혐오 표현 가이드라인구축의 이론과 실제:
한국어 온라인 텍스트를 중심으로
조원익 (SNU ECE)
2022. 4. 6 @Kakao
2.
Contents
• 연사 소개
•혐오 표현 연구 배경
• 한국어 온라인 혐오 표현 분석
• 데이터 구축의 맹점
• 정답은 있을까?
• 마치며...
Caution! This presenation contains contents that can be offensive
1
3.
연사 소개
• 조원익
B.S. in EE/Mathematics (SNU, ’10~’14)
Ph.D. student (SNU INMC, ‘14~)
• Academic background
Interested in mathematics → EE!
Early years in Speech processing lab
• Source separation
• Voice activity & endpoint detection
• Automatic music composition
Currently studying on computational
linguistics
• Spoken language understanding
• AI for social good
2
4.
연사 소개
• Researcheson AI for social good
Evaluating translation gender bias
(Cho et al., 2021)
Spacing for digital minorities
(Cho et al., 2021)
Hate speech study for Korean
• BEEP! (Moon et al., 2020)
– Korean hate speech corpus
for online celebrity news comments
• APEACH (Yang et al., 2022)
– Crowd-generated Korean hate speech
evaluation corpus (w/ Kichang)
3
5.
혐오 표현 연구배경
• 혐오 표현
왜 혐오 표현 연구를 하고 싶었는가?
• 온라인 공간에서의 편가르기, 네거티브, 욕설/멸시 등에 지쳐서...
– 왜 사람들은 이렇게 화가 나 있을까?
• 1차 시도 – 수작업 크롤링...
• 포기 – 어차피 혐오할 사람들은 혐오를 한다
– 성별, 나이, 지역, 종교, ...
• 그럼에도 불구하고
– 혐오로 인해 피해받는 누군가가 있다
– 본인의 발화가 혐오인지 모르는 경우도 많이 있다
• 어떤 발화가 혐오인지 아닌지 판단할 수 있을까?
– 혐오와 그렇지 않은 것 사이의 경계가 모호하다
– 사람도 어려운데 기계가 할 수 있을까?
4
6.
혐오 표현 연구배경
• 혐오 표현
일단 사람이 할 수 있는 것부터 생각해보자
• Hate speech가 무엇일까? (연역)
– 어떤 개인/집단에 대하여 그들이 사회적 소수자로서의 속성을 가졌다는 이유로 그들을
차별/혐오 하거나 차별/적의/폭력을 선동하는 표현
» 개인/집단 (ok)
» 사회적 소수자로서의 속성 (?)
» 차별/적의/폭력 (?)
• 어떤 문장이 주어졌을 때 그것을 hate speech라고 부르게 되는 사고과정 (귀납)
– Toxic하다?
» 단순히 욕설이 들어 있을 때 그것을 hate speech라고 할 수 있을까?
“이런씹ㅋㅋㅋㅋㅋㅋ” vs “씹새x네;” vs “저런 씨x년들 때문에 나라가 이모양”
» 그 욕설이 누군가를 상대로 한다면?
» 그 욕설이 특정 집단의 사람들을 상대로 한다면?
– 욕설은 들어있지 않지만 기분이 나쁘다면(offensive)? “
– Toxic하지 않지만 bias를 포함하고 있다면?
5
7.
혐오 표현 연구배경
• 혐오 표현
해외 혐오 표현 탐지에 관한 논의
• Waseem and Hovy (2016)
– 혐오 표현으로 판단될 수 있는 10여개의 특성들을 활용해 트위터 게시물 태깅
• Davidson et al. (2017)
– 혐오 표현의 학문적 정의와 실제 표현들에 대한 판단 사이의 괴리를 언급
– 혐오 표현(hate)과 혐오 표현이 아닌 것(none) 사이에 무례한 언사(offensive)를 두어,
grey zone에 있는 표현들을 포괄할 수 있도록 함
• Sanguinetti et al. (2018)
– 이탈리아의 이민자들에 대한 게시글을 대상으로 혐오 표현을 판단하되, hate speech 여
부뿐 아니라 offensive한지, aggressive한지, irony와 sarcasm이 존재하는지, stereotype
이 존재하는지, 전반적인 글의 intensity가 어떠한지 등에 대해 종합적으로 표시함
– 차별의 근거가 될 수 있는 선입견(stereotype)을 레이블링의 요소로 삼음
• Assimakopoulos et al. (2020)
– 몰타어 web text를 대상으로, 텍스트의 attitude가 positive/negative한지, negative하다
면 그 대상이 누구인지, 그 attitude가 어떤 형식으로 전달되는지 (편견, 위협, 모욕 등)
6
8.
