Download as PDF, PPTX









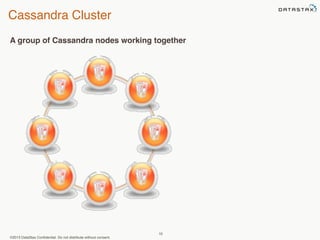


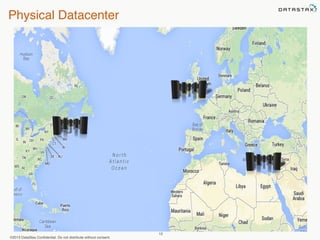
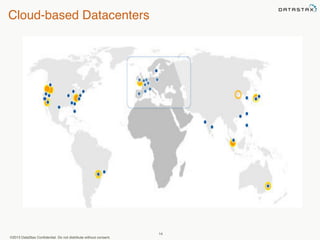
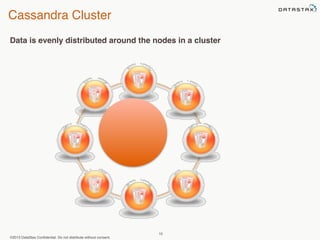
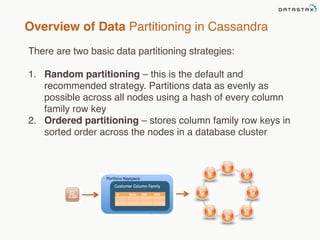


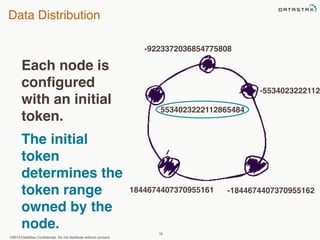
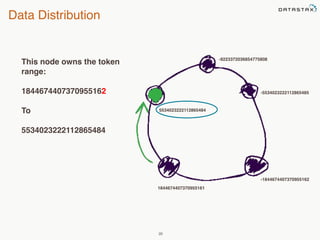
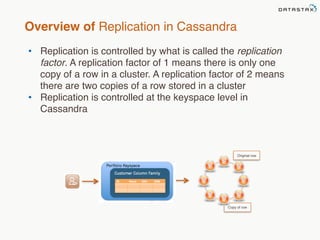
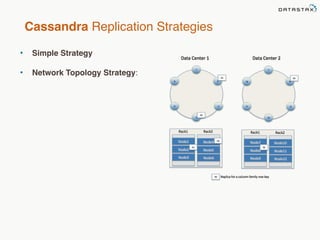
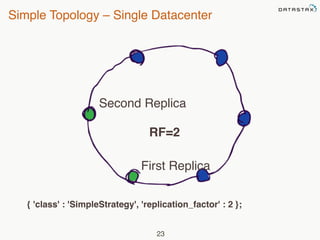
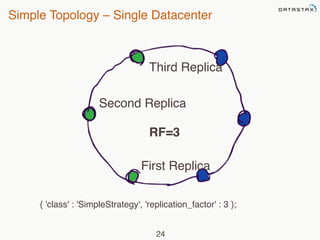
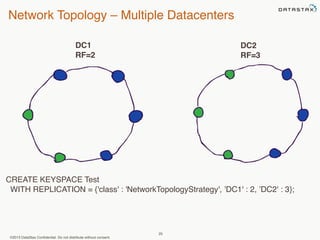
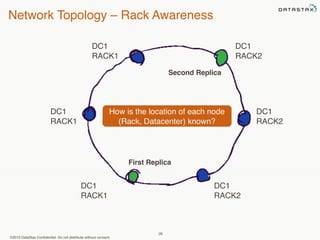




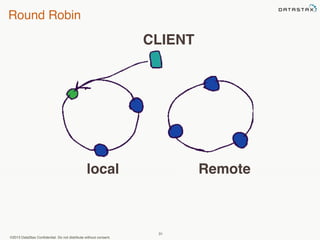
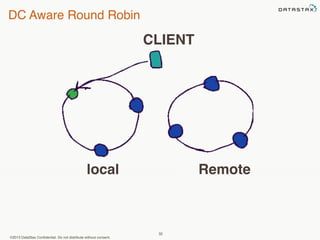
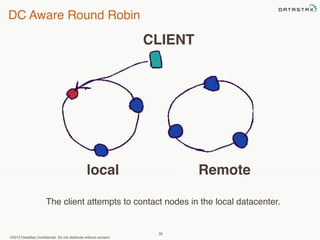
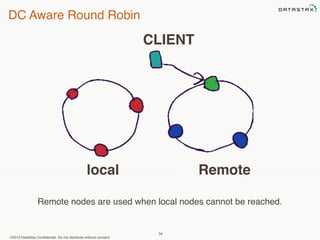
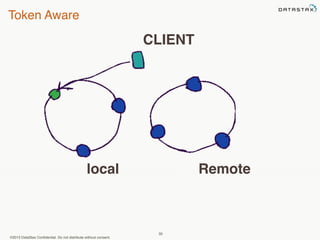

