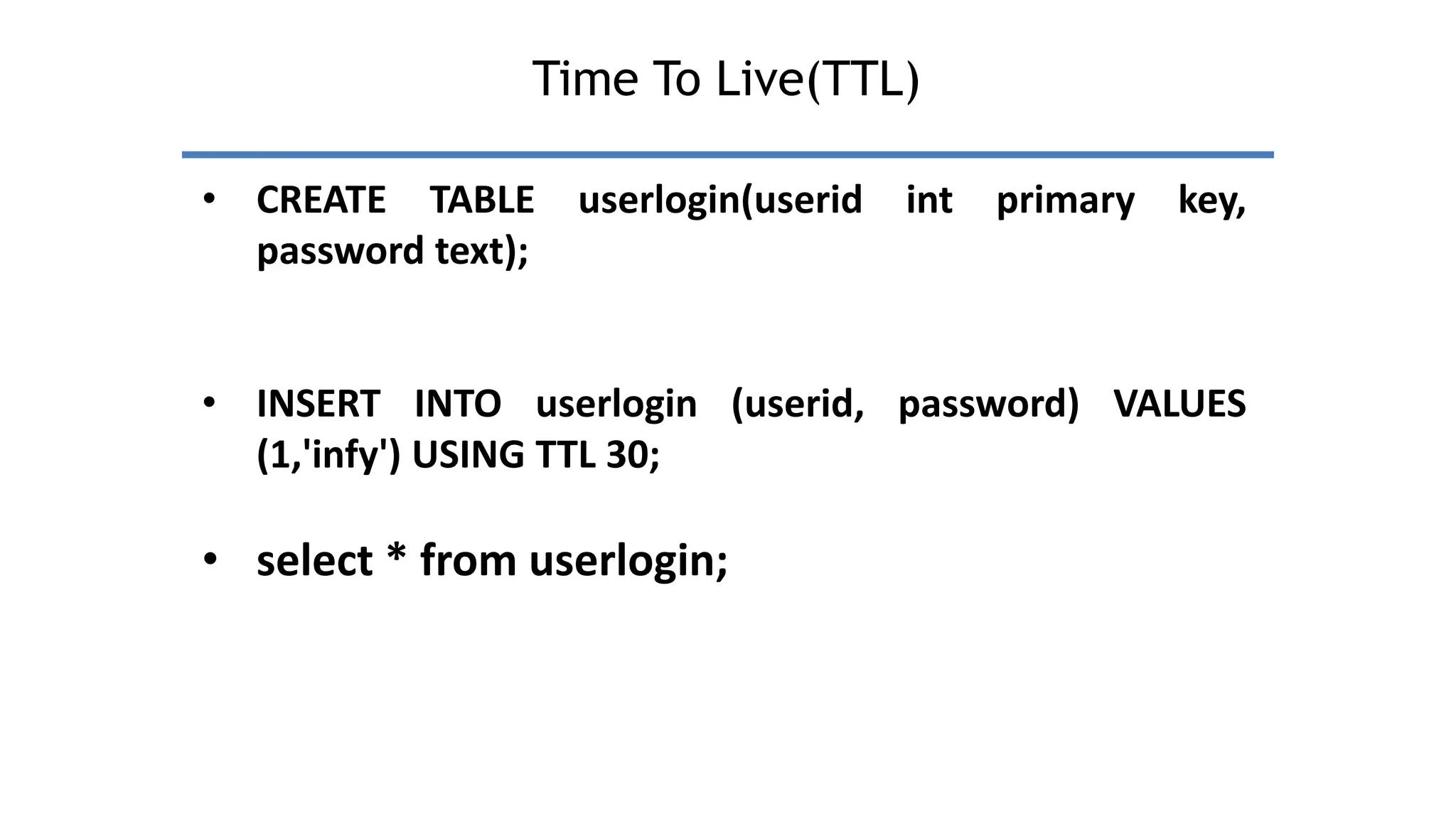
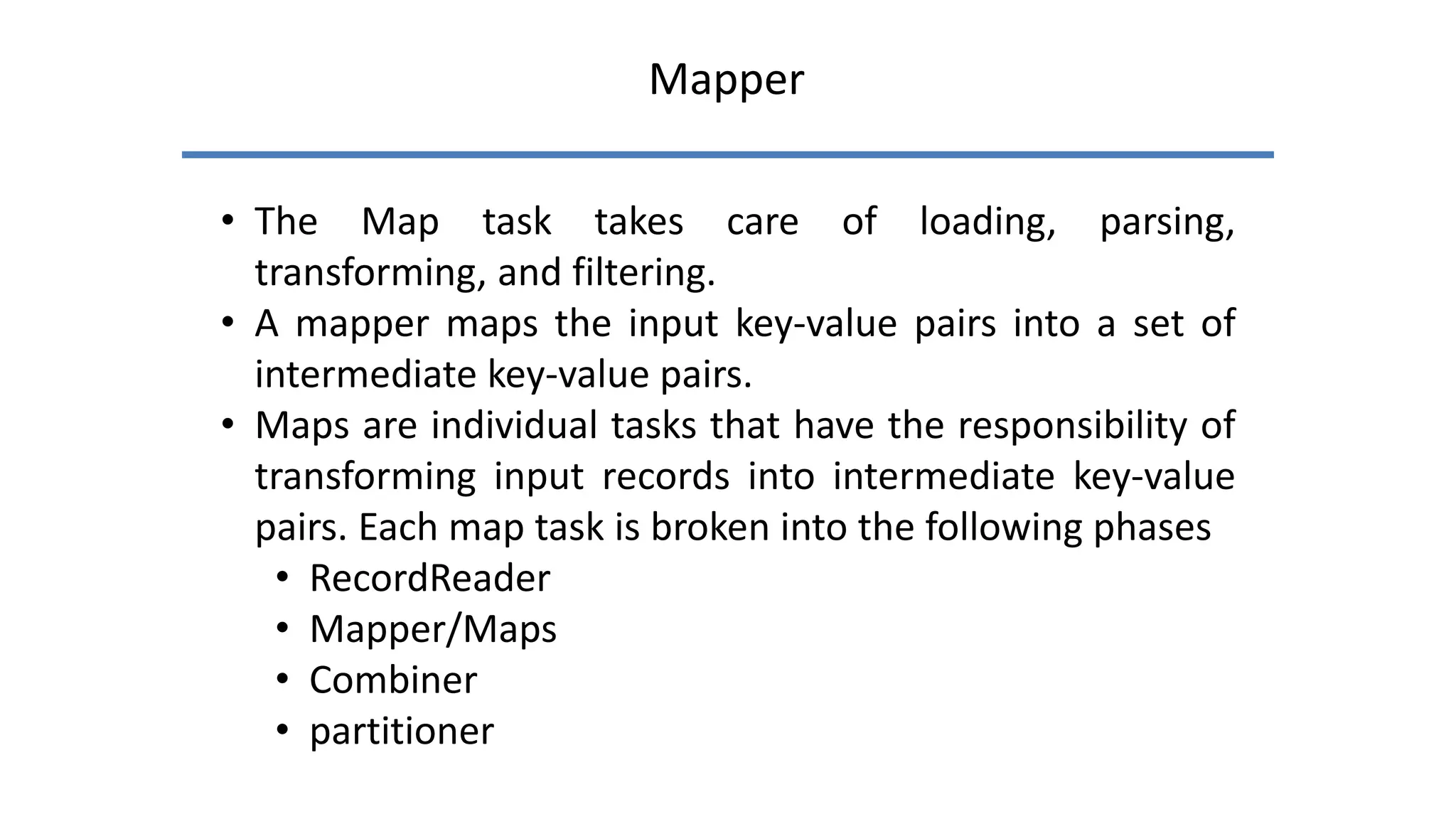
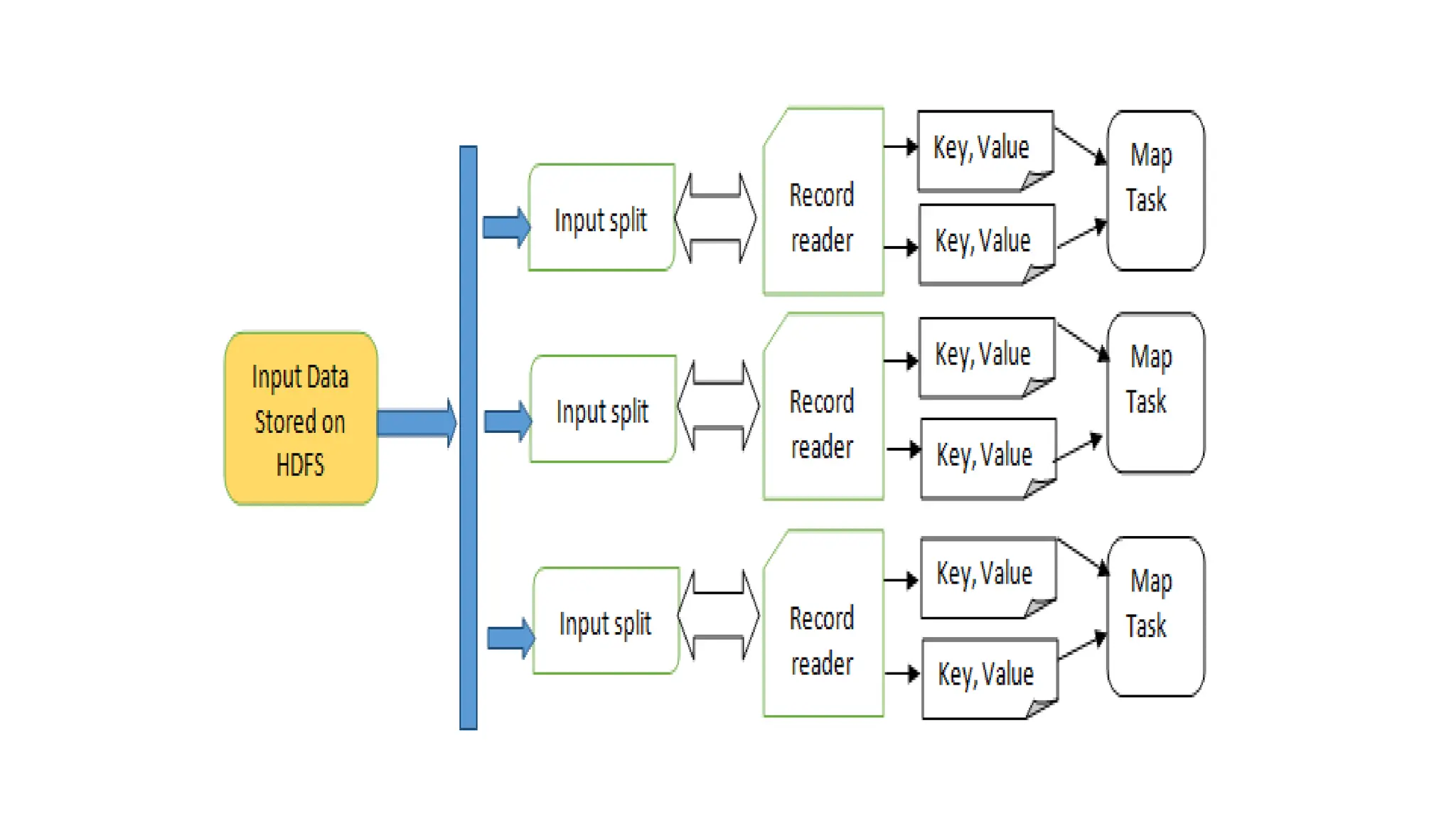
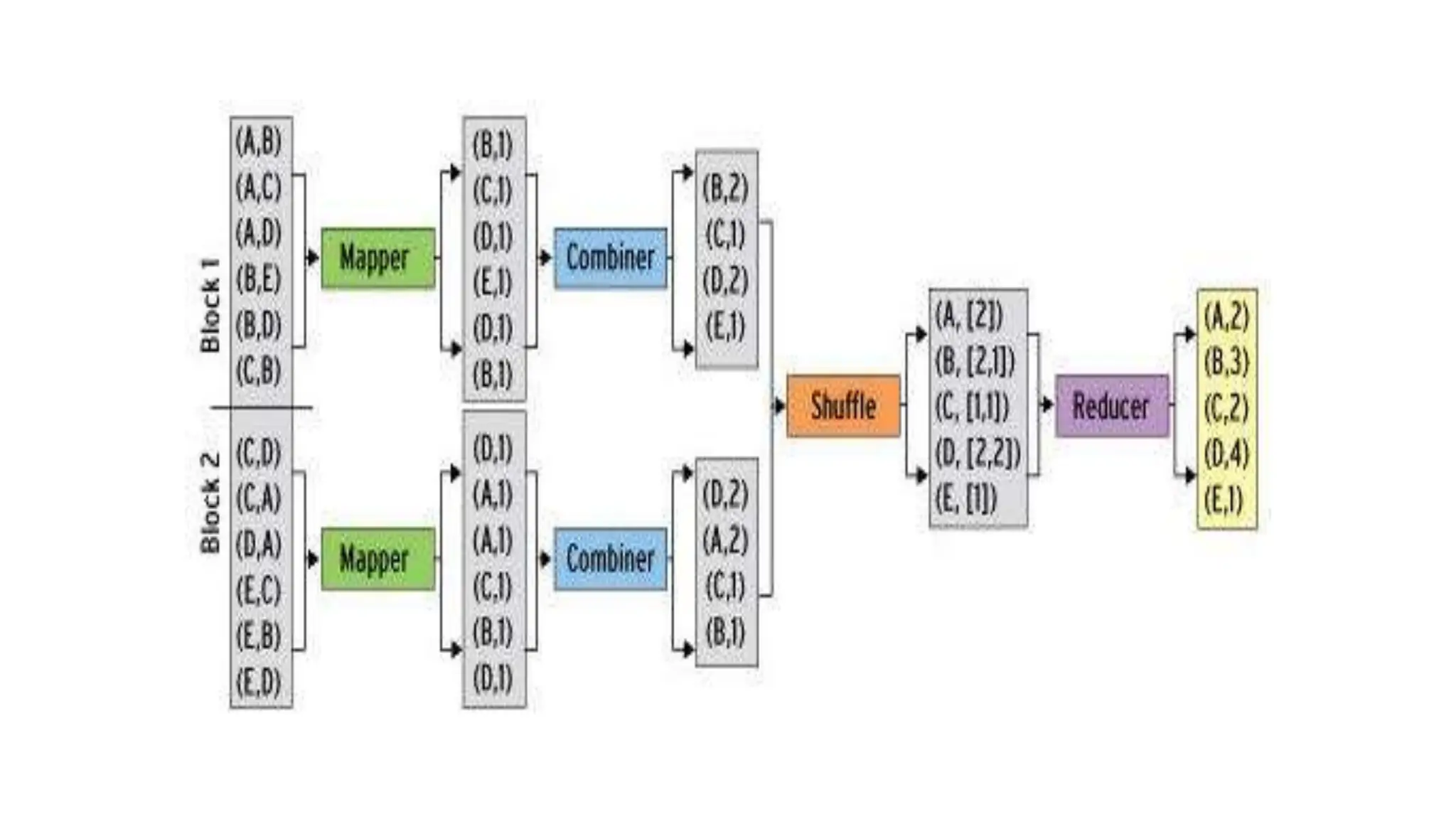
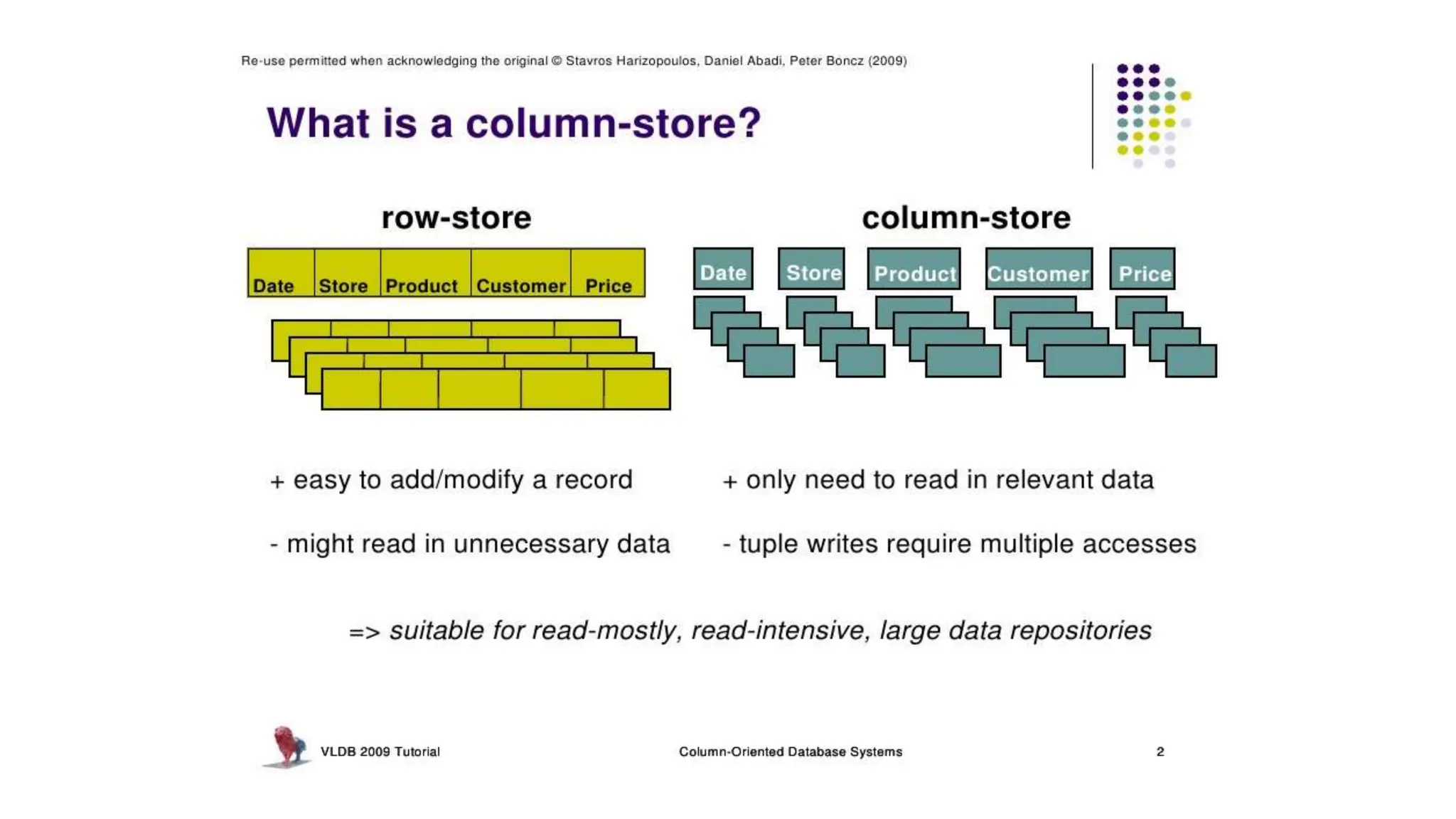
