Download as PDF, PPTX


![What is Natural Language
Processing?
• NLP is the process of having
machines understand
language
• iOS 11 has built in examples
such as
NSLinguisticTagger for
tokenisation and
lemmatisation
• Intent Classification & Slot
Tagging is a sub-field of NLP.
Used as a technique for Siri,
Alexa, and Google Assistant
Play me a jazz song from Louis
Armstrong from 1967
{
"intent": "play_music",
"slots": [
