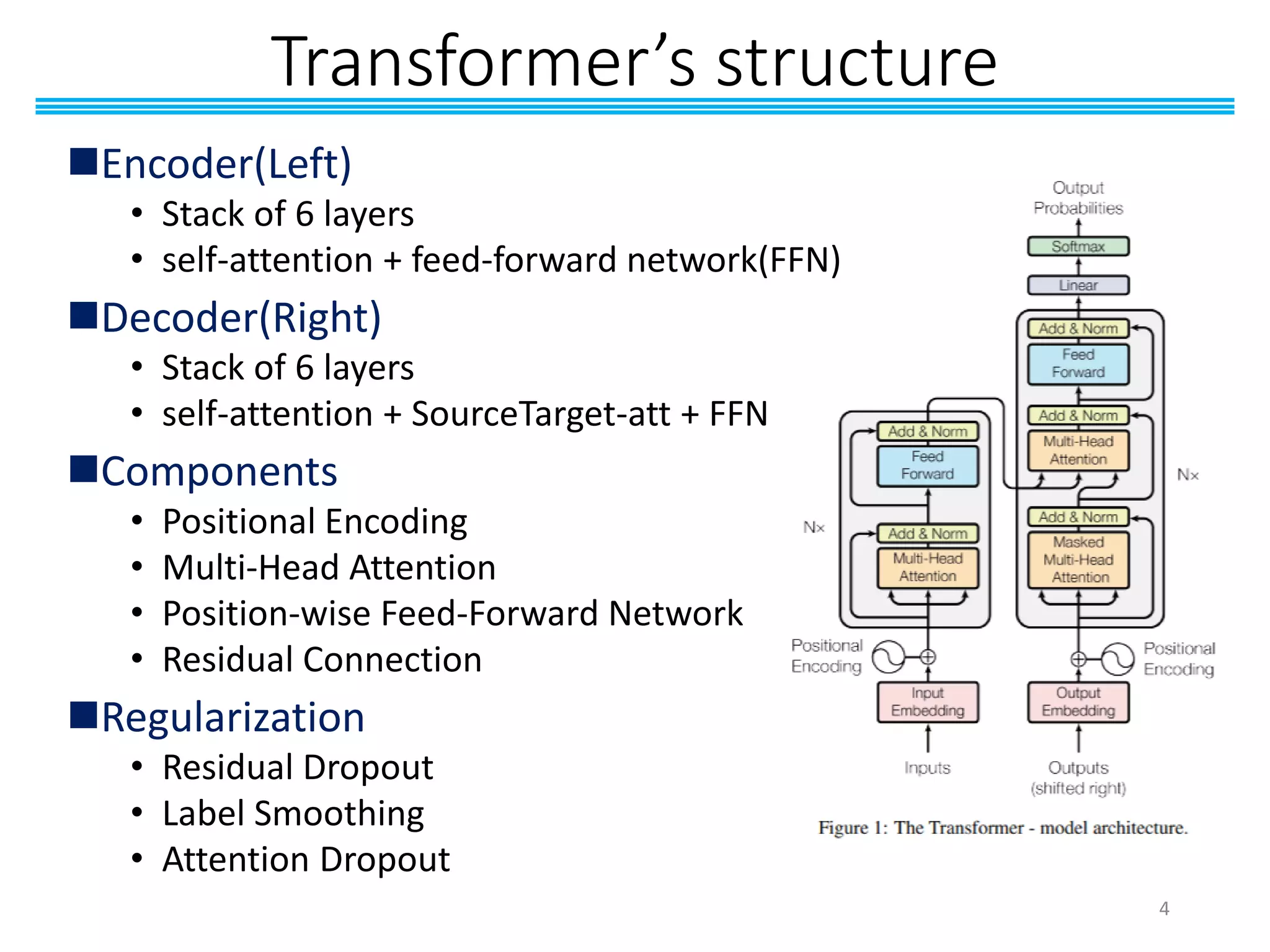
The document discusses the introduction of transformers and their advanced models like BERT, emphasizing the importance of experiments in NLP and deep learning. It outlines the architecture of transformers, including the encoder and decoder structures, attention mechanisms, and the significance of multi-head attention. Additionally, it provides references for further reading and details the motivations behind various components of the transformer model.