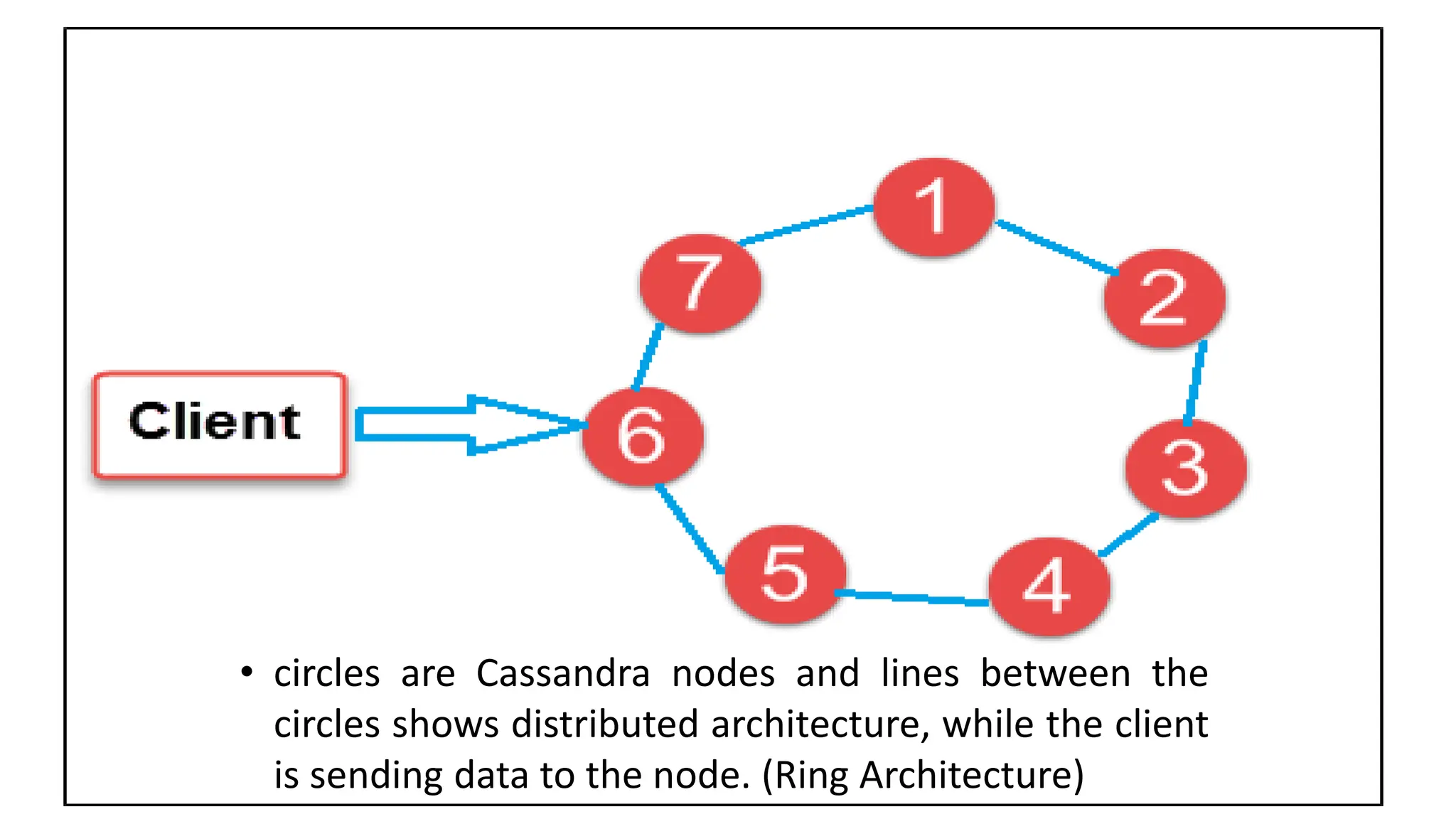
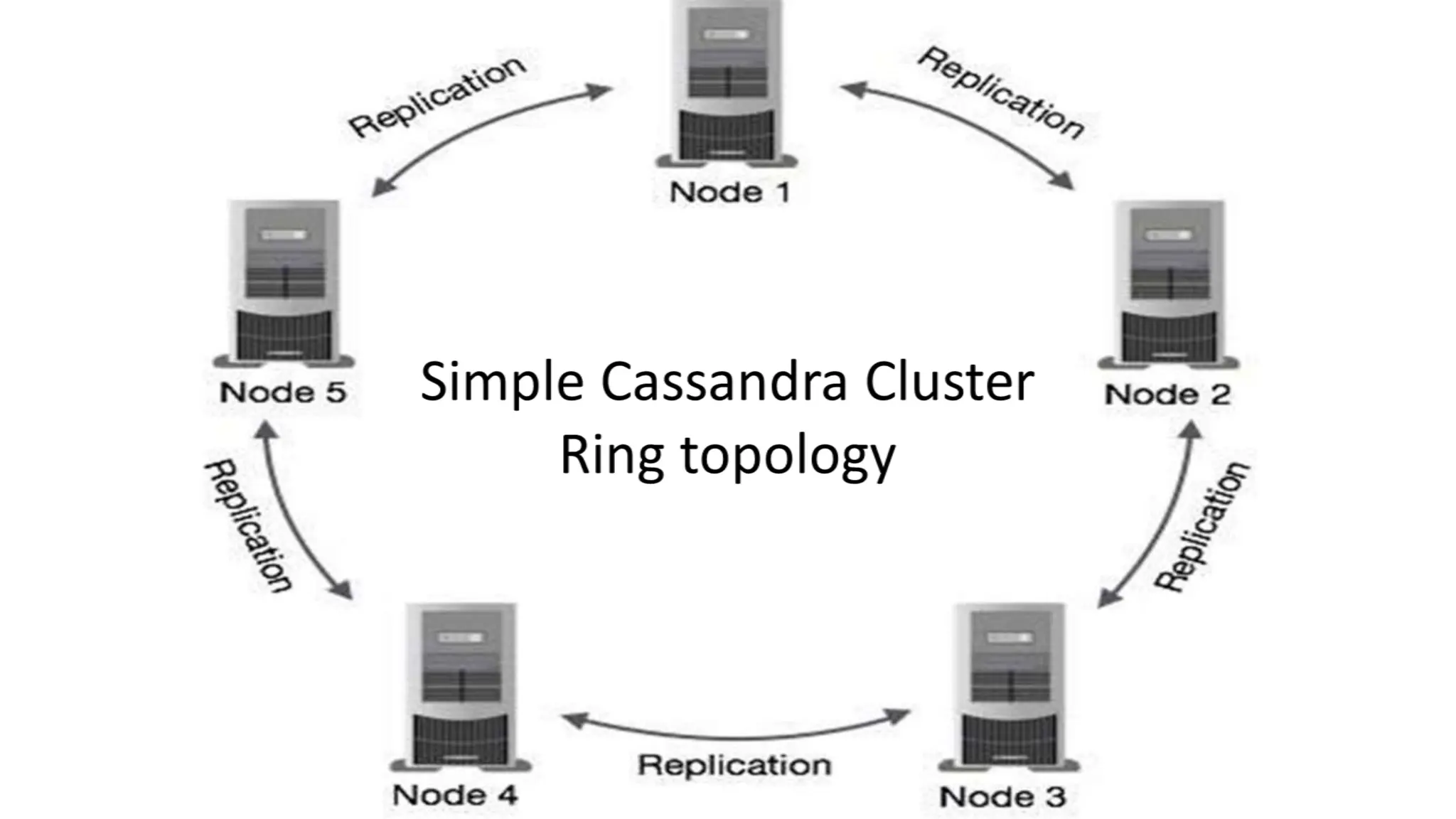
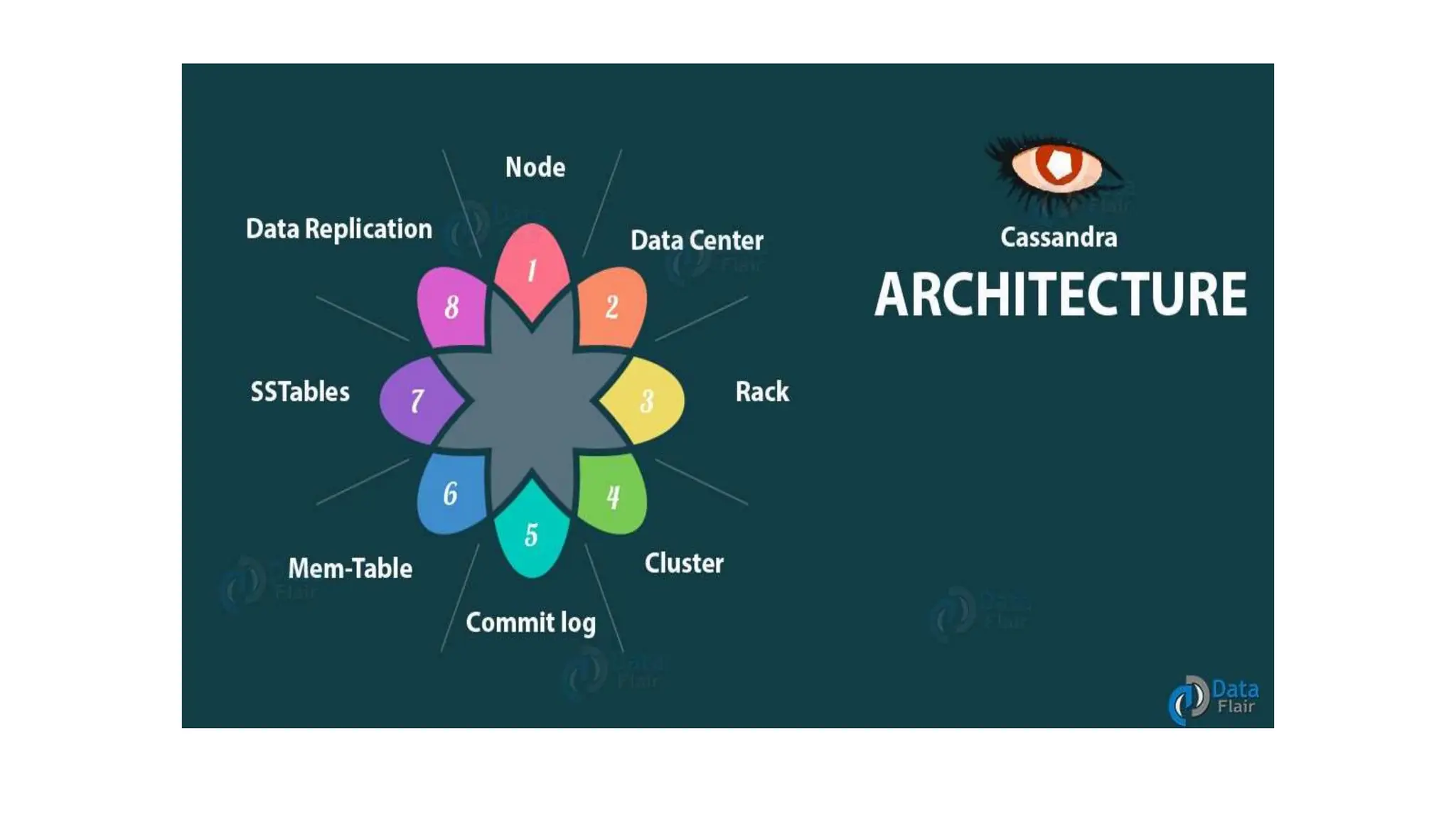
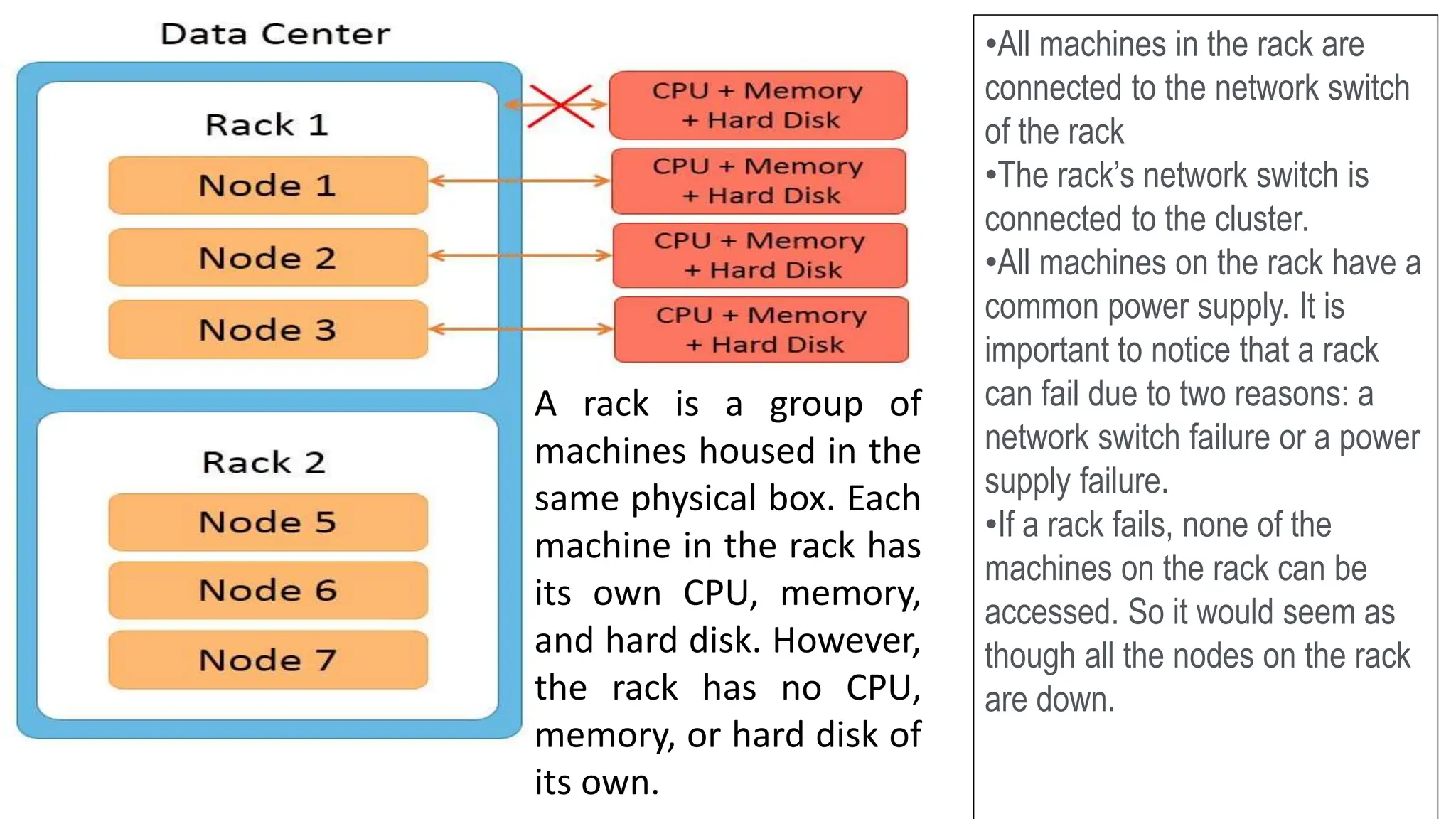
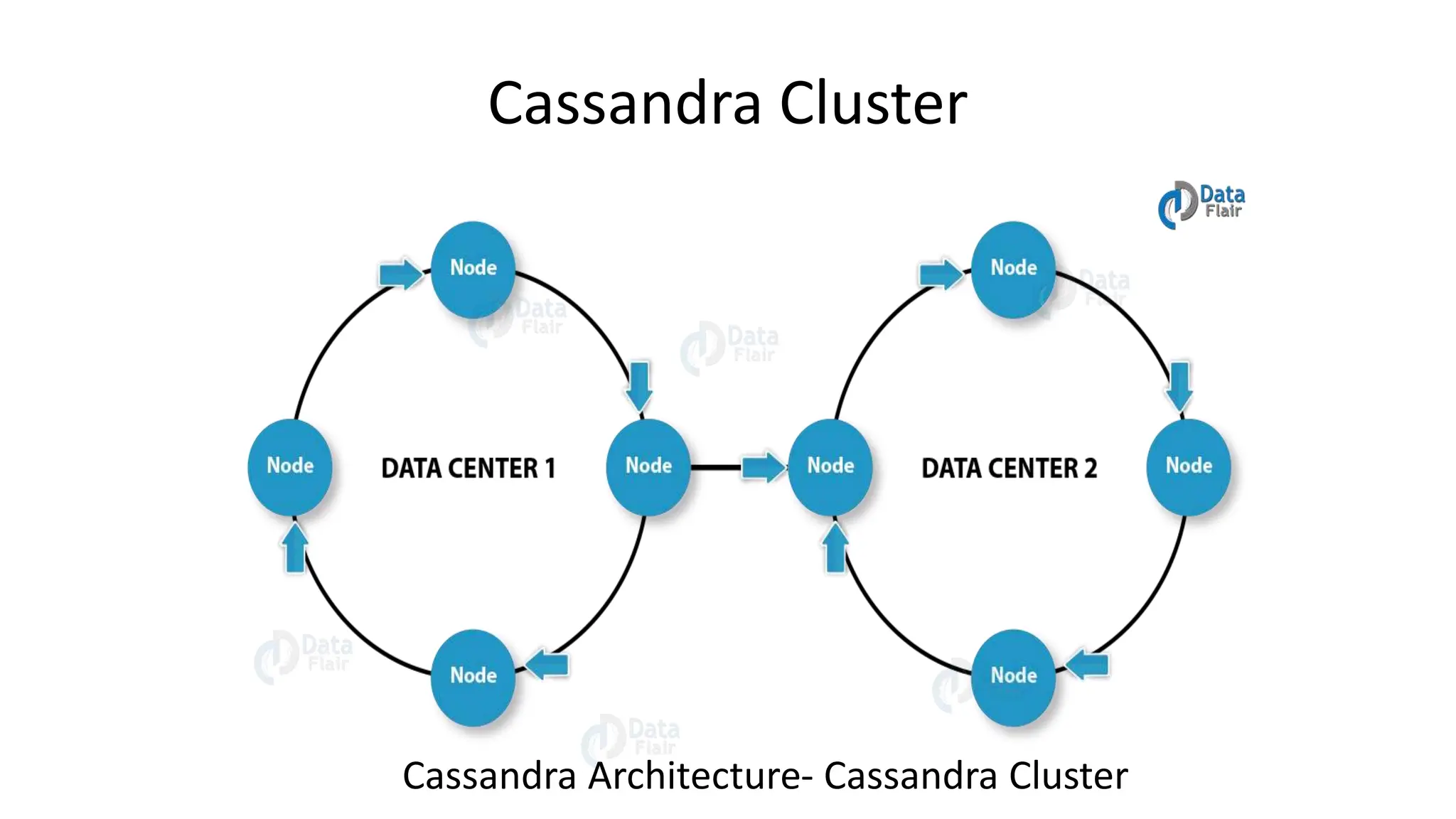
