Human Interface Laboratory
StyleKQC:A Style-Variant Paraphrase Corpus
for Korean Questions and Commands
(Accepted at LREC 2022)
2022. 06. 16, Presented @MODUPOP
Won Ik Cho, Sangwhan Moon, Jong In Kim,
Seok Min Kim, Nam Soo Kim
2.
Contents
• 들어가며
자연어데이터 만들기?
Motivation
관련 연구
• Style transfer 데이터셋의 구축
자연어 쿼리 작성하기
쿼리를 격식있는 문장으로 변형하기
격식있는 문장들을 비격식 표현으로 변환하기
최종 코퍼스 구축
• 간단한 실험 결과
어떤 태스크들이 가능한가?
실제 구현 및 결과
오류 분석!
• 정리 & 앞으로..?
1
3.
들어가며
• 자연어 데이터만들기?
자연어
• 자연어로 구성된
• 자연어 분석을 위한
• 자연어를 표현할 수 있는 형태의
데이터
• 저장 가능한
• 활용 가능한
• 변형/발전 가능한 내용
만들기
• 무슨 예산으로?
• 누가?
• 어떤 기준으로?
2
4.
들어가며
• Motivation
Paraphrasing
•사전적 의미: 같은 말을 여러 가지 다른 표현으로 바꾸는 것
• 실용적 목적:
– 다른 글로 같은 내용을 전달할 수 있다(!)
– Text data augmentation의 유용한 방법론
Automatic하게 paraphrase를 한다면?
• 중요한 것 – Core content를 보존해야 한다!
• 하지만,
– Core content를 보존하며 paraphrase를 하는 방식은 유일하지 않다 (many-to-many)
– Core content는 문장의 유형마다 다를 수 있고, 심지어 시각에 따라 사람마다도 달라질
수 있다
• 이를 Automatic style transfer로 좁혀서 접근한다면?
– 문장의 `자연스러움’이 보장되고 동시에 core content도 유지되어야 한다!
– Core content를 유지하며 style을 변환하는 parallel corpus가 있다면 가장 좋을 것
3
5.
들어가며
• Motivation
난점1
• `Style’이라는 것을 일단 정의하기 어렵다
– 어조, 어투, 화법, 날카로움/부드러움, 딱딱함, 공손함, ...
– 각 요소에 대한 개인차 역시 존재
– 한 언어 화자가 공통적으로 느끼는 style은 어떤 것이 있을까?
난점 2
• 어떠한 style을 정의했다고 가정할 때
– Core content를 뽑아내기 애매할 수 있다
– Text style pair을 (반)자동적으로 얻는 것 역시 어렵다
– 보편적인 `격식‘만 해도... ``어느 나라에서 왔어?’’ vs ``어떤 국가에서 오셨습니까?’’
4
6.
들어가며
• Motivation
난점3
• 가능한 style transfer 리소스가 적은 언어의 경우는?
– 한국어에 대해 알려진 content-preserving dataset이 따로 존재하지 않는다!
– 특히 질문, 명령 등과 같은 directive sentence들에 대해서는 `격식’ style transfer 연구가
비교적 조금 되었다
– 격식에 관한 sentence style transfer corpus가 있다면, 우리 나라 같은 문화권에서는 유
용하게 사용할 수 있을 것
5
7.
들어가며
• 관련 연구
Sentence style transfer
• 주로 작문의 tone and manner에 관해 연구 (Brooks, 2020)
• Content-preserving style transfer (Logeswaran et al., 2018; Tian et al., 2018)
– Tone과 sentiment에 관해 주로 연구가 진행
– Tone의 변화는 content-preserving이 가능하지만, sentiment의 변화는 content를 유지하
지 못할 수 있다
Korean sentence style
• Sentiment (Lee et al., 2019) 혹은 stance (Choi and Na, 2019) 에 대해서 주로 다
루어짐
• Previous studies on formality
– Politeness suffix 유무에 관한 연구 (Hong et al., 2018)
– 전반적인 격식/비격식 문장에 관한 transfer 연구는 아직 진행되지 않음
6
8.
