Download as PDF, PPTX






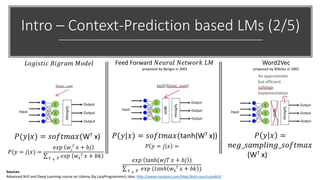
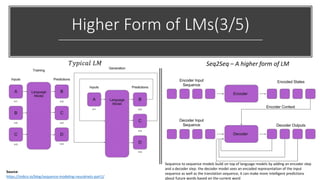

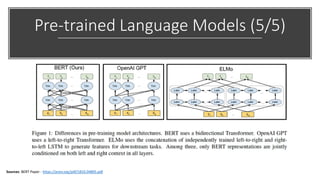
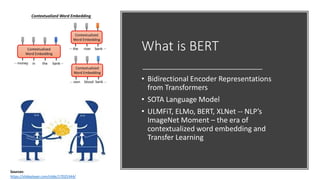
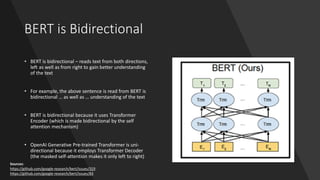
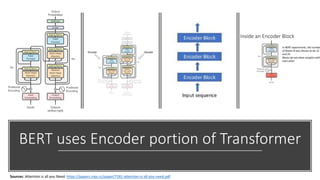


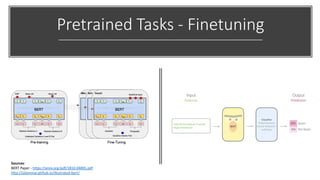







The document discusses BERT, a state-of-the-art language model that utilizes a bidirectional transformer architecture for multi-task learning. Key topics include the importance of better text representation, the introduction of transfer learning, and how BERT improves upon traditional language models through tasks like masked language modeling and next sentence prediction. It also highlights various NLP applications of BERT and the foundational concepts behind its design and capabilities.

![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







