Downloaded 33 times




![2.1) Word Representation
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-5-2048.jpg)



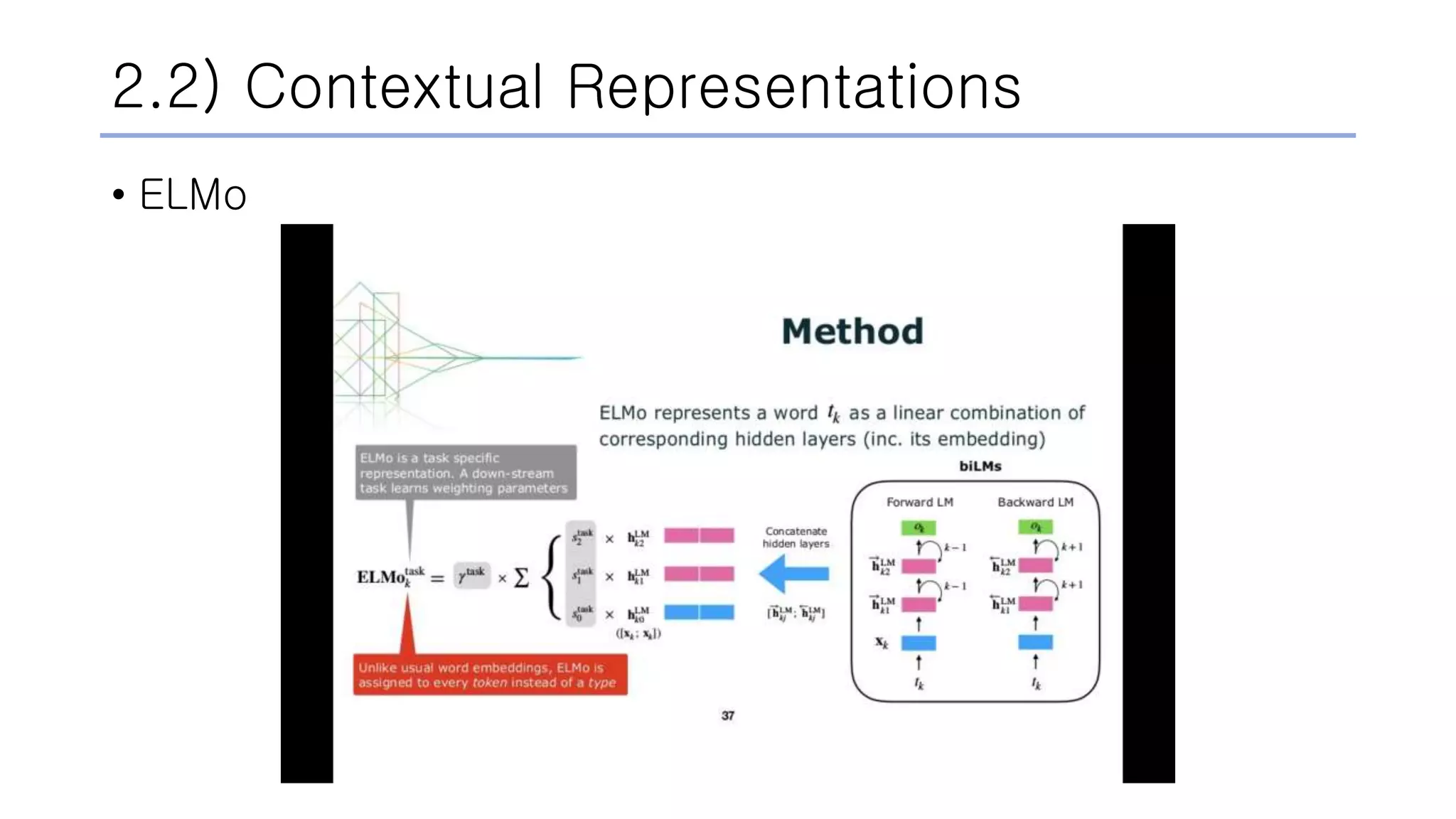
![2.2) Contextual Representations
• ELMo
• Deep Contextualized Word Representations
↘ neural network
↘ 𝑦 = 𝑓(𝑤𝑜𝑟𝑑, 𝑐𝑜𝑛𝑡𝑒𝑥𝑡)
↘ words as fundamental semantic unit
↘ embedding
Ref. [3]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-9-2048.jpg)
![2.2) Contextual Representations
• ELMo
Ref. [4]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-10-2048.jpg)