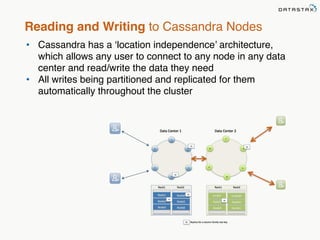
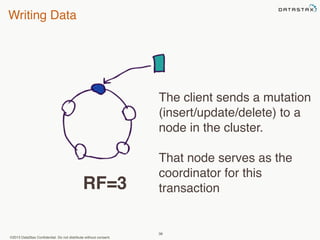

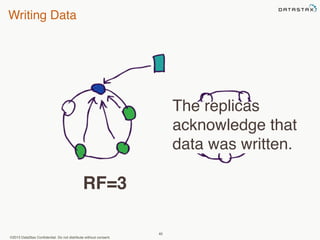
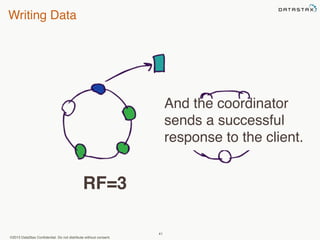
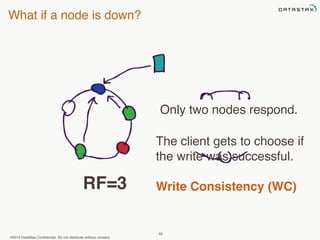
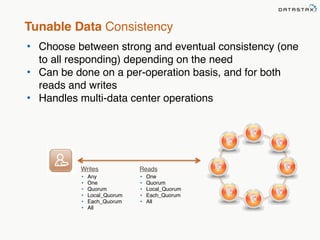