혐오 표현 연구배경
• Research Questions
RQ1
• 한국어 온라인 텍스트에 어떤 hate speech들이 포함되어 있을까?
– 어떤 종류의 bias가 들어있는지, 각 요소를 파악할 수 있는지
– 표현의 toxic한 정도를 판단할 수 있을지
RQ2
• 한국어 hate speech corpus가 가지는 특성은 무엇일까?
– Bias가 있는 정도와 표현이 toxic한 정도는 어떤 관계가 있는지
– Toxicity와 bias type과는 연관이 있는지
7
9.
한국어 온라인 혐오표현 분석
• BEEP! 에서 수집된 뉴스 댓글 데이터
온라인 포털 연예 뉴스 기사
• 두터운 독자층, 타깃이 확실, 관찰되는 갈등이 특정 집단에 치우치지 않음
– 댓글 수집 배포에 문제는 없는가?
기간: Jan. 2018 ~ Feb. 2020
수집 기사 및 댓글
• Raw data:
– 10,403,368 from 23,700 articles
• 1,580 articles (by stratified sampling)
– 특정 기간에 몰리지 않도록
• Top 20 댓글
– Downvote 비율을 고려하여 추출 (Wilson Score)
• Removed?
– 중복된 댓글
– single token이나 100자 이상의 댓글
• 최종적으로, random한 10K개의 댓글 샘플링
8
10.
한국어 온라인 혐오표현 분석
• 문제 구성
혐오 표현
• 10,000개 댓글 중 1,000개를 함께 분석하며 토의
• 어떤 요소들이 존재할까?
– 편견(bias)
» ‘이러이러한 사람’은 ‘이러이러한 특징’을 가질 것이다
» 단순한 판단(judgment)과 다를 수 있다
– 혐오(hate)
» ‘이러이러한 특징’을 가진 집단에 대한 적대감
» 이는 profanity terms로도 표출될 수 있지만, 그렇다고 해서 혐오인 것은 아님
– 모욕(insult)
» 개인 및 집단의 사회적 체면을 깎을 수 있는 언사
» 많은 profanity terms가 이에 해당함
– 무례한 언사(offensive)
» 혐오나 모욕에는 미치지 못하지만, 대상이나 보는 이를 기분나쁘게 할 수 있음
» 냉소, 비꼼, 넘겨짚기, 반인륜적 표현 등이 이에 해당
9
11.
한국어 온라인 혐오표현 분석
• 문제 구성
Social bias + Toxicity
• 편견의 검출 (ternary)
– Gender-related bias
– Other biases
– None
» 탐지의 문제에 가까움
» Why concentrated on gender issue?
• 유해성의 판단 (ternary)
– Severe hate or insult
– Not hateful but offensive or sarcastic
– None
» 수위의 문제에 가까움
» Why formulated as a problem of intensity?
10
12.
한국어 온라인 혐오표현 분석
• 가이드라인 작성
편견에 대한 세부 사항 (1) Gender-related bias
11
13.
한국어 온라인 혐오표현 분석
• 가이드라인 작성
편견에 대한 세부 사항 (2) Other bias
12
14.
한국어 온라인 혐오표현 분석
• 가이드라인 작성
편견에 대한 세부 사항 (2) Other bias
13
15.
한국어 온라인 혐오표현 분석
• 가이드라인 작성
유해성에 대한 세부 사항 (1) Severe hate or insult
• 혐오: 대상을 일정한 특성에 근거해서 섣불리 판단한 후 대상에 대해 적대감을 드
러내는 발언
– 표현의 대상에게 정신적인 고통과 같은 감정 상태를 야기하는 경우에도 해당됨
• 모욕: 대상에 대해 근거없이 비난하거나 깎아내리는 경우
– 대상이 모욕감 혹은 수치감을 느낄 수 있는 발언
• 합리적인 비판은 해당되지 않으며, 단순히 욕설이 등장한다고 해서 모욕이나 혐오
가 느껴지는 것은 아닐 수 있음
14
한국어 온라인 혐오표현 분석
• 가이드라인 작성
유해성에 대한 세부 사항 (2) Not hateful but offensive or sarcastic
17
19.