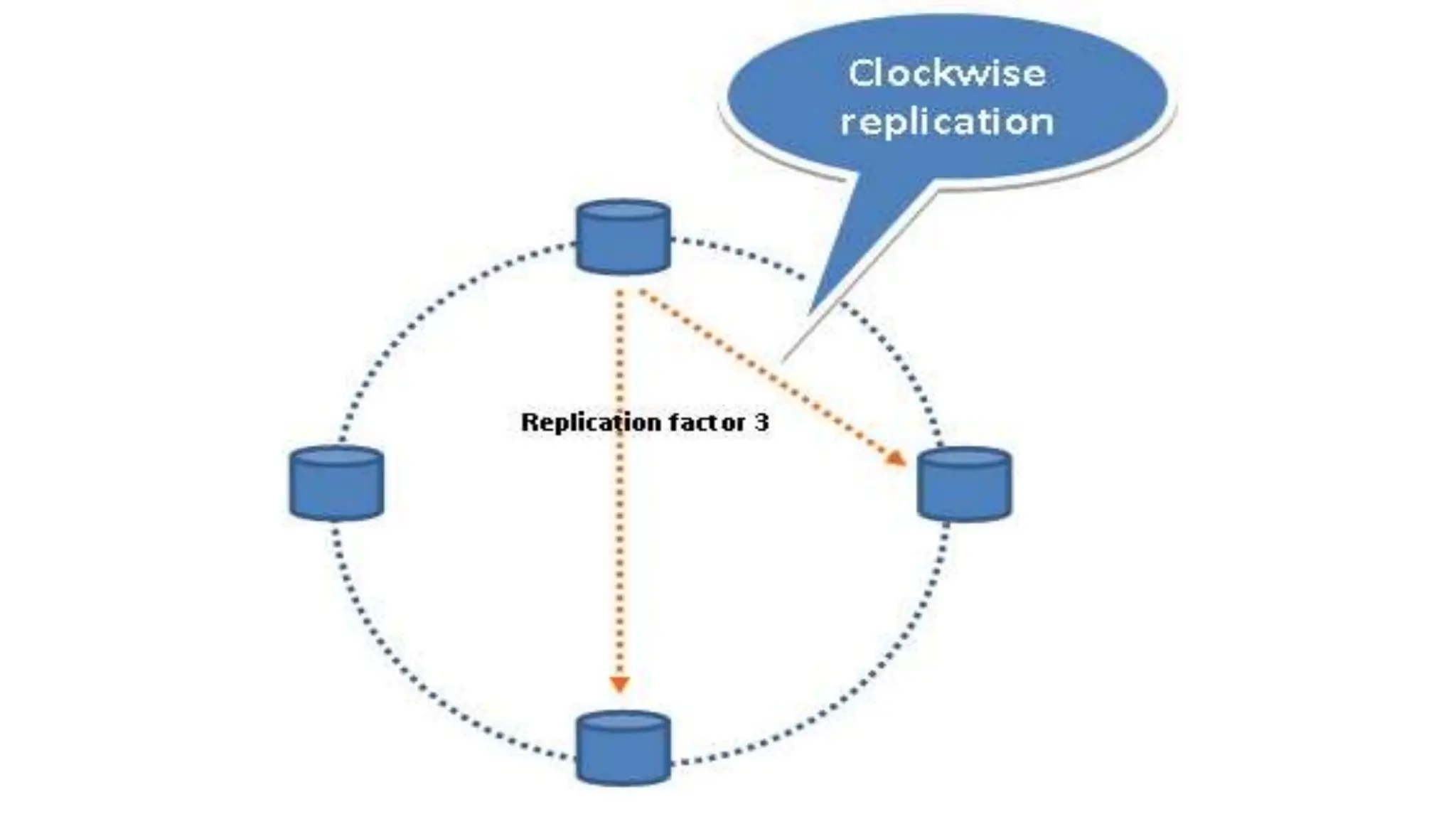
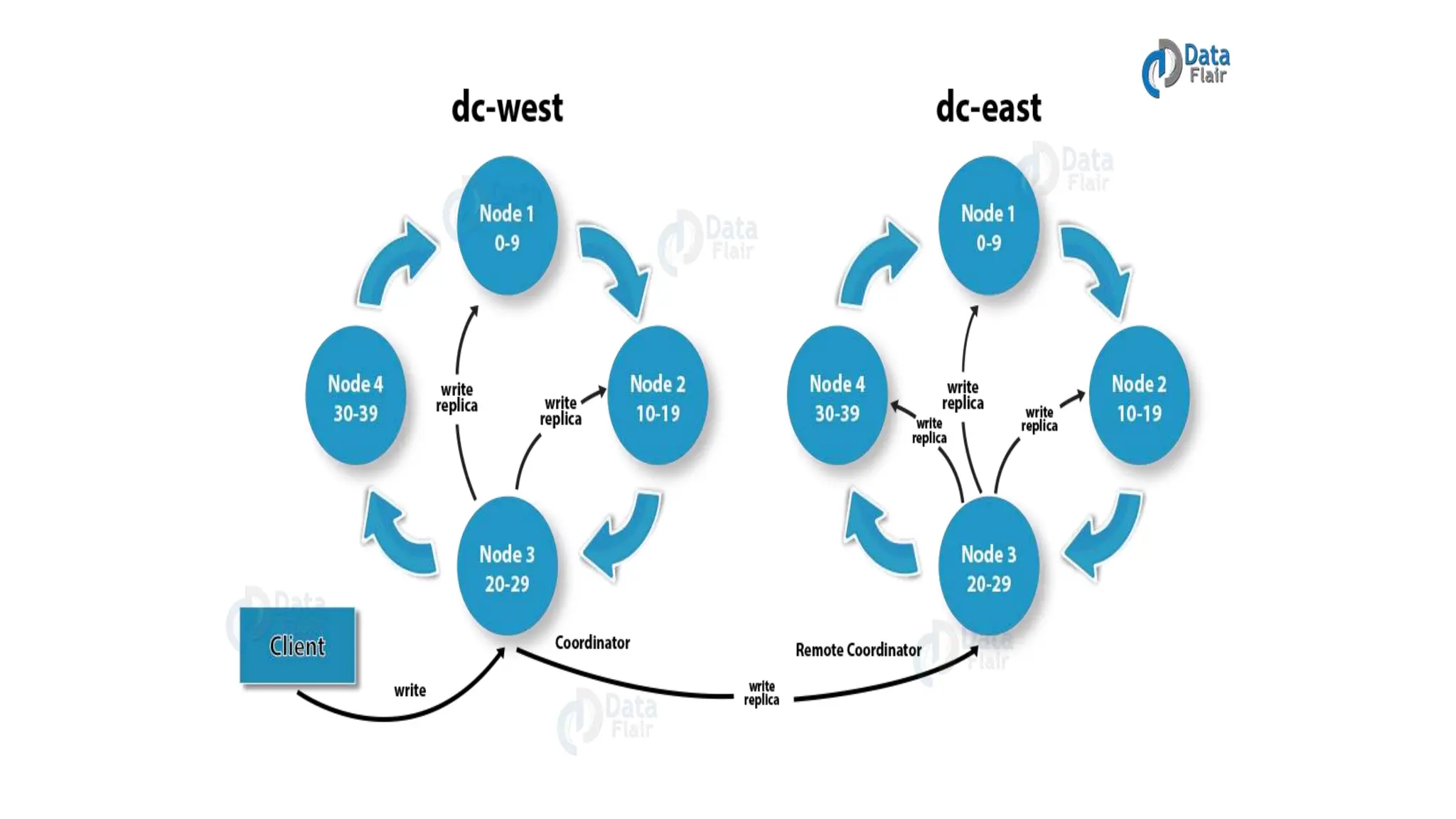
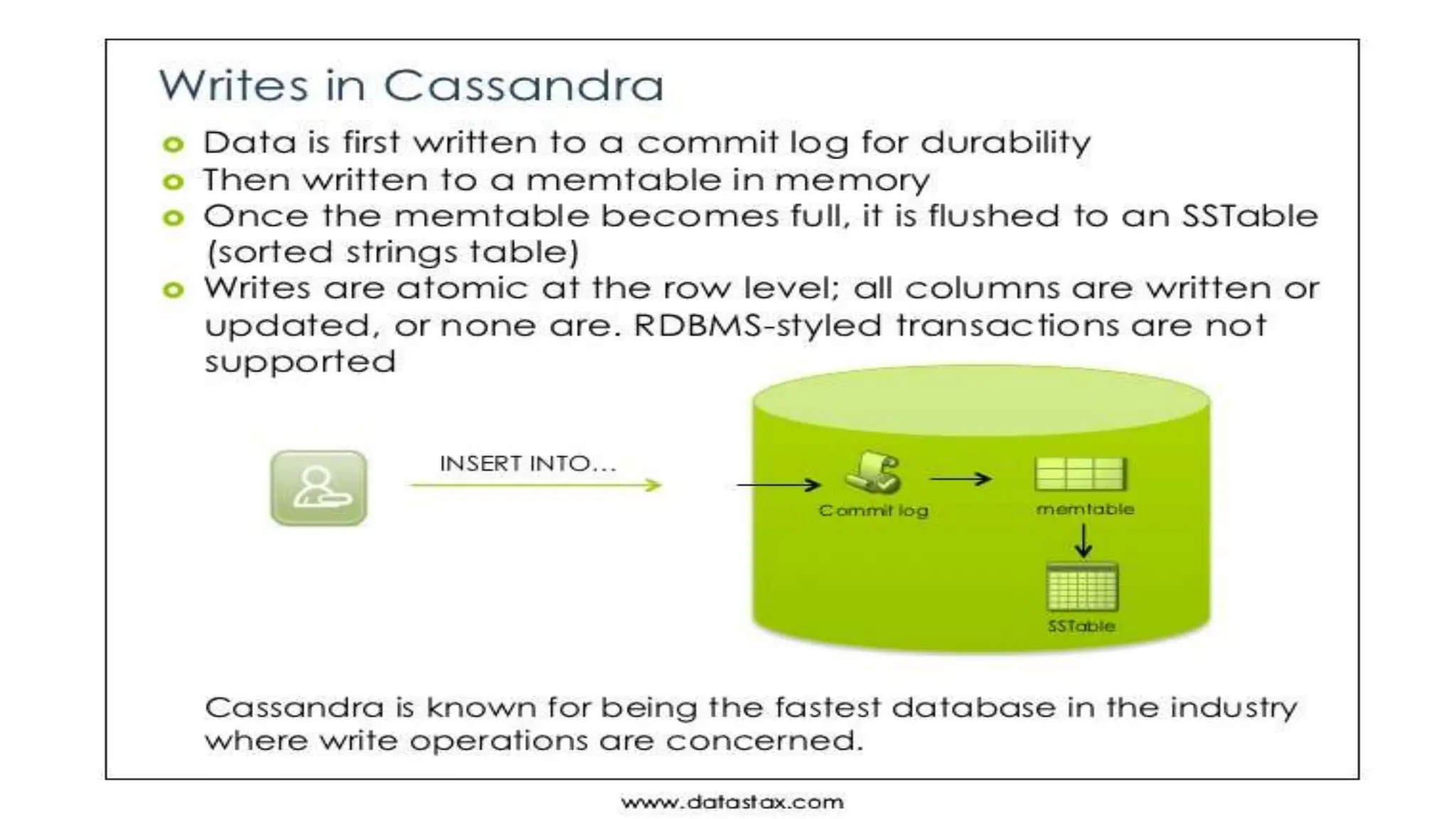
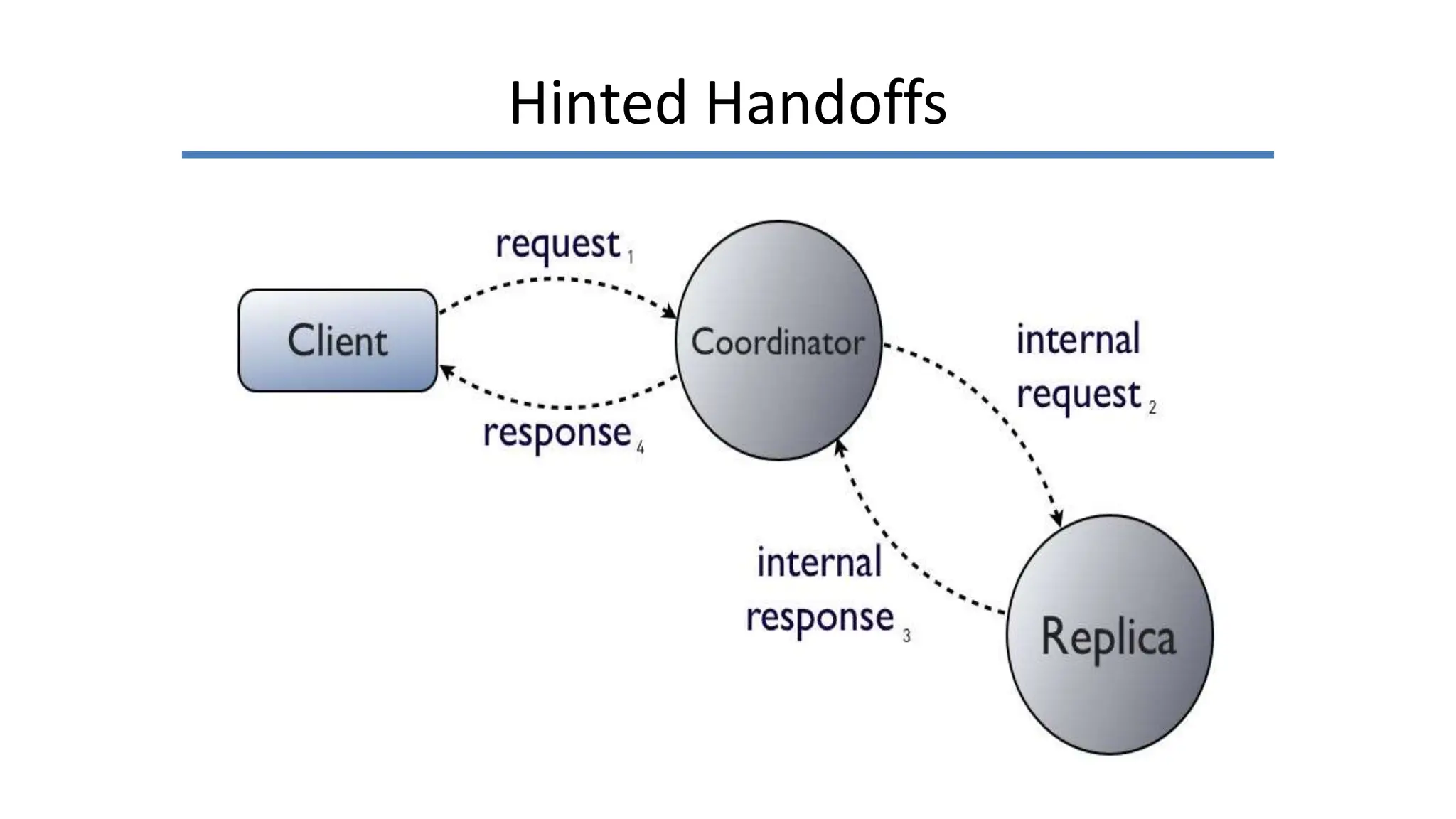
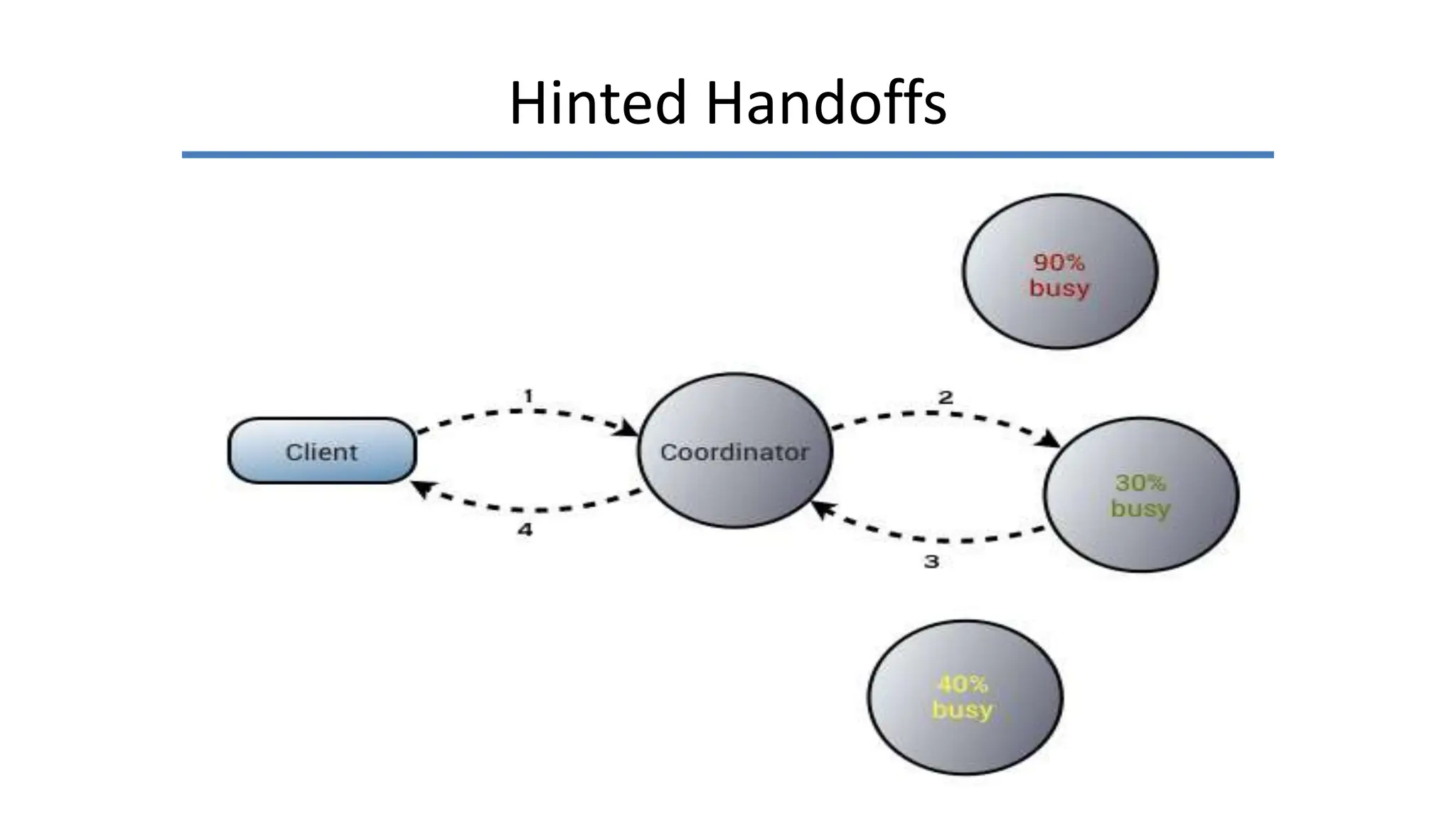