![What is “Transformer”?
◼Paper
• “Attention Is All You Need”[1]
◼Motivation
• Build a model with sufficient representation power for difficult
task(←translation task in the paper)
• Train a model efficiently in parallel(RNN cannot train in parallel)
◼Methods and Results
• Architecture with attention mechanism without RNN
• Less time to train
• Achieve great BLEU score in the translation task
◼Application
• Use Encoder that have acquired strong representation power
for other tasks by fine-tuning.
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
3](https://image.slidesharecdn.com/trasformerintroduuction-191103094052/75/Transformer-Introduction-Seminar-Material-3-2048.jpg)
![Positional Encoding
◼Proposed in “End-To-End Memory Network”[1]
◼Motivation
• Add information about the position of the words in the
sentences(←transformer don’t contain RNN and CNN)
𝑑 𝑚𝑜𝑑𝑒𝑙: the dim. of word embedding
𝑃𝐸(𝑝𝑜𝑠,2𝑖) = 𝑠𝑖𝑛(
𝑝𝑜𝑠
100002𝑖/𝑑 𝑚𝑜𝑑𝑒𝑙
)
𝑃𝐸(𝑝𝑜𝑠,2𝑖+1) = 𝑐𝑜𝑠(
𝑝𝑜𝑠
100002𝑖/𝑑 𝑚𝑜𝑑𝑒𝑙
)
Where 𝑝𝑜𝑠 is the position and 𝑖 is the dimension.
[1] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. "End-to-end memory networks." Advances in neural information processing systems. 2015.
5](https://image.slidesharecdn.com/trasformerintroduuction-191103094052/75/Transformer-Introduction-Seminar-Material-5-2048.jpg)
![2 Types of Attention
• Additive Attention[1]
𝐴𝑡𝑡 𝐻
= softmax 𝑊𝐻 + 𝑏
• Dot-Product Attention[2,3]
𝐴𝑡𝑡 𝑄, 𝐾, 𝑉
= softmax 𝑄𝐾 𝑇 𝑉
[1] Bahdanau, Dzmitry, et al. “Neural Machine Translation by Jointly Learning to Align an Translate.” ICLR, 2015.
[2] Miller, Alexander, et al. “Key-Value Memory Networks for Directly Reading Documents.” EMNLP, 2016.
