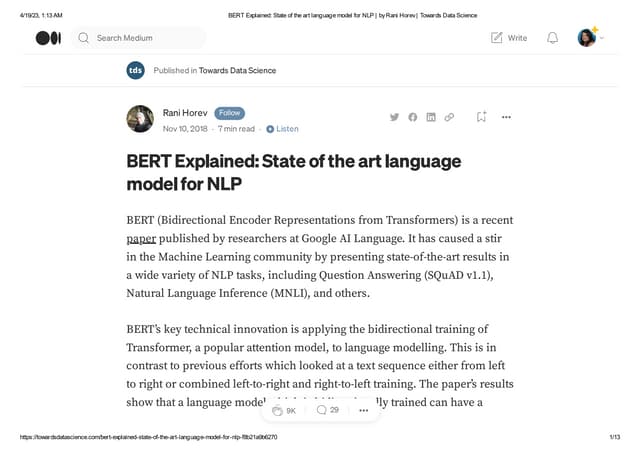
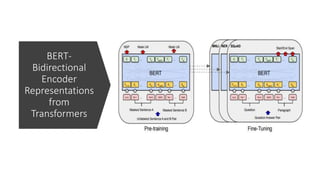
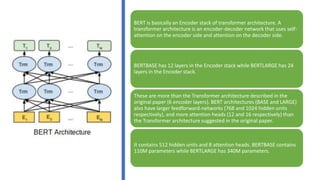
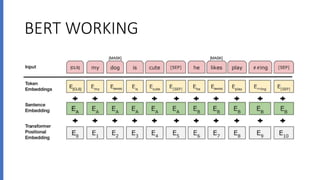
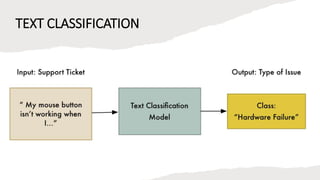
The document discusses BERT (Bidirectional Encoder Representations from Transformers), a powerful pre-trained language model developed by Google in 2018 for natural language processing tasks. It describes BERT's transformer architecture with an encoder stack and its pre-training using a masked language modeling task. The document then explains how BERT can be fine-tuned on a downstream text classification task by adding a classification layer to the encoder output and using a softmax layer to classify texts into categories.




![Masked Language Model:
• In this NLP task, we replace 15% of words
in the text with the [MASK] token.
• The model then predicts the original words
that are replaced by [MASK] token.
• Beyond masking, the masking also mixes
things a bit in order to improve how the
model later for fine-tuning because [MASK]
token created a mismatch between training
and fine-tuning.
• In this model, we add a classification layer
at the top of the encoder input. We also
calculate the probability of the output using
a fully connected and a softmax layer.](https://image.slidesharecdn.com/bertmodulefortextclassification-230513184828-361d94b7/85/BERT-MODULE-FOR-TEXT-CLASSIFICATION-pptx-7-320.jpg)





![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)