Style transfer 데이터셋의구축
• Overview
목표: 한국어 지시발화를 위한 대규모 병렬 스타일변환 코퍼스 구축하기
• Large-scale: 약 15,000쌍 (PLM 사용을 고려한다면..?)
• Parallel: 같은 core content를 가진 두 문장이 짝지어져 있는 코퍼스
• Style-variant: 격식체와 비격식체 문장
• Korean: 한국어 문장을 위해 새로 작성된 paraphrase guideline
• Directives: 질문과 명령 타입의 지시발화
– 선택의문문 Alternative questions
– 설명의문문 Wh- questions
– 금지 Prohibition
– 요구 Requirements
7
Style transfer 데이터셋의구축
• 자연어 쿼리 작성하기
Paraphrase가 core content를 유지한 채 표현을 바꾸는 것이라면,
core content를 먼저 작성한 후 여러 표현을 만드는 것은 어떨까?
지시 발화의 core content 추출하기(Cho et al., 2019; Cho et al., 2020a)
9
11.
Style transfer 데이터셋의구축
• 자연어 쿼리 작성하기
고려사항
• 토픽
– 인공지능 스피커의 사용자 이용 양상에 대한 조사 (Lee et al., 2020) 참고,
총 6개의 토픽 선정
» 메신저, 캘린더, 날씨와 자연재해(자연 현상), 스마트홈, 쇼핑, 엔터테인먼트
• 문장 유형
– 선택의문문 (청자가 두 개의 답변 중 선택해야 하는 질문)
– 설명의문문 (청자가 자유롭게 답변을 주어야 하는 질문)
– 금지 (청자가 어떤 행동을 금지당함)
– 요구 (청자에게 어떤 행동을 할 의무가 생김)
10
12.
Style transfer 데이터셋의구축
• 자연어 쿼리 작성하기
생성 쿼리 예시
• 쇼핑, 선택의문문
– 삼성과 애플 중 AS를 더 잘해주는 곳
» The one that has better A/S between Samsung and Apple
• 엔터테인먼트, 설명의문문
– 뉴스가 오후 8시에 시작하는 TV 채널
» The TV channel number where the news is on at 8:00 p.m.
• 메신저, 금지
– 위챗 자동 업데이트 켜지 않기
» Not to turn on WeChat automatic update
• 스마트홈, 요구
– 다용도실의 진공청소기 충전하기
» To recharge the wireless vacuum cleaner in the multi-room
11
13.
Style transfer 데이터셋의구축
• 자연어 쿼리 작성하기
작업자 모집!
• 어떤 작업자들을 어떻게 모집해야 할까?
– 한국어 (Seoul Korean) 화자
– 언어학 숙련 요구도: 낮음
– 인구학적 구성: 성별 무관, 연령은 토픽마다 조금씩 다르지만 대체로 무관
• 다양한 배경의 12인의 작업자 모집
– 6인의 작업자: 언어학, 인지과학, 심리학 등 인접분야 전공자 혹은 코퍼스 구축 유경험자
(Group A)
– 다른 6인의 작업자: (언어학 등 인접분야가 아닌) 고등과정 교육 수료 혹은 산업계 종사
(Group B)
• Group A와 B를 짝지어 2명의 작업자로 구성된 6개의 팀 형성
– 각 팀에 서로 다른 토픽 부여
– 선호도, 전공, 직업, 관심사 등을 고려하여 종합적으로 만족할 만한 토픽이 배정될 수 있
도록 함
12
Style transfer 데이터셋의구축
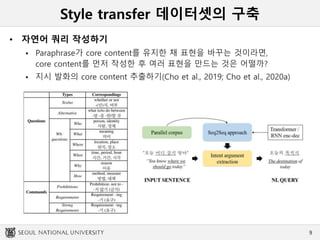
• 자연어 쿼리 작성하기
쿼리 작성
• Cho et al. (2020b) 에 활용된 query generation 방식을 활용
– 일상생활에서 사용될 만한 내용/표현
으로 최대한 다양하게 쿼리 생성하기
– Knowledge-intensive questions 혹은
Queries with multiple contents
(한 번에 여러 가지를 담은 지시발화)
작성할 경우 수정 요청
– 각 그룹의 참여자 1인당 2개 타입의
지시발화를 담당하여 쿼리 작성
– 각 타입 당 125개씩, 토픽 당 도합
500개의 쿼리가 되도록 작성
16
18.