![2.2) Contextual Representations
• GPT (Generative Pre-Training)
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-13-2048.jpg)

![2.2) Contextual Representations
• GPT
Ref. [5]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-15-2048.jpg)
![2.3) Problem with Previous Methods
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-16-2048.jpg)
![2.3) Problem with Previous Methods
Ref. [6]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-17-2048.jpg)
![2.3) Problem with Previous Methods
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-18-2048.jpg)

![3.1) Masked Language Model
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-20-2048.jpg)
![3.1) Masked Language Model
• Two downsides to MLM approach
i. MLM creates a mismatch between pre-training and fine- tuning,
since the [MASK] token is never seen during fine-tuning.
ii. MLM predicts only 15% of tokens in each batch, which suggests
that more pre-training steps may be required for the model to
converge.](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-21-2048.jpg)
![3.1) Masked Language Model
15% & 10% = 1.5%
: It does not seem t
o harm the model’s
language understan
d-ing capability.
to bias the representation towards the actual observed word.
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-22-2048.jpg)

![3.1) Masked Language Model
Ref. [7]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-24-2048.jpg)
![3.2) Next Sentence Prediction
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-25-2048.jpg)
![3.2) Next Sentence Prediction
Ref. [7]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-26-2048.jpg)
![3.3) Input Representation
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-27-2048.jpg)

![4.1) Transformer
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-29-2048.jpg)


![4.2) GELUs
• Gaussian Error Linear Units
• An activation function by combining properties from
dropout, zoneout, and ReLUs.
• ReLU
• deterministically multiplying the input by zero or one.
• dropout
• stochastically multiplying the input by zero.
• zoneout
• stochastically multiplies inputs by one.
• To build a new activation function called GELU,
the authors merge these functionalities by multiplying the input by
zero or one, but the values of this zero-one mask are
stochastically determined while also dependent upon the input.
Ref. [8]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-32-2048.jpg)
![4.2) GELUs
• GELU’s zero-one mask
• multiply the neuron input 𝑥 by 𝑚 ~ 𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖(𝜙(𝑥)), 𝑤ℎ𝑒𝑟𝑒 𝜙 𝑥 =
𝑃 𝑋 ≤ 𝑥 , 𝑋~𝑁(0, 1) is the cumulative distribution function of the
standard normal distribution.
Ref. [8]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-33-2048.jpg)

