Downloaded 50 times






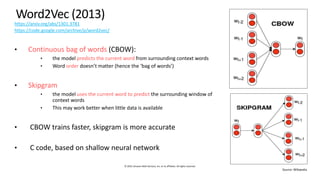


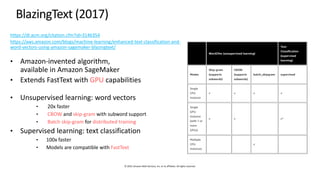

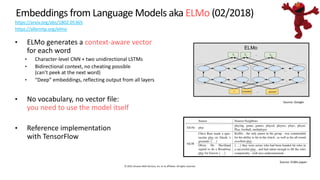










The document provides an overview of natural language processing (NLP) models, discussing various methodologies for creating word embeddings and their applications in different NLP tasks like text classification and translation. It covers notable models such as Word2Vec, GloVe, FastText, ELMo, BERT, and XLNet, highlighting their strengths and limitations. The text emphasizes the importance of utilizing pre-trained models and fine-tuning for specific business problems while acknowledging the computational costs associated with training advanced models.
















































