Style transfer 데이터셋의구축
• 쿼리를 격식있는 문장으로 변환하기
왜 격식있는 문장으로 먼저 변환할까?
• `돌려 말하기‘를 통해 다양한 표현을 구사 가능
• Byon (2006) 과 Cho (2008) 의 asking strategies를 참고
– 명령을 부탁으로 바꾸어 부드럽게 하기
– 상대방의 의무/책임을 간접적으로 언급하기
– `혹시’, `좀’ 등의 용어를 통해 상대방의 부담을 경감하기
– 행위 수행의 여유가 되는지 묻기
– 희망 사항을 이야기하기
17
19.
Style transfer 데이터셋의구축
• 쿼리를 격식있는 문장으로 변환하기
상대방이 작성한 쿼리를 일차적으로 격식있는 문장으로 변환
• 쿼리 교환의 이유?
– 1. 쿼리의 적합성을 cross-check
– 2. 다른 작업자와 사고방식 align하기
– 3. 다루지 않았던 문장 유형에 익숙해지기
18
Style transfer 데이터셋의구축
• 격식있는 문장을 비격식 문장으로 변환하기
다른 작업자에 의해 작성된 격식있는 문장을 비격식 문장으로 변환
(쿼리는 본인에 의해 작성됨)
• 여기서 `비격식’이 꼭 무례하거나 impolite한 것만을 의미하는 것은 아님
• 대신, 조금 더 편안하고 친근한 관계에서 나눌 수 있는 대화 (사적 관계?)
20
22.
Style transfer 데이터셋의구축
• 격식있는 문장을 비격식 문장으로 변환하기
요구 사항
• 쿼리의 원래 의도가 격식체 문장에 반영되었는지 체크 (as intended?)
• 격식체 문장의 전체적인 문장 구조를 유지하며 (문장 구조는 격식체에서 다양하게
제시됨) 세부적인 부분들을 변경 (문장에서 최소 두 개 정도의 요소)
– 굳이 발화할 필요 없는 내용들의 생략 (의례를 위한 표현들, 생략가능한 조사)
– 구어에서 편하게 첨가 가능한 표현들 (fillers) 더해주기
– 격식 있는/공적인 표현을 그렇지 않은 표현으로 (국가/나라 등)
21
Style transfer 데이터셋의구축
• 구축 과정에서의 커뮤니케이션
12인의 작업자
• 적지 않지만, 아주 많지도 않음
• 개별 성향 파악 및 적절한 배치의 필요성
– 연구자가 진행하는 프로젝트의 경우, 기존에 커뮤니케이션이 있었던 작업자들이 리쿠르
팅될 확률이 높음
– 플랫폼의 모더레이터가 모집하게 된다면, 작업자를 선정할 만한 다른 기준을 연구자에게
전달받는 것이 좋음
커뮤니케이션 공간
• 전체 공지 방 / 토픽 별 질의응답방 개설
– 전체 공지 방: 토픽 상관없이 해당되는 내용 (쿼리작성/격식체 문장 작성/비격식체 문장
작성) 및 전체적 일정/페이 등에 관한 공지
– 토픽 별 질의응답방: 각 토픽에서 나올 수 있는 질문들 관리 or 토픽별 난이도를 고려한
일정 등을 조율
» 토픽 별 질의응답 중 전체에 해당하는 내용이 있으면 전체 공지 방에 공유
• 쿼리 생성 / 문장 생성 / 문장 변환 모두 파일럿 > 피드백 > 본 생성의 절차 거침
23
Style transfer 데이터셋의구축
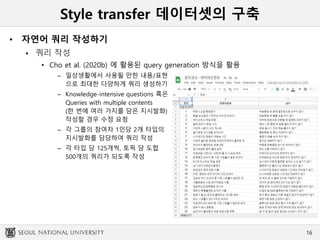
• 최종 코퍼스
최종 검수
• 지시발화 코퍼스 구축 경험이 있는 3인의 한국어 화자가 진행
• 점검 항목
– 오타 및 `이상한 문장‘들
» 구어 발화 시 어색하지 않으면 ok!
