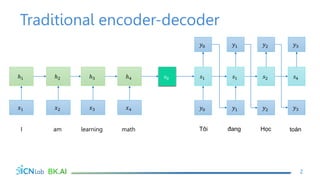
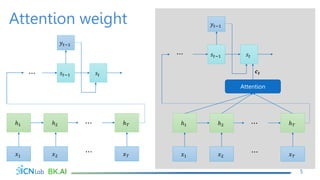
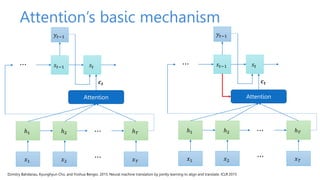
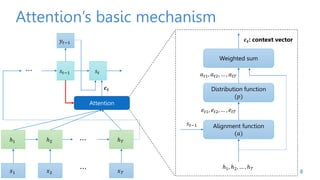
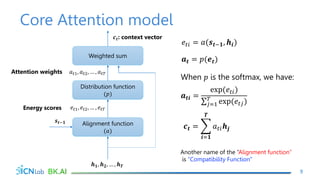
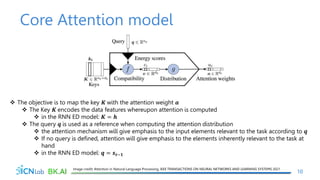
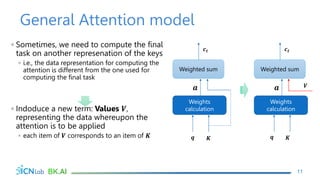
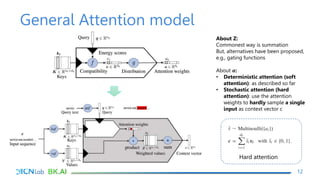
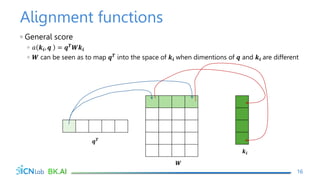
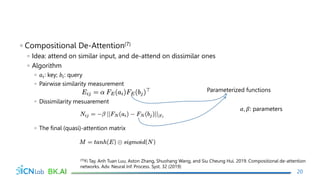
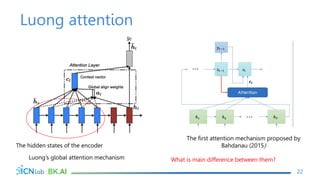
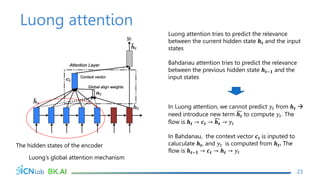
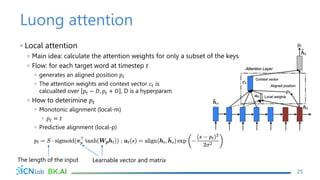
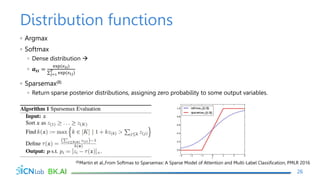
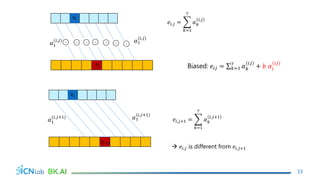
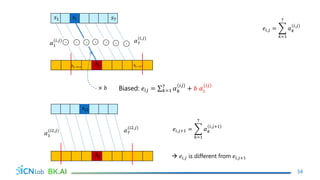
The document discusses attention mechanisms for encoder-decoder neural networks. It describes traditional encoder-decoder models that compress all input information into a fixed vector, which cannot encode long sentences. Attention mechanisms allow the decoder to access the entire encoded input sequence and assign weights to input elements based on their relevance to predicting the output. The core attention model uses an alignment function to calculate energy scores between the input and output, a distribution function to calculate attention weights from the energy scores, and a weighted sum to compute the context vector used by the decoder. Various alignment functions are discussed, including dot product, additive, and deep attention.


















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





































![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)