한국어 온라인 혐오표현 분석
• 가이드라인 작성
(2) Not hateful but offensive or sarcastic & (3) None
18
20.
한국어 온라인 혐오표현 분석
• 결국 사람이 작업하게 된다
나 하나만의 의견으로 어떤 텍스트가 hate speech임을 결정할 수 있을까?
• 내가 어떤 텍스트를 hate speech로 판단하는 과정
– 가이드라인 기반의 Step by step
» Profanity term이 존재하는가?
» Offensive한가?
» Social bias를 포함하는가?
» ...
– Grey area의 존재
» 이 텍스트는... bias로 보기엔 그냥 판단에 가까운데?
» 이 텍스트는 hateful하다기보다는 offensive한 정도인데?
» ...
• 특정 단어가 존재하는지 등과 같은 `분명한’ example들이 아니라면, 나 혼자만의
생각으로 target label을 정하는 것은 위험하다
– 여러 사람의 의견을 합칠 필요가 있음
» 파일럿 연구: 소수의 연구자들의 의견을 토의
» 대규모 구축: 크라우드소싱을 활용, 워커 교육 후 레이블링
19
21.
한국어 온라인 혐오표현 분석
• 플랫폼 선정 – 어떤 조건을 만족해야 좋을까? (사전 조사)
예산 설정의 합리성
• VAT의 비율, 플랫폼 사용료
• 태깅 당 책정 금액 (및 어노테이터에게 돌아가는 금액)
• 어떤 것을 태깅 1회로 책정하는가
• 태깅 class 수에 따른 가격 차이
경험 및 어노테이터 풀
• 기존 자연어 데이터 및 유사 데이터 구축 경험이 충분히 많은가
• 어노테이터 풀을 잘 확보하고 있는가
• 태스크를 잘 이해하고 있는가
• 크라우드소싱에서의 노하우를 가지고 있는가
20
22.
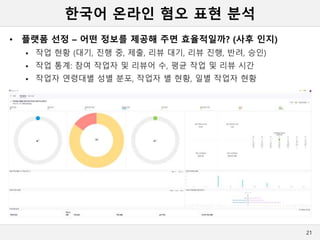
한국어 온라인 혐오표현 분석
• 플랫폼 선정 – 어떤 정보를 제공해 주면 효율적일까? (사후 인지)
작업 현황 (대기, 진행 중, 제출, 리뷰 대기, 리뷰 진행, 반려, 승인)
작업 통계: 참여 작업자 및 리뷰어 수, 평균 작업 및 리뷰 시간
작업자 연령대별 성별 분포, 작업자 별 현황, 일별 작업자 현황
21
23.
한국어 온라인 혐오표현 분석
• 여러 사람의 작업이 필요
파일럿 연구 - `아무나 태깅시키지 않는다‘
• 일정 횟수 이상의 태깅을 진행하였는가?
• 반려한 샘플들에 대한 피드백이 잘 반영되었는가?
• 가이드라인과 현격히 차이가 있는, 성별이나 다른 요소들에 대한 기준을 가지고
있지는 않은가?
• 태깅을 pass하는 빈도가 너무 높지는 않은가?
22
24.
한국어 온라인 혐오표현 분석
• 크라우드소싱 – 선정된 작업자들과 함께
어노테이션 과정에서의 질의응답 / 최종 결과물 리뷰
23
25.
한국어 온라인 혐오표현 분석
• 데이터 후처리
전체 어노테이션 완료 후 (8,000개)
• Social bias와 toxicity에서 공통적으로 체크한 내용
– 세 명의 어노테이터가 모두 다른 태깅을 한 경우
» 태깅 기반으로, 리뷰어들의 논의를 통해 결정
• Toxicity에서 체크한 내용
– ‘Intensity’의 문제이기 때문에, (o) 아니면 (x) 만 있는 경우는 다시 체크해볼 필요가 있음
» 역시 태깅 기반의 논의을 통해 결정
• 위의 절차를 거치고 합의에 이르지 못하는 경우 (majority voting 불가) discard함
Inter-annotator agreement (Krippendorff’s alpha): 전반적으로 moderate한
일치도
• Bias (binary) – 0.767 (성 관련 편견의 존재 여부는 비교적 명확)
• Bias (ternary) – 0.492
• Hate (ternary) – 0.496
24
26.
