Download as PDF, PPTX








![Vector representation breakthroughs
• Can we learn lower-dimensional word embeddings that capture some
meaning?
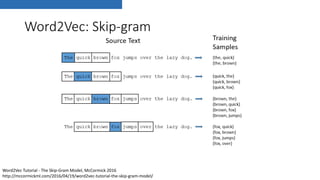
• Word2Vec
• Simple neural net Skip-Gram/CBOW model
• T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient EsKmaKon of Word
RepresentaKons in Vector Space,” arXiv:1301.3781 [cs], Jan. 2013.
• GloVe
• Word-word co-occurrence matrix
• J. Pennington, R. Socher, and C. Manning, “Glove: Global Vectors for Word
RepresentaKon,” 2014, pp. 1532–1543.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-18-320.jpg)
![From vocabulary size V to hidden layer size N
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” arXiv:1301.3781 [cs], Jan. 2013.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-20-320.jpg)


![Attention
K. M. Hermann et al., “Teaching Machines to Read and
Comprehend,” arXiv:1506.03340 [cs], Jun. 2015.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-26-320.jpg)
![Attention
D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine
Translation by Jointly Learning to Align and Translate,”
arXiv:1409.0473 [cs, stat], Sep. 2014.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-27-320.jpg)

![Transformers
• First sequence transduc.on
models with a4en.on only
• No RNNs or convolu.ons, just
posi.onal encodings
àlower computa.onal complexity
+ no sequen.al opera.ons
• A4en.on mechanisms specialise
on different task and capture
seman.c + syntac.c structure
A. Vaswani et al., “Attention Is All You Need,” arXiv:1706.03762 [cs], Jun. 2017.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-29-320.jpg)
![Transformers: co-reference resolu0on
A. Vaswani et al., “Attention Is All You Need,” arXiv:1706.03762 [cs], Jun. 2017.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-30-320.jpg)



![BERT & Friends: recent innovations
• Language modelling and fine-tuning
• ULMFit (J. Howard and S. Ruder, “Universal Language Model Fine-tuning for Text ClassificaDon,”
arXiv:1801.06146 [cs, stat], Jan. 2018)
• ELMo (M. E. Peters et al., “Deep contextualized word representaDons,” arXiv:1802.05365 [cs], Feb.
2018)
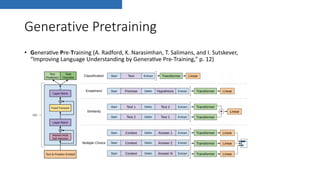
• GPT (A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving Language
Understanding by GeneraDve Pre-Training,” p. 12)
• BERT (J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep BidirecDonal
Transformers for Language Understanding,” arXiv:1810.04805 [cs], Oct. 2018)](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-35-320.jpg)
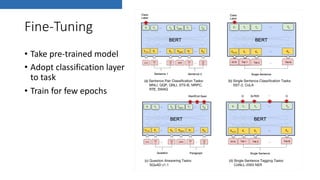
![Fine-tuning
• ULMFit (J. Howard and S. Ruder, “Universal Language Model Fine-tuning for Text
Classification,” arXiv:1801.06146 [cs, stat], Jan. 2018)](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-36-320.jpg)
![Contextual embeddings
• ELMo (M. E. Peters et al., “Deep contextualized word representations,” arXiv:1802.05365 [cs], Feb.
2018)](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-37-320.jpg)
![Contextual embeddings
• ELMo (M. E. Peters et al., “Deep contextualized word representa;ons,” arXiv:1802.05365 [cs], Feb.
2018)
• Language model next token predic;on task
• Bi-Direc;onal LSTM looking at en;re sentence
• Extract contextual embedding from hidden states](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-38-320.jpg)
![BERT
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding,” arXiv:1810.04805 [cs], Oct. 2018.
• Bi-Directional model achieved through masking
• Cloze task
• Sentence/Phrase switching](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-40-320.jpg)






![References
• J. Pennington, R. Socher, and C. Manning, “Glove: Global Vectors for Word Representa@on,” 2014
• T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Es@ma@on of Word Representa@ons in Vector Space,” arXiv:1301.3781 [cs], Jan. 2013.
• A. Vaswani et al., “APen@on Is All You Need,” arXiv:1706.03762 [cs], Jun. 2017.
• J. Howard and S. Ruder, “Universal Language Model Fine-tuning for Text Classifica@on,” arXiv:1801.06146 [cs, stat], Jan. 2018.
• M. E. Peters et al., “Deep contextualized word representa@ons,” arXiv:1802.05365 [cs], Feb. 2018.
• A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving Language Understanding by Genera@ve Pre-Training,”.
• J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirec@onal Transformers for Language Understanding,” arXiv:1810.04805 [cs], Oct.
2018.
• Alammar, Jay. n.d. “The Illustrated BERT, ELMo, and Co. (How NLP Cracked Transfer Learning).” Accessed May 22, 2019. hPps://jalammar.github.io/illustrated-bert/.
• “BePer Language Models and Their Implica@ons.” 2019. OpenAI. February 14, 2019. hPps://openai.com/blog/bePer-language-models/.
• “NLP’s ImageNet Moment Has Arrived.” 2018. Sebas@an Ruder. July 12, 2018. hPp://ruder.io/nlp-imagenet/.
• “Transformer: A Novel Neural Network Architecture for Language Understanding.” n.d. Google AI Blog (blog). Accessed May 22, 2019.
hPp://ai.googleblog.com/2017/08/transformer-novel-neural-network.html.](https://image.slidesharecdn.com/deeplearningnlpfinalexport-190522114401/85/Should-we-be-afraid-of-Transformers-49-320.jpg)

The lecture discusses the evolution of deep learning and its impact on natural language processing (NLP), emphasizing the significance of transformers in achieving state-of-the-art results. It raises ethical concerns regarding AI safety, commercialization, and the potential for an AI cold war, urging for responsible collaboration in research. Recent innovations like BERT have revolutionized language modeling, highlighting the ongoing improvements and challenges in building effective AI systems.















































