Downloaded 343 times





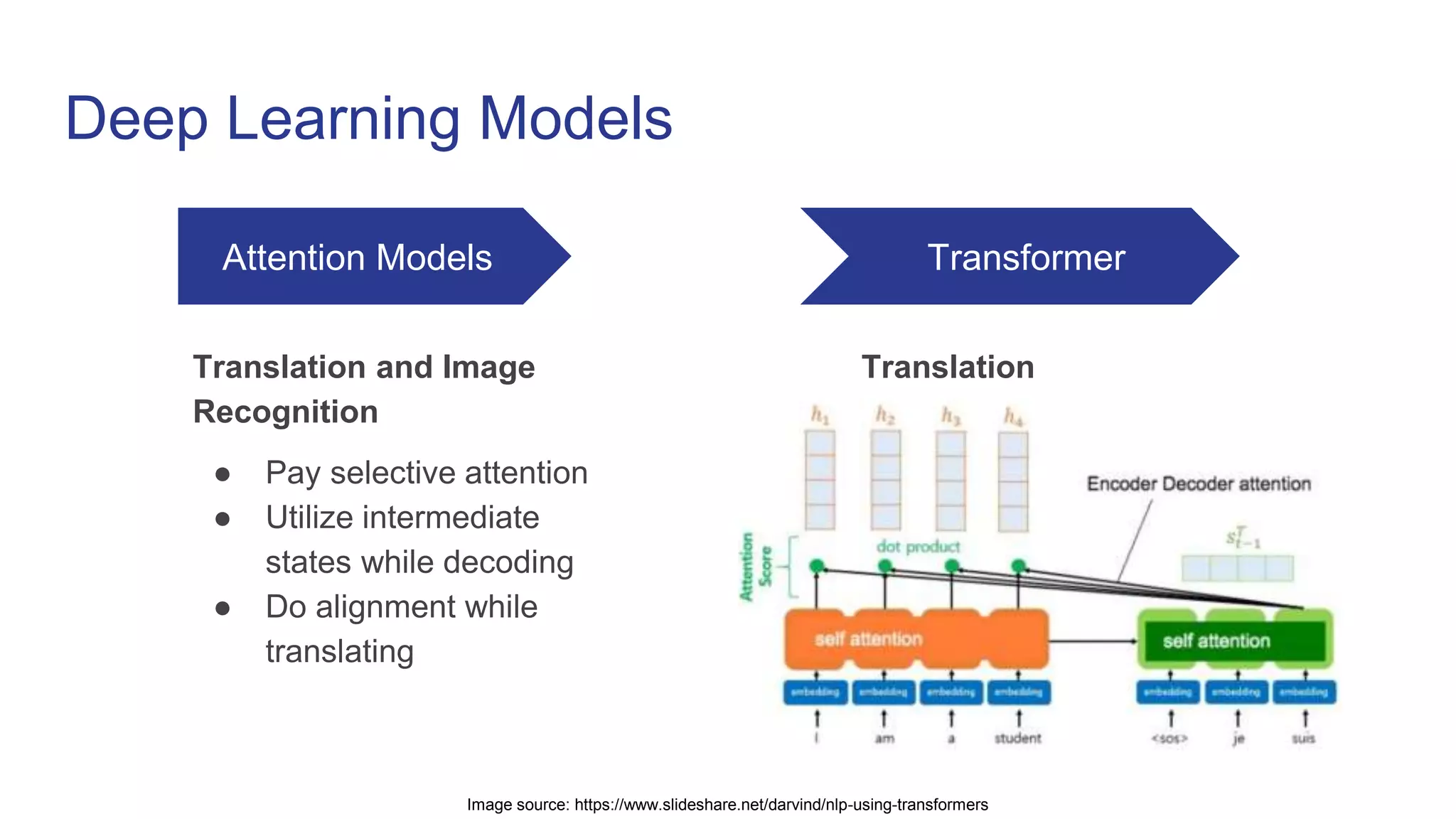








This document provides an overview of natural language processing (NLP) and the evolution of its techniques from symbolic and statistical methods to neural networks and deep learning. It explains the transformer architecture, focusing on its use of self-attention for sequence-to-sequence tasks and its advantages in handling long-range dependencies. The document also highlights challenges such as context fragmentation due to fixed-length input segments and discusses future directions, including transformer XL and BERT.












![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)











![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)