한국어 온라인 혐오표현 분석
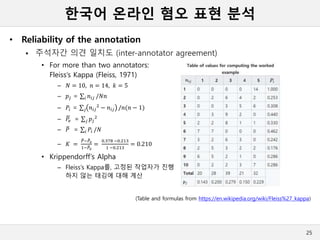
• Reliability of the annotation
주석자간 의견 일치도 (inter-annotator agreement)
• For more than two annotators:
Fleiss’s Kappa (Fleiss, 1971)
– 𝑁 = 10, 𝑛 = 14, 𝑘 = 5
– 𝑝𝑗 = 𝑖 𝑛𝑖𝑗 /𝑁𝑛
– 𝑃𝑖 = 𝑗 𝑛𝑖𝑗
2
− 𝑛𝑖𝑗 /𝑛(𝑛 − 1)
– 𝑃𝑒 = 𝑗 𝑝𝑗
2
– 𝑃 = 𝑖 𝑃𝑖 /𝑁
– 𝐾 =
𝑃−𝑃𝑒
1−𝑃𝑒
=
0.378 −0.213
1 −0.213
= 0.210
• Krippendorff’s Alpha
– Fleiss’s Kappa를, 고정된 작업자가 진행
하지 않는 태깅에 대해 계산
25
(Table and formulas from https://en.wikipedia.org/wiki/Fleiss%27_kappa)
27.
한국어 온라인 혐오표현 분석
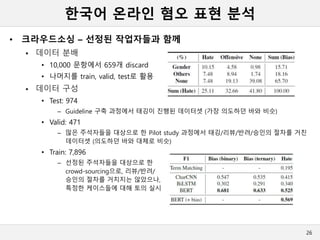
• 크라우드소싱 – 선정된 작업자들과 함께
데이터 분배
• 10,000 문항에서 659개 discard
• 나머지를 train, valid, test로 활용
데이터 구성
• Test: 974
– Guideline 구축 과정에서 태깅이 진행된 데이터셋 (가장 의도하던 바와 비슷)
• Valid: 471
– 많은 주석자들을 대상으로 한 Pilot study 과정에서 태깅/리뷰/반려/승인의 절차를 거친
데이터셋 (의도하던 바와 대체로 비슷)
• Train: 7,896
– 선정된 주석자들을 대상으로 한
crowd-sourcing으로, 리뷰/반려/
승인의 절차를 거치지는 않았으나,
특정한 케이스들에 대해 토의 실시
26
28.
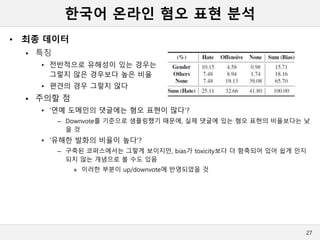
한국어 온라인 혐오표현 분석
• 최종 데이터
특징
• 전반적으로 유해성이 있는 경우는
그렇지 않은 경우보다 높은 비율
• 편견의 경우 그렇지 않다
주의할 점
• ‘연예 도메인의 댓글에는 혐오 표현이 많다’?
– Downvote를 기준으로 샘플링했기 때문에, 실제 댓글에 있는 혐오 표현의 비율보다는 낮
을 것
• ‘유해한 발화의 비율이 높다’?
– 구축된 코퍼스에서는 그렇게 보이지만, bias가 toxicity보다 더 함축되어 있어 쉽게 인지
되지 않는 개념으로 볼 수도 있음
» 이러한 부분이 up/downvote에 반영되었을 것
27
29.
