Downloaded 90 times






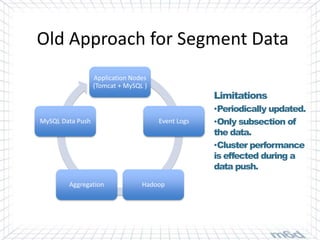




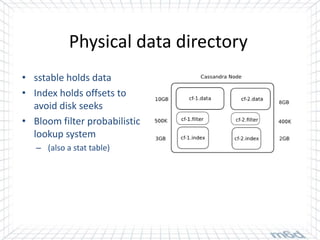
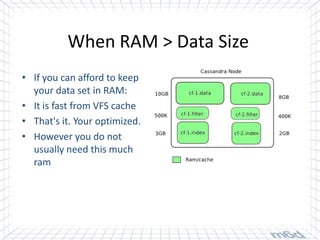
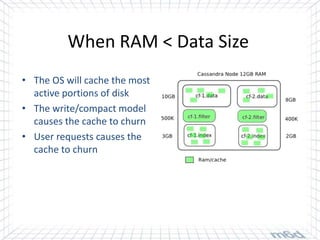


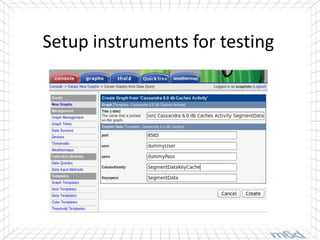
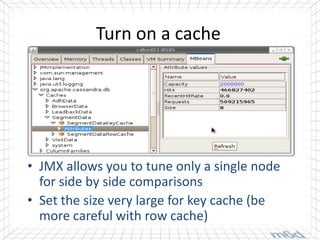
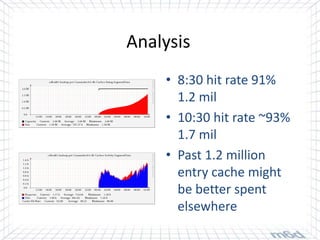










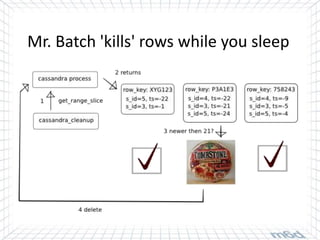

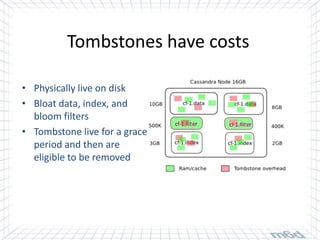




Cassandra is used for real-time bidding in online advertising. It processes billions of bid requests per day with low latency requirements. Segment data, which assigns product or service affinity to user groups, is stored in Cassandra to reduce calculations and allow users to be bid on sooner. Tuning the cache size and understanding the active dataset helps optimize performance.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