– 패러프레이즈의 모음이 충분히 diverse하지 않은 경우들
» 원 작성자에게 수정 문의 or 원 작성자 의견을 반영하여 표현을 다양화
30,000 문장 (15,000 쌍) 으로 구성
• 토픽 당 5,000 문장 (2,500 쌍)
• 문장 유형 당 7,500 문장 (3,750 쌍)
• 24개의 [topic, act] 조합 각각에 대해 125 개의 쿼리
– 각 쿼리들은 5 개의 격식체 + 5 개의 비격식체 문장들로 작성 = 쿼리 당 10개의 문장
25
27.
간단한 실험 결과
•어떤 태스크들이 가능한가?
사실 다용도 태스크 구축을 위해 만들어진 코퍼스!
토픽 분류
• 6-fold, Accuracy 와 F1 score으로 검증
화행 (여기서는 문장 유형) 분류
• 4-fold, Accuracy 와 F1 score으로 검증
패러프레이즈 검출
• 이원 분류, Accuracy 와 F1 score으로 검증
스타일 변환
• Accuracy 와 and character edit distance (CED) 로 검증
– Style classification의 체크
» Train set 문장들과 style label로 학습 후 test set 문장들의 style 예측
– Why character edit distance (CED)?
» 대체로 문장 구조를 보존하는 style transfer 코퍼스를 구축했기 때문
» 한국어 writing system 상 character가 subword의 역할을 하므로
26
28.
간단한 실험 결과
•실험 결과
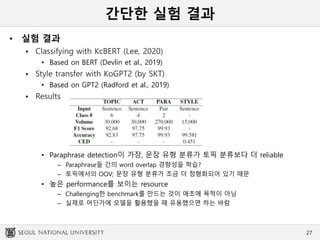
Classifying with KcBERT (Lee, 2020)
• Based on BERT (Devlin et al., 2019)
Style transfer with KoGPT2 (by SKT)
• Based on GPT2 (Radford et al., 2019)
Results
• Paraphrase detection이 가장, 문장 유형 분류가 토픽 분류보다 더 reliable
– Paraphrase들 간의 word overlap 경향성을 학습?
– 토픽에서의 OOV; 문장 유형 분류가 조금 더 정형화되어 있기 때문
• 높은 performance를 보이는 resource
– Challenging한 benchmark를 만드는 것이 애초에 목적이 아님
– 실제로 어딘가에 모델을 활용했을 때 유용했으면 하는 바람
27
29.
간단한 실험 결과
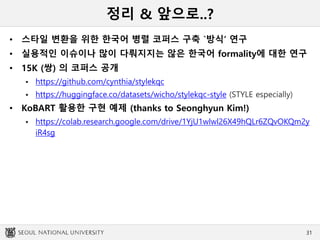
•Qualitative study and error analysis
디코딩 시의 Unknown stop
• 국내 브랜드가 더 많이 들어가 있는 곳을 알아봐 주세요 지마켓과 신세계 중에
(“Please find out where more domestic brands are located, among G-Market
and Shinsegae.”)
• 국내 브랜드가 더 많이 들어가 있는 곳 좀 알아봐줘 지마켓 (*“G-Market, find out
where more domestic brands are in.”)
특정 구절의 반복
• 내일 재고확인하세요 모레 재고확인하세요 (”Will you check stock tomorrow or
the day after tomorrow?”)
• 내일 재고확인 좀 해 모레 재고확인해야겠어 모레 재고확인해야겠어 (*”Check
stock tomorrow. I will check it the day after tomorrow. I will check it the day
after tomorrow.”)
연관 없는 term들의 등장
• Pretrained model을 활용하여, 내부의 지식이 decoding시 삽입?
– 추후 PLM 활용시 주의해야 할 부분
28
30.
정리 & 앞으로..?
•Accepted at LREC 2022!
Language resource & evaluation conference
29
그런데 제가 왜 아직 한국에 있냐면요...ㅠ
31.
정리 & 앞으로..?
