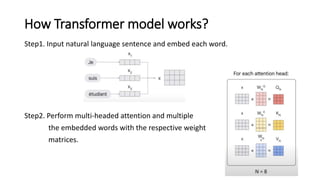
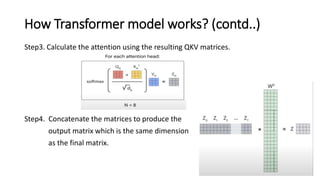
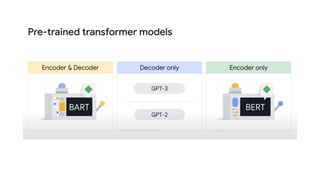
The document discusses transformer and BERT models. It provides an overview of attention models, the transformer architecture, and how transformer models work. It then introduces BERT, explaining how it differs from transformer models in that it does not use a decoder and is pretrained using two unsupervised tasks. The document outlines BERT's architecture and embeddings. Pretrained BERT models are discussed, including DistilBERT, RoBERTa, ALBERT and DeBERTa.





![BERT Embeddings
Note –
• Word Piece Embeddings(2016) – 30,000 token vocabulary
• The first token of every sequence is always a special classification token ([CLS])
• The sentences are differentiated in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned
embedding to every token indicating whether it belongs to sentence A or sentence B.
• Bert is designed to process the input sequences up to length of 512 tokens](https://image.slidesharecdn.com/bert-231009094817-c88865d4/85/Bert-pptx-11-320.jpg)






![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)




















![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)