[3] Daniluk, Michal, et al. “Frustratingly Short Attention Spans in Neural Language Modeling.” ICLR, 2017.
In Transformer, Dot-Product Attention is Used.
7](https://image.slidesharecdn.com/trasformerintroduuction-191103094052/75/Transformer-Introduction-Seminar-Material-7-2048.jpg)
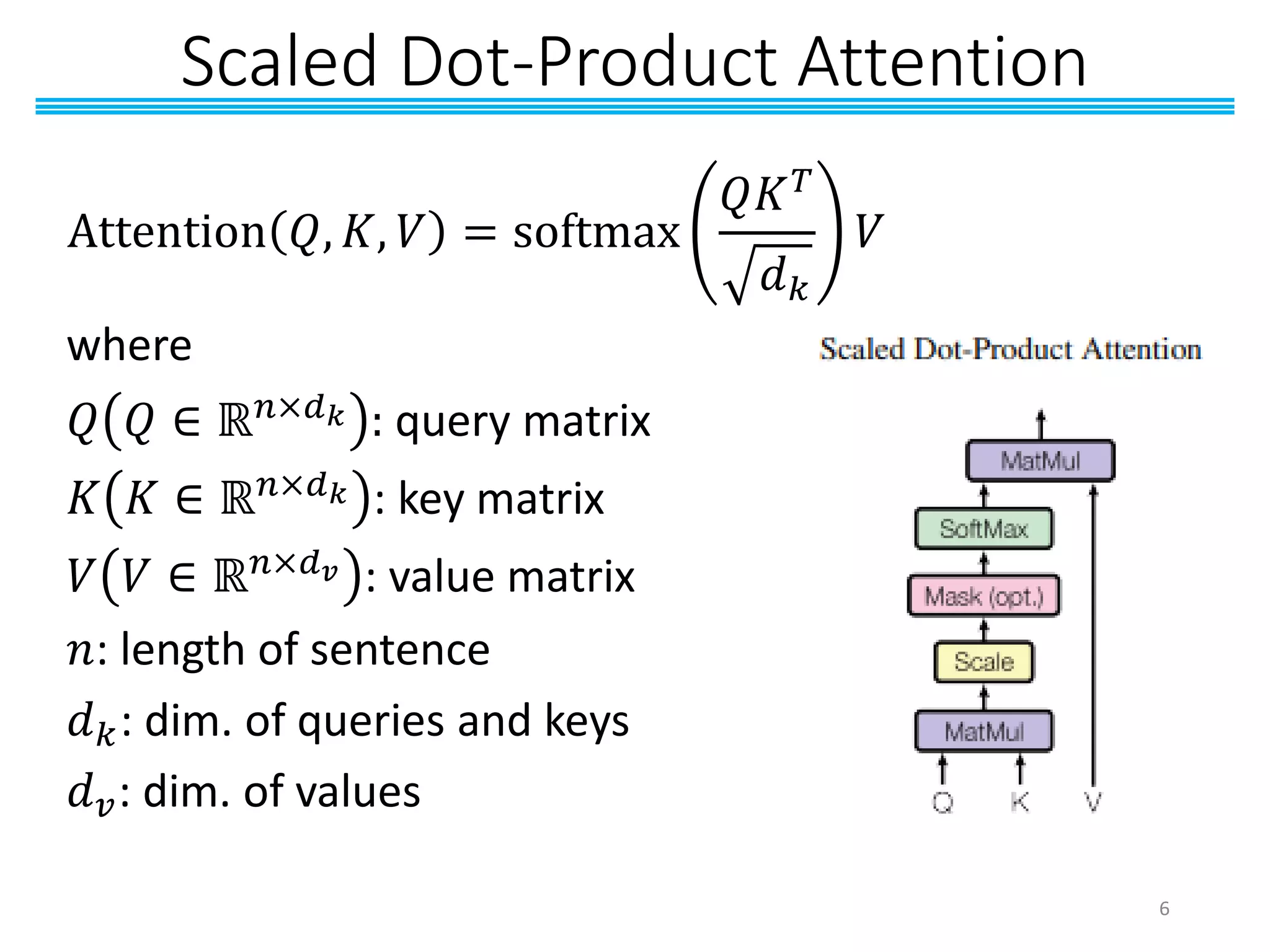
![Why Use Scaled Dot-Product Attention?
◼Dot-Product Attention is faster and more
efficient than Additive Attention.
• Additive Attention use a feed-forward network as the
compatibility function.
• Dot-Product Attention can be implemented using highly
optimized matrix multiplication code.
◼Use scaling term
1
𝑑 𝑘
to make Dot-Product
Attention high performance with large 𝑑 𝑘
• Additive Attention outperforms Dot-Product Attention
without scaling for larger values of 𝑑 𝑘 [1]
[1] Britz, Denny, et al. “Massive Exploration of Neural Machine Translation Architectures." EMNLP, 2017.
8](https://image.slidesharecdn.com/trasformerintroduuction-191103094052/75/Transformer-Introduction-Seminar-Material-8-2048.jpg)


![Why Multi-Head Attention?
Experiments(In Table 3 (a)) shows that multi-head
attention model outperforms single-head attention.
“Multi-Head Attention allows the model to jointly
attend to information from different representation
subspaces at difference positions.”[1]
Multi-Head Attention seems
ensemble of attention.
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
11](https://image.slidesharecdn.com/trasformerintroduuction-191103094052/75/Transformer-Introduction-Seminar-Material-11-2048.jpg)






![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)
























![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)






