•Accepted at LREC 2022!
Some encouragements
30
32.
정리 & 앞으로..?
•스타일 변환을 위한 한국어 병렬 코퍼스 구축 `방식’ 연구
• 실용적인 이슈이나 많이 다뤄지지는 않은 한국어 formality에 대한 연구
• 15K (쌍) 의 코퍼스 공개
https://github.com/cynthia/stylekqc
https://huggingface.co/datasets/wicho/stylekqc-style (STYLE especially)
• KoBART 활용한 구현 예제 (thanks to Seonghyun Kim!)
https://colab.research.google.com/drive/1YjU1wlwl26X49hQLr6ZQvOKQm2y
iR4sg
31
33.
정리 & 앞으로..?
•KoBART 활용한 구현 예제 (thanks to Seonghyun Kim!)
HF datasets에 업로드한 style 코퍼스 활용
gogamza님의 KoBART 로드
32
34.
정리 & 앞으로..?
•KoBART 활용한 구현 예제 (thanks to Seonghyun Kim!)
ROUGE를
metric으로
훈련 진행
33
35.
정리 & 앞으로..?
•KoBART 활용한 구현 예제 (thanks to Seonghyun Kim!)
어느 정도는...?
더 나아져야 할 점
• 불필요한 반복, 긴 문장의 transfer 등
34
36.
정리 & 앞으로..?
•Future direction of style transfer?
훨씬 더 다양한 문장 style에 대한 고려
문장-level을 넘어서는 변환 (혹은 문장 일부만을 변환하도록 통제)
지시 발화가 아니어도 변환을 용이하게 하는 core content의 정의
Big model들과 잘 align될 수 있도록 구축 방식을 개선
... 하는 데에 본 연구가 밑바탕이 될 수 있었으면 좋겠습니다
35
























![Style transfer 데이터셋의 구축
• 최종 코퍼스
최종 검수
• 지시발화 코퍼스 구축 경험이 있는 3인의 한국어 화자가 진행
• 점검 항목
– 오타 및 `이상한 문장‘들
» 구어 발화 시 어색하지 않으면 ok!
– 패러프레이즈의 모음이 충분히 diverse하지 않은 경우들
» 원 작성자에게 수정 문의 or 원 작성자 의견을 반영하여 표현을 다양화
30,000 문장 (15,000 쌍) 으로 구성
• 토픽 당 5,000 문장 (2,500 쌍)
• 문장 유형 당 7,500 문장 (3,750 쌍)
• 24개의 [topic, act] 조합 각각에 대해 125 개의 쿼리
– 각 쿼리들은 5 개의 격식체 + 5 개의 비격식체 문장들로 작성 = 쿼리 당 10개의 문장
25](https://image.slidesharecdn.com/2206modupop-220616124959-582d4c7a/85/2206-Modupop-26-320.jpg)











![[부스트캠프 Tech Talk] 진명훈_datasets로 협업하기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkjinmyunghoon-211210113319-thumbnail.jpg?width=640&height=640&fit=bounds)



![[부스트캠프 Tech Talk] 김봉진_WandB로 Auto ML 뿌수기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkkimbongjin-210515042758-thumbnail.jpg?width=640&height=640&fit=bounds)


![[팝콘 시즌1] 최보경 : 실무자를 위한 인과추론 활용 - Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/papconcausalinferencebestpractices-220221141200-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AIS 2018] [Team Tools_Advanced] Confluence 100배 활용하기 - 커브](https://cdn.slidesharecdn.com/ss_thumbnails/teamtoolsadvancedconfluencecurv-180620000157-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)












![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)



![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D2]다국어음성합성시스템(NVOICE)개발](https://cdn.slidesharecdn.com/ss_thumbnails/2d2nvoice-140929192429-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






























![2008 [lang con2020] act!](https://cdn.slidesharecdn.com/ss_thumbnails/2008langcon2020act-200829231450-thumbnail.jpg?width=640&height=640&fit=bounds)