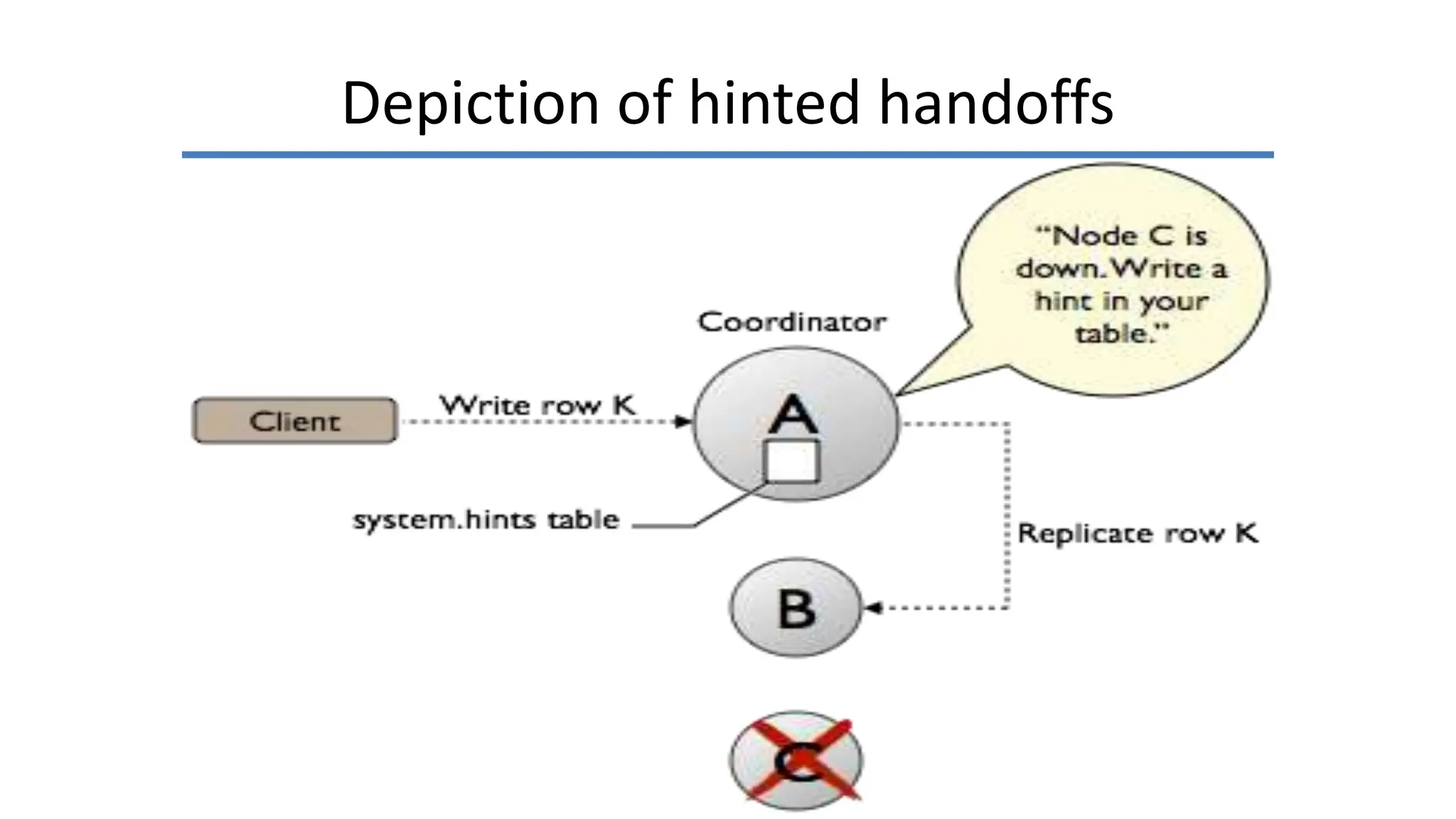
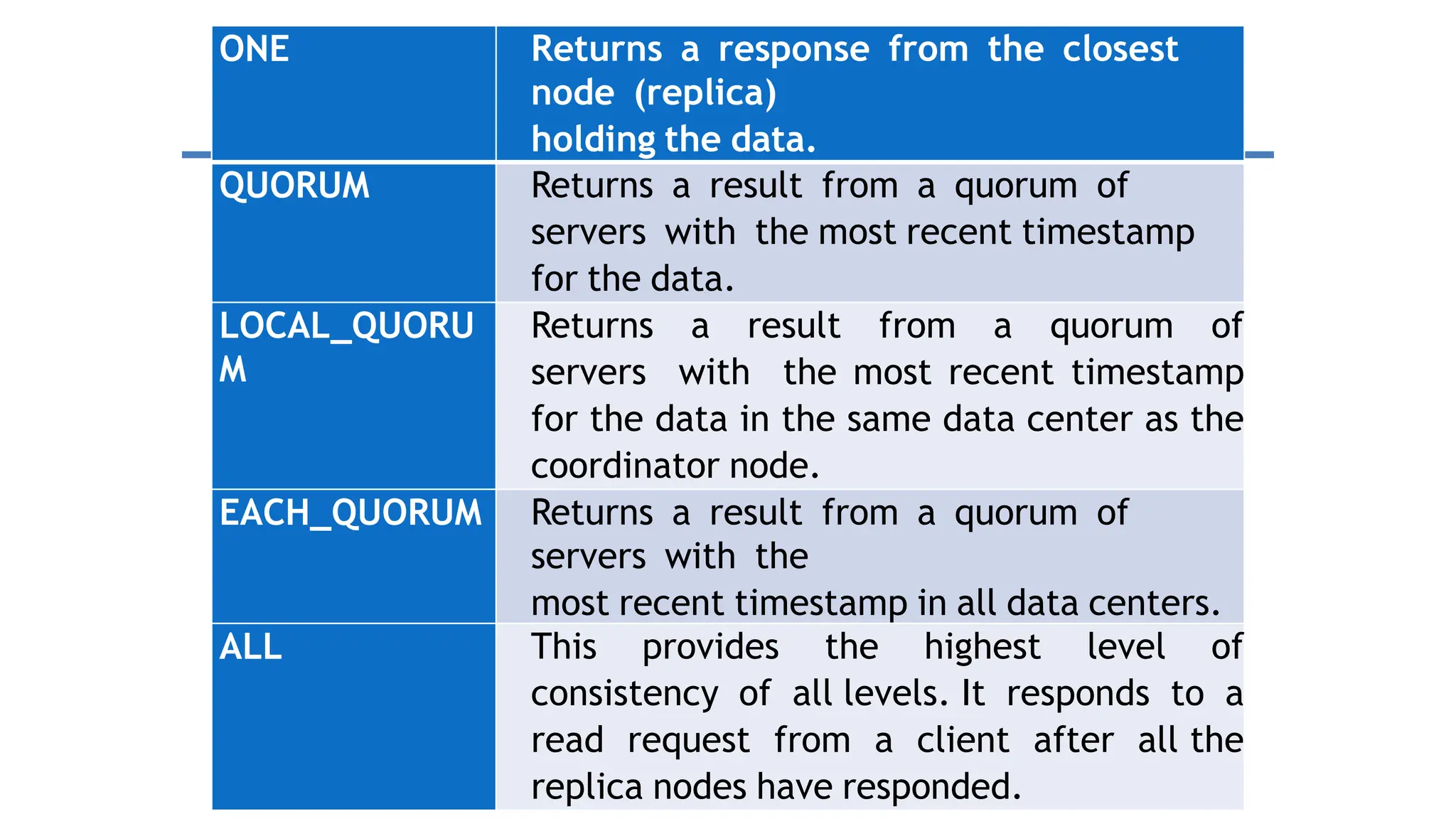
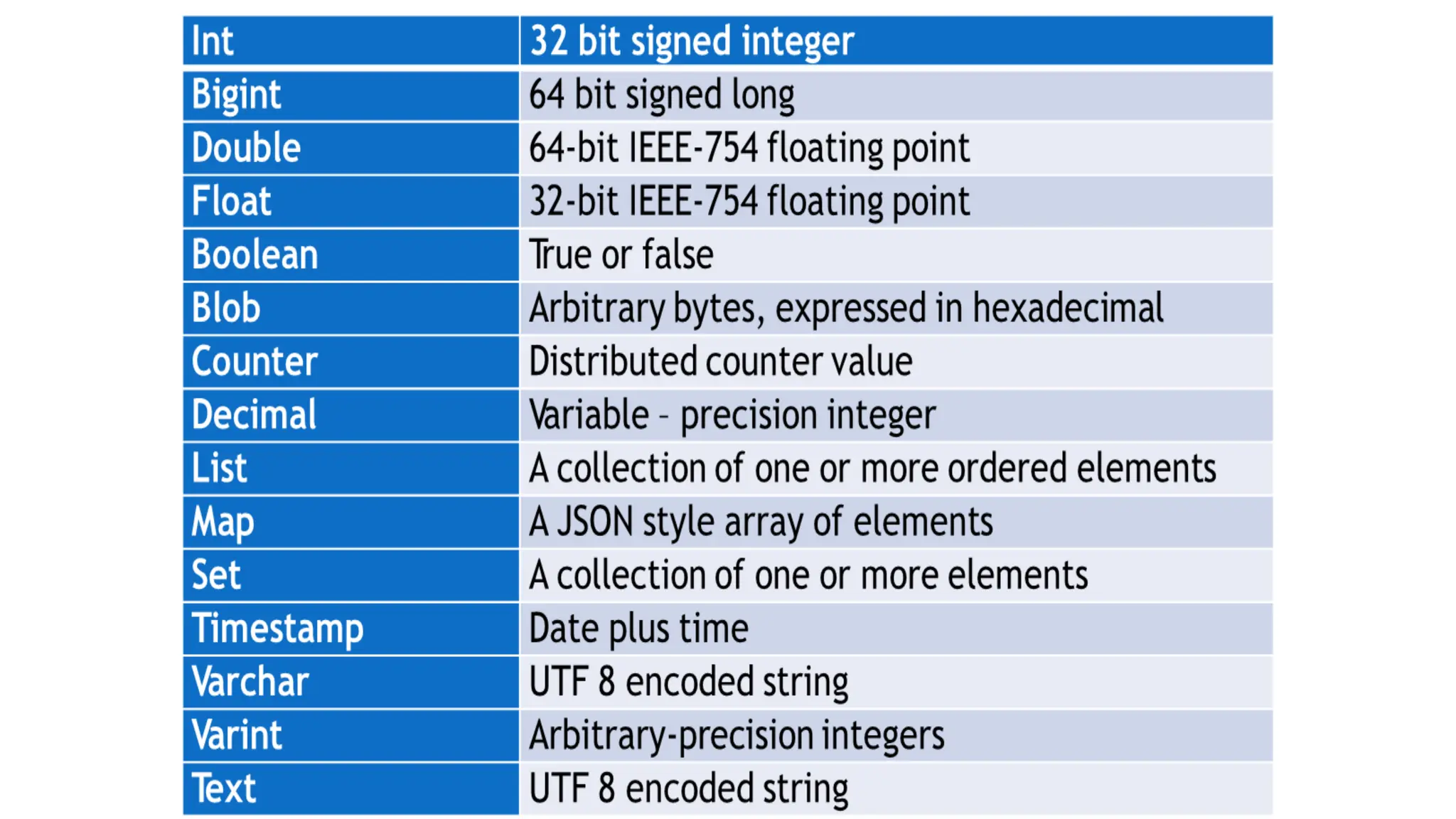
Apache Cassandra, originally developed at Facebook for inbox search and open-sourced in 2008, is a highly scalable and fault-tolerant distributed column-oriented database designed for high availability and no single point of failure. Its architecture is based on Amazon's Dynamo and Google's Bigtable, featuring a masterless design that allows all nodes to operate equally while efficiently managing large volumes of structured data. Cassandra supports various data formats and provides functionalities like fast writes, flexible data distribution, and tunable consistency, making it suitable for applications in messaging, IoT, retail, and social media analytics.