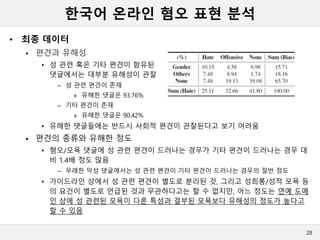
한국어 온라인 혐오표현 분석
• 최종 데이터
편견과 유해성
• 성 관련 혹은 기타 편견이 함유된
댓글에서는 대부분 유해성이 관찰
– 성 관련 편견이 존재
» 유해한 댓글은 93.76%
– 기타 편견이 존재
» 유해한 댓글은 90.42%
• 유해한 댓글들에는 반드시 사회적 편견이 관찰된다고 보기 어려움
편견의 종류와 유해한 정도
• 혐오/모욕 댓글에 성 관련 편견이 드러나는 경우가 기타 편견이 드러나는 경우 대
비 1.4배 정도 많음
– 무례한 악성 댓글에서는 성 관련 편견이 기타 편견이 드러나는 경우의 절반 정도
• 가이드라인 상에서 성 관련 편견이 별도로 분리된 것, 그리고 성희롱/성적 모욕 등
의 요건이 별도로 언급된 것과 무관하다고는 할 수 없지만, 어느 정도는 연예 도메
인 상에 성 관련된 모욕이 다른 특성과 결부된 모욕보다 유해성의 정도가 높다고
할 수 있음
28
30.
데이터 구축의 맹점
•예외 케이스 / 결정불가능한 케이스의 존재
너무 짧거나 오타가 있거나, 정말로 context 없이는 알 수 없는 경우들
• 예외 제거 > 나중에 저런 경우들이 input으로 들어온다면?
29
31.
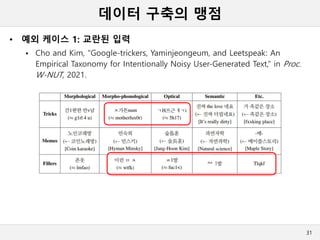
데이터 구축의 맹점
•예외 케이스 1: 교란된 입력
Kim et al., “Trkic G00gle: Why and How Users Game Translation Algorithms,”
in Proc. CSCW, 2021.
30
32.
데이터 구축의 맹점
•예외 케이스 1: 교란된 입력
Cho and Kim, “Google-trickers, Yaminjeongeum, and Leetspeak: An
Empirical Taxonomy for Intentionally Noisy User-Generated Text,” in Proc.
W-NUT, 2021.
31
33.
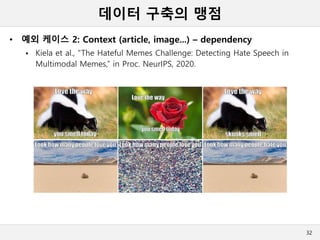
데이터 구축의 맹점
•예외 케이스 2: Context (article, image...) – dependency
Kiela et al., “The Hateful Memes Challenge: Detecting Hate Speech in
Multimodal Memes,” in Proc. NeurIPS, 2020.
32
34.
데이터 구축의 맹점
•도메인 특수성
Text style
• 현재 source: 온라인 뉴스기사 댓글
– 여러 커뮤니티를 활동하는 다양한 그룹의 사람들이 작성하지만, 기본적으로 web text
– 다른 normalized text, 혹은 written text와 성격이 다름
– 다양한 양식으로 작성된 hate speech를 파악하기 어려울 수 있음
Text topic
• 현재 topic: 연예뉴스 기사 댓글
– 전반적인 주제를 모두 다루는 포털/커뮤니티 게시물 댓글과 달리, 연예인(특정 인물)에
대한 hate speech가 주를 이룸
» 이에 따라, 대부분의 사람들에게 해당되는 토픽 (젠더, 성 정체성 등) 위주로 등장
하게 되며, 거의 다뤄지지 않는 토픽들이 존재하게 됨
» 이러한 문제는 `정치’, `종교’ 등 토픽이 명확한 정치 기사 댓글에서도 비슷하게 발
생할 것
33
35.
데이터 구축의 맹점
•도메인 특수성을 해소하려는 노력
Text style
• 박진원 외, “비윤리적 한국어 발언 검출을 위한 새 데이터 세트,” ACK 학술발표대
회 논문집 (28권 2호), 2021.
– 기존 네이버 뉴스 댓글에서 관찰되는 텍스트 스타일 유형에 한계가 있음
– 커뮤니티 별 텍스트를 골고루 수집함으로써 이를 보완
34
36.
데이터 구축의 맹점
•도메인 특수성을 해소하려는 노력
Text topic
• Unsmile
– https://github.com/smilegate-ai/korean_unsmile_dataset
– 여성/가족, 남성, 성소수자, 인종/국적, 연령, 지역, 종교, 기타혐오, 악플/욕설, clean, 개인
지칭 등 10개의 카테고리로 multi-label 태깅
35
37.
