This document provides an overview of BERT (Bidirectional Encoder Representations from Transformers) and how it works. It discusses BERT's architecture, which uses a Transformer encoder with no explicit decoder. BERT is pretrained using two tasks: masked language modeling and next sentence prediction. During fine-tuning, the pretrained BERT model is adapted to downstream NLP tasks through an additional output layer. The document outlines BERT's code implementation and provides examples of importing pretrained BERT models and fine-tuning them on various tasks.


![• From n-grams to fastText: (pre-trained) word vectors
• N-gram
• Non-compressed bunch of words
• Word2vec [Mikolov et al., 2013]
• Skip-gram & CBOW
• Large vocab set projected to a smaller space, with the constraints
• GloVe [Pennington et al., 2014]
• Co-occurrence matrix combined
• fastText [Bojanowski et al., 2016]
• Subword information
A short overview on recent LMs](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-3-320.jpg)
![• Contextualized word embedding
• ELMo [Peters et al., 2018]
A short overview on recent LMs
image from https://jalammar.github.io/illustrated-bert/](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-4-320.jpg)
![• And how transformers engaged in:
• All you need is attention! [Vaswani et al., 2017]
• OpenAI GPT [Radford et al., 2018] (image source)
A short overview on recent LMs](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-5-320.jpg)


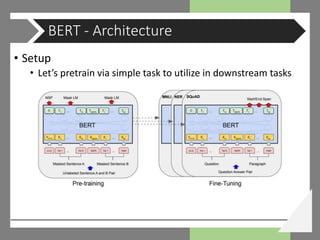
![• Setup
• Input: concatenation of two segments (sequences of tokens)
𝑥1, … , 𝑥 𝑁 and 𝑦1, … , 𝑦 𝑀
• 𝐶𝐿𝑆 𝑥1, … , 𝑥 𝑁 𝑆𝐸𝑃 𝑦1, … , 𝑦 𝑀 [𝑆𝐸𝑃]
• [CLS] trained to represent the value for classification
• [SEP] denotes the separating point between the sequences
• Each segment – equal to or more than one natural ‘sentences’
• 𝑁 + 𝑀 < 𝑇 for 𝑇 the parameter
that controls the maximum
sequence length
BERT - Architecture
(BERT original paper)](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-9-320.jpg)





![• Hugging Face BERT has two options:
• Basic (punctuation splitting, lower casing, etc.)
• WordPiece
• Tokenizes a piece of text into its word pieces
• A greedy longest-match-first algorithm to perform tokenization using
the given vocabulary
• e.g., input = “unaffable” / output = [“un”, “##aff”, “##able”]
• Args: text
• A single token or whitespace separated tokens which should have
already been passed through `BasicTokenizer`
• Returns:
• A list of wordpiece tokens.
BERT - Featurization](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-15-320.jpg)


![• Code for WPM [Sennrich et al., 2015]
BERT - Featurization](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-18-320.jpg)


![• BERT learns how to represent the context
• via a hard training with two simple tasks
• Masked LM (MLM)
• Cloze task [Taylor, 1953] – filling in the blank
• Similar to what SpecAugment [Park et al., 2019] does?
• Next sentence prediction (NSP)
• Checks the relevance between the sentences
BERT – Training objectives](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-21-320.jpg)
![• Masked language model (MLM)
• A random sample of the tokens in the input sequence is
selected and replaced with the special token [MASK]
• MLM objective: cross-entropy loss on predicting the masked
tokens
• BERT uniformly selects 15% of input tokens for possible replacement
• Of the selected tokens, 80% are replaced with [MASK]
• 10% left unchanged
• 10% replaced by a
randomly selected
vocabulary token
BERT – Training objectives
(THESE code from Google BERT)](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-22-320.jpg)
![• Masked language model (MLM)
• masked_lm_labels: (`optional`) ``torch.LongTensor`` of shape
``(batch_size, sequence_length)``:
• Labels for computing the masked language modeling loss
• Indices should be in ``[-1, 0, ..., config.vocab_size]``
• Tokens with indices set to ``-1`` are ignored (masked), the loss is only
computed for the tokens with labels in ``[0, ..., config.vocab_size]``
• Example:
BERT – Training objectives](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-23-320.jpg)




![• Next sentence prediction (NSP)
• next_sentence_label: (`optional`) ``torch.LongTensor`` of
shape ``(batch_size,)``:
• Labels for computing the next sequence prediction (classification)
loss. Input should be a sequence pair (see ``input_ids`` docstring)
• Indices should be in ``[0, 1]``.
• ``0`` indicates sequence B is a continuation of sequence A
• ``1`` indicates sequence B is a random sequence.
• Example:
BERT – Training objectives](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-28-320.jpg)




















![• Fine-tuning example
• e.g., run_glue.py: Fine-tuning on GLUE tasks [Wang et al.,
2019] for sequence classification (and right on MRPC task)
BERT - Fine-tuning](https://image.slidesharecdn.com/1909bert-whyandhowdist-190927095920/85/1909-BERT-why-and-how-CODE-SEMINAR-49-320.jpg)
























![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)
























![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)



