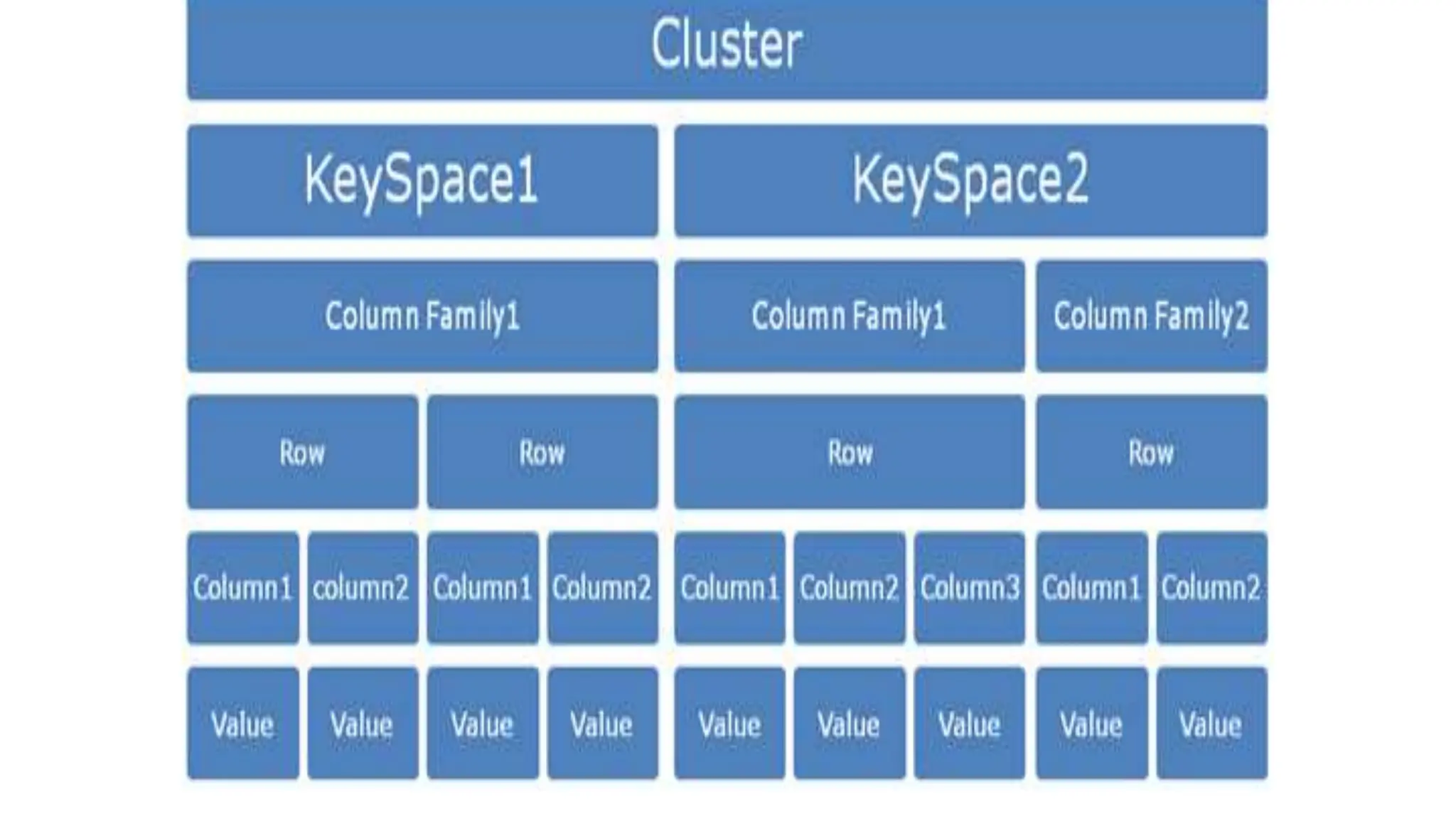
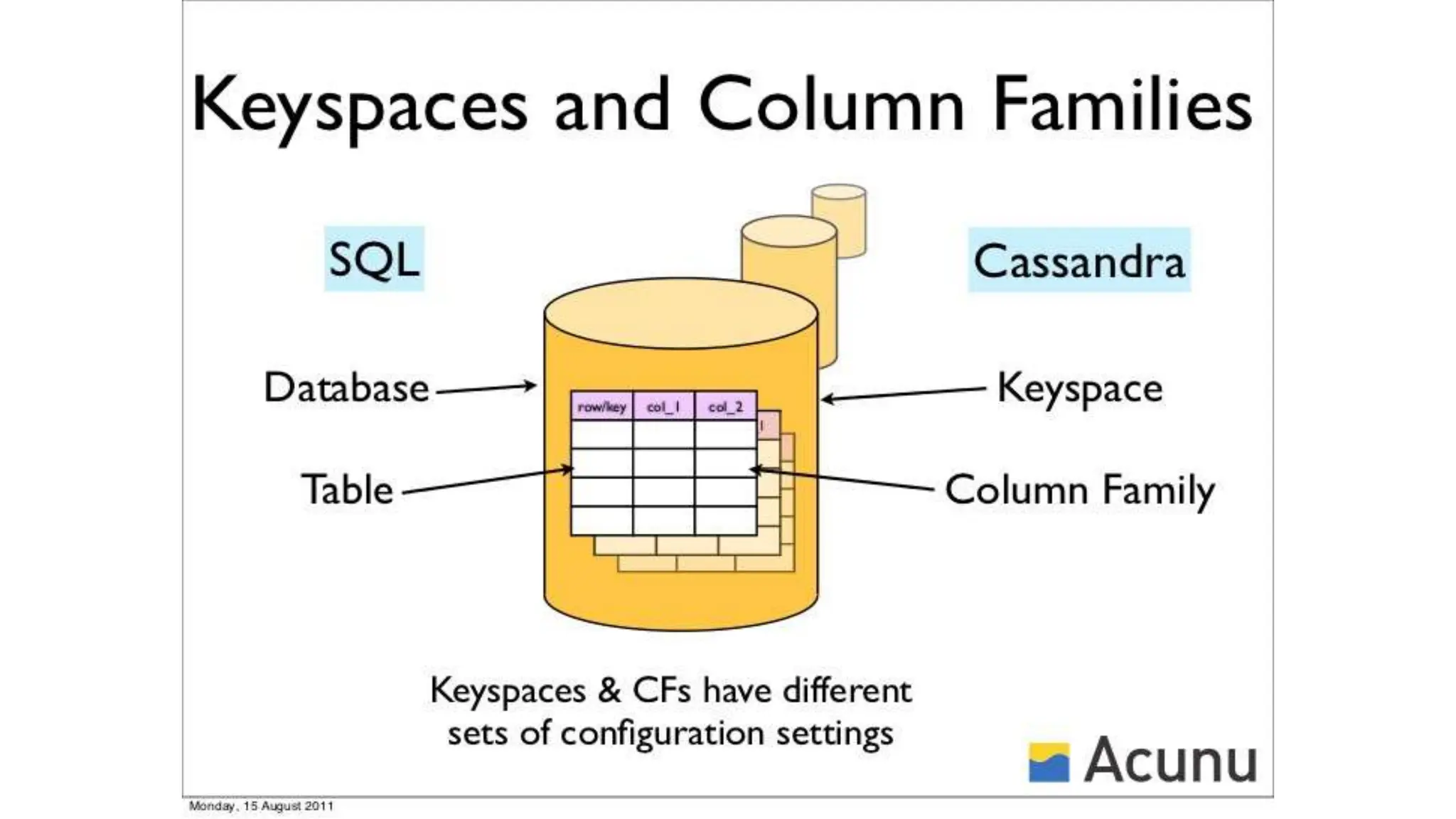
![KEYSPACES (Database [Namespace])
• It is a container to hold application data like RDBMS.
• Used to group column families together.
• Each cluster has one keyspace/application or per
node.
• A keyspace (or key space) in a NoSQL data store is an
object that holds together all column families of a
design.
• It is the outermost grouping of the data in the data
store.](https://image.slidesharecdn.com/chapter6-240423150043-d223f5bd/75/cybersecurity-notes-for-mca-students-for-learning-48-2048.jpg)












![Collections List
• T
o alter the schema of the table “student_info” to
add a list column “language”.
ALTER TABLE student_info ADD language list<text>;
UPDATE student_info SET language = language + ['Hindi,
English'] WHERE RollNo=1;](https://image.slidesharecdn.com/chapter6-240423150043-d223f5bd/75/cybersecurity-notes-for-mca-students-for-learning-63-2048.jpg)