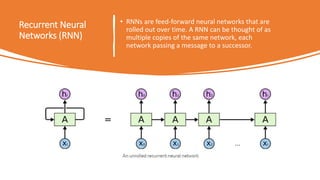
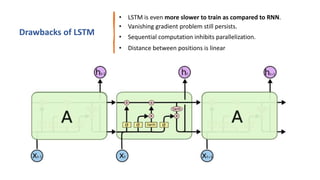
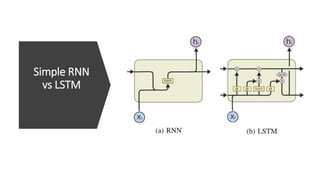
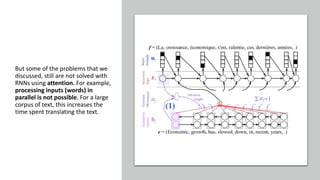
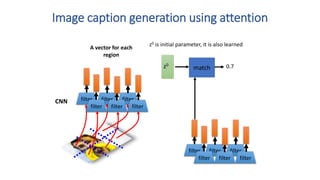
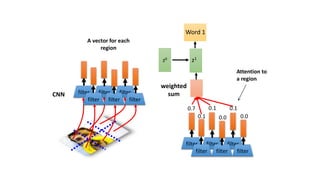
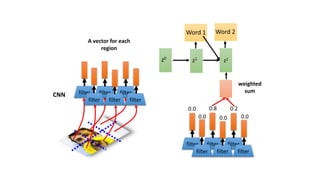
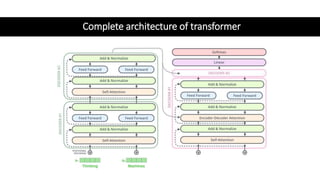
1) Transformers use self-attention to solve problems with RNNs like vanishing gradients and parallelization. They combine CNNs and attention.
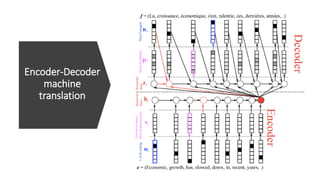
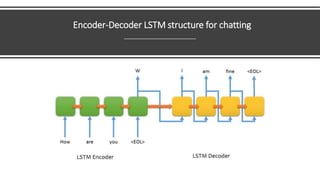
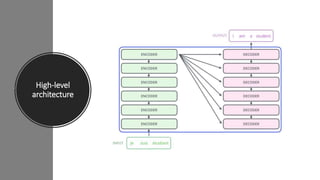
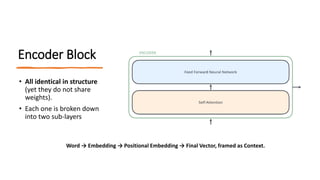
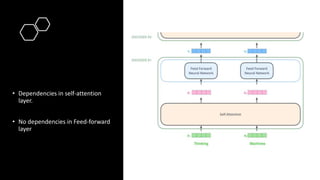
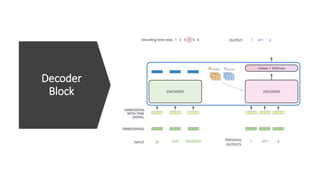
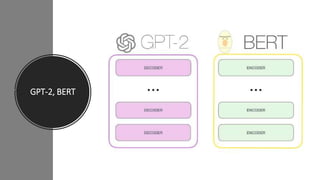
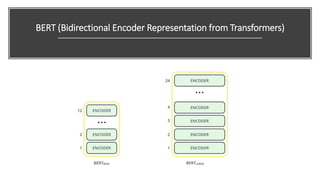
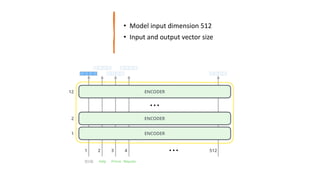
2) Transformers have encoder and decoder blocks. The encoder models input and decoder models output. Variations remove encoder (GPT) or decoder (BERT) for language modeling.
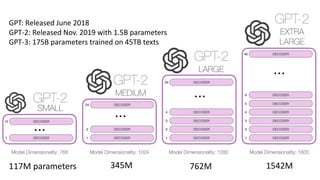
3) GPT-3 is a large Transformer with 175B parameters that can perform many NLP tasks but still has safety and bias issues.
















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)











































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