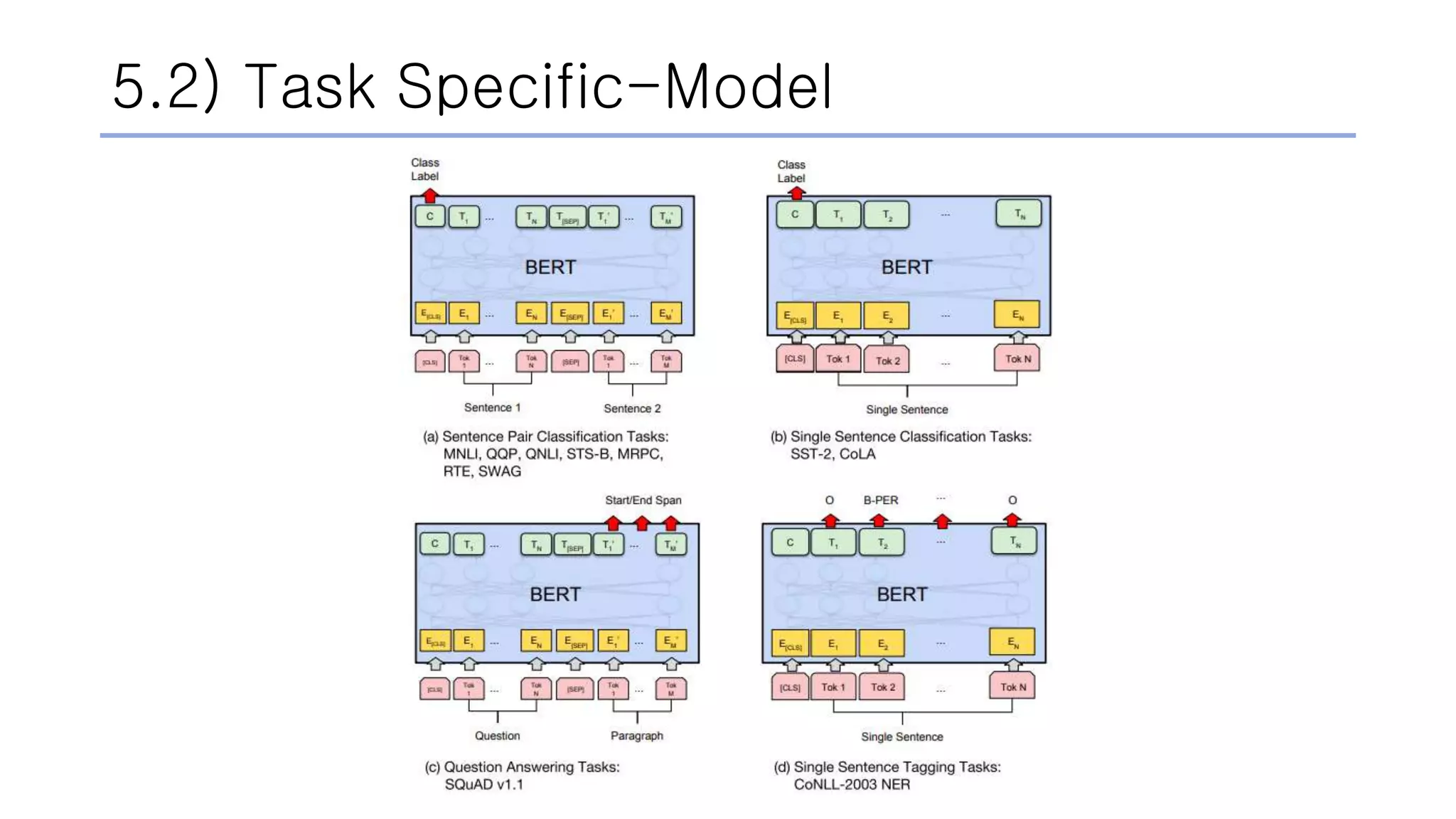
![5.1) Fine Tuning
• Requires only ONE additional output layer
Ref. [2]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-35-2048.jpg)

![6. Results
Ref. [9]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-38-2048.jpg)
![7. Findings
1) Is masked language modeling really more effective than sequential language modeling?
2) Is the next sentence prediction task necessary?
3) Should I use a larger BERT model (a BERT model with more parameters) whenever possible?
4) Does BERT really need such a large amount of pre-training (128,000 words/batch * 1,000,000 steps) to
achieve high fine-tuning accuracy?
5) Does masked language modeling converge more slowly than left-to-right language modeling pretraining
(since masked language modeling only predicts 15% of the input tokens whereas left-to-right language
modeling predicts all of the tokens)?
6) Do I have to fine-tune the entire BERT model? Can’t I just use BERT as a fixed feature extractor?
Ref. [10]](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-39-2048.jpg)






![References
[1] Pretrained Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS
(https://youtu.be/BhlOGGzC0Q0)
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(https://nlp.stanford.edu/seminar/details/jdevlin.pdf)
[3] Improving a Sentiment Analyzer using ELMo — Word Embeddings on Steroids
(http://www.realworldnlpbook.com/blog/improving-sentiment-analyzer-using-elmo.html)
[4] Word Embedding—ELMo
(https://medium.com/@online.rajib/word-embedding-elmo-7369c8f29bfc)
[5] Improving Language Understanding by Generative Pre-Training
(https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
[6] Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
(https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html)
[7] The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
(http://jalammar.github.io/illustrated-bert/)
[8] Gaussian Error Linear Units (GELUs)
(https://arxiv.org/abs/1606.08415)
[9] GLUE Benchmark
(https://gluebenchmark.com)
[10] Paper Dissected: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” Explained
(http://mlexplained.com/2019/01/07/paper-dissected-bert-pre-training-of-deep-bidirectional-transformers-for-language-understanding-explained/)](https://image.slidesharecdn.com/paperreviewbert-190507052754/75/Paper-review-BERT-46-2048.jpg)

BERT is a language representation model that was pre-trained using two unsupervised prediction tasks: masked language modeling and next sentence prediction. It uses a multi-layer bidirectional Transformer encoder based on the original Transformer architecture. BERT achieved state-of-the-art results on a wide range of natural language processing tasks including question answering and language inference. Extensive experiments showed that both pre-training tasks, as well as a large amount of pre-training data and steps, were important for BERT to achieve its strong performance.























![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)