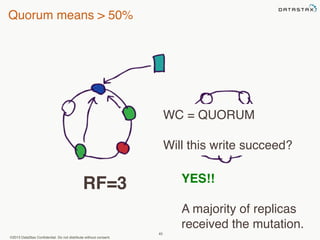
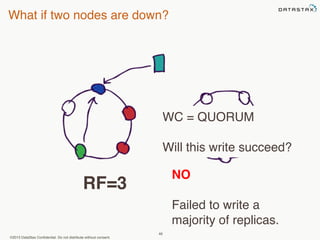
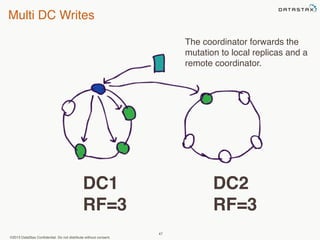
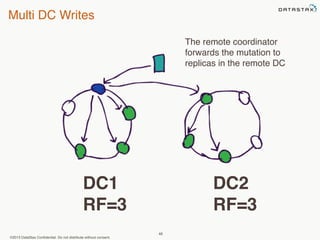
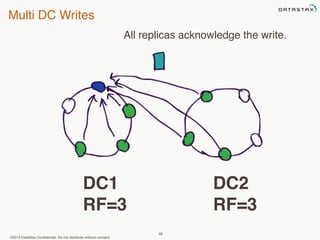
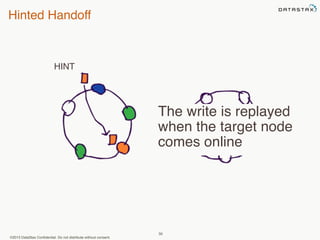
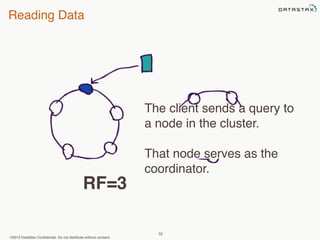
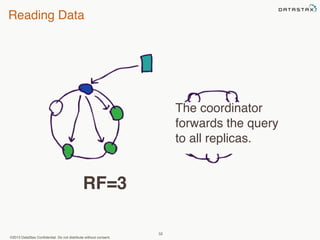
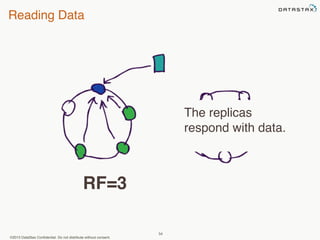
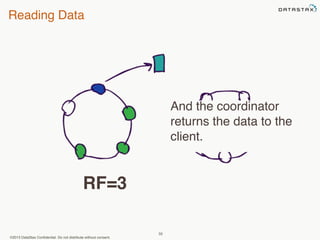
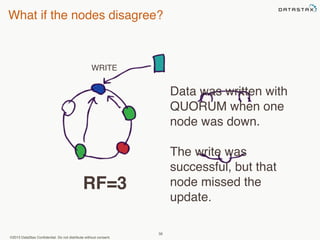
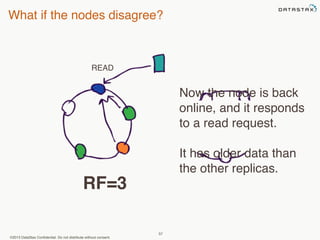
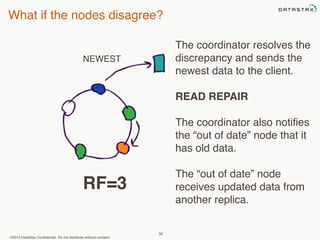
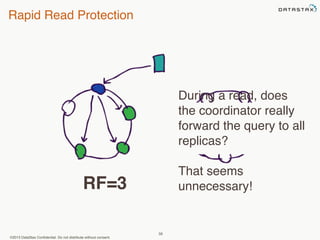
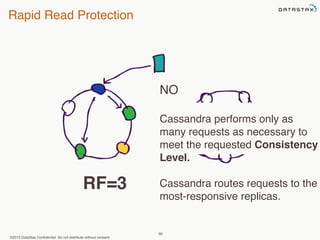
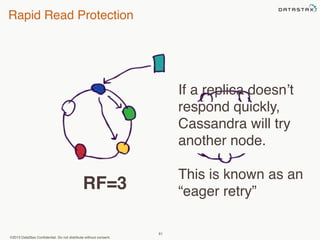
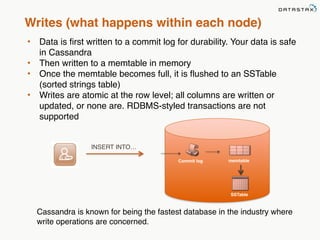
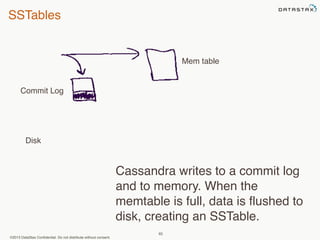
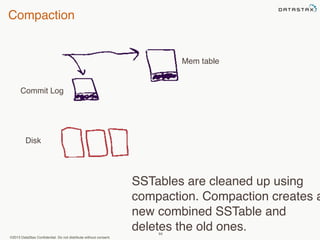
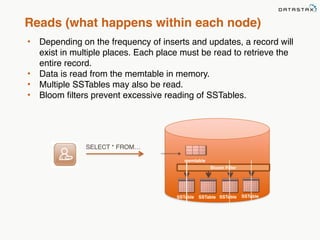





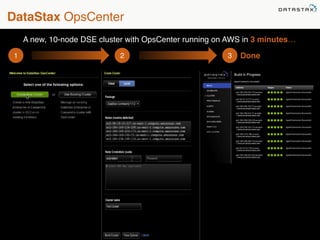
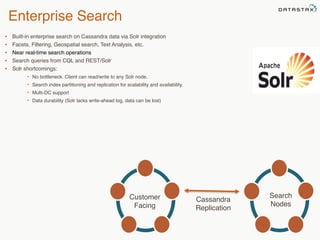

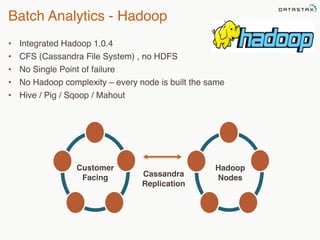

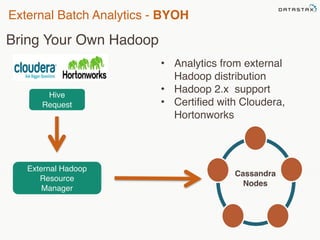

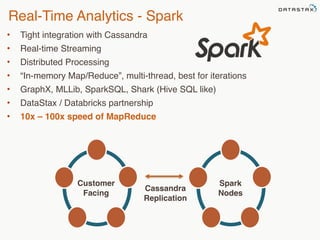
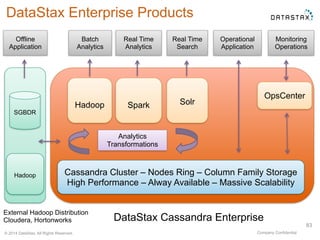



This document provides an overview of Apache Cassandra and Datastax Enterprise. It discusses what Cassandra is, how it is used across different industries, its key features like scalability and availability. It also covers Cassandra terminology, data distribution, replication strategies, consistency levels, and how reads and writes work in Cassandra.






























































