데이터 구축의 맹점
•작성자 본인의 의도를 알 수 없다
혐오 표현에는 implication이 많다
• Imply된 것 중에는 텍스트만으로 알 수 없는 정보들도 많다
– e.g., 사진이 주어진 기사의 댓글
꼬아 읽으려면 한없이 꼬아 읽을 수 있다
무언가를 생략하거나 치환하여 발화하는 경우도 많다 (e.g., 주어생략, oo없음)
• 그렇지만 당시의 컨텍스트에 비추어 생략의 의미가 없는 경우
• 작성 당시에는 normal speech, 나중에 볼 때는 hate speech (혹은 반대)
데이터 구축에 시대적 요소가 반영되지 않는다면, training-inference의 의미
가 크게 없을 수 있다
• e.g., `승리’ before 2019 / after 2019
36
38.
데이터 구축의 맹점
•Hate speech와 freedom of speech의 경계
Grey area의 텍스트에 대한 처리?
• 설령 majority voting을 통해 결정했다고 해도,
– 누군가는 detect되지 않은 텍스트를 불편해할 수 있다
– 누군가는 텍스트가 detect되었다는 사실에 불편해할 수 있다
• 데이터가 침해할 수도 있는 privacy issue
데이터의 라이센스 이슈
• Hate speech가 작성된 플랫폼 기준의 라이센스
• Hate speech를 작성한 사람이 다른 곳에서 텍스트를 가져왔을 수도 있음
데이터 내에 공인이 아닌 특정 인물에 대한 비난/개인정보가 등장할 수 있음
37
39.
마치며...
• 처음부터 깔끔하게만들어진 데이터는 없다
그렇지만 데이터를 만드는 과정에서 그 데이터 자체에 대해 배울 수 있다
• 빡센 코퍼스 구축에는 다양한 고려사항들이 필요
데이터 구축의 합목적성 – 문제 정의는 그 목적을 적합하게 달성하는가?
• e.g., ‘혐오 표현‘을 정의하고 검출하여 얻을 수 있는 사회적 효용은? 역으로, 그런
결과를 가져올 수 있는 정의의 방식은?
많은 부분 예산이 영향을 미치고 타협이 필요하지만, 주어진 예산으로 가장
효율적으로 구축할 수 있는 방법은?
• e.g., 동일한 태깅으로 얼마나 많은 정보를 획득할 수 있을까?
어노테이션 자체에도 리뷰/반려/승인의 절차가 필요하다
• 모든 데이터에 대하여 이렇게 하기 어렵다면 적어도 가능한 adjudication을 위한
기준을 세워야 한다
– e.g., 모든 어노테이션이 다른 경우, ‘정도’의 차이에서 큰 차이가 발생한 경우
38
40.
마치며...
• 혐오표현 검출의방향성에 대해
혐오 표현의 학문적, 사회적, 산업적 논의 간에는 온도차가 존재하며, 각각의
목표를 인지해야 함
혐오 표현의 탐지 관점에서 가이드라인을 만들고 코퍼스를 구축하는 과정에
서, 사회적 편견과 유해성이라는 요소에 주목
모두를 만족시킬 만한 혐오표현 가이드라인은
없다는 것을 인정하고, 최대한
많은 사람들이 만족할 만한
경계를 활용하되 ‘검출’/‘감시‘
보다는, ‘제안’/‘경고‘의 관점이 필요
39



































![[kakaobrain]beep](https://cdn.slidesharecdn.com/ss_thumbnails/aclsocialnlp2020beepslidev2-200703173413-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SD]혐오문제_고가희_김영민](https://cdn.slidesharecdn.com/ss_thumbnails/181222socialdesignfinal-181228051249-thumbnail.jpg?width=640&height=640&fit=bounds)












![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)










![2008 [lang con2020] act!](https://cdn.slidesharecdn.com/ss_thumbnails/2008langcon2020act-200829231450-thumbnail.jpg?width=640&height=640&fit=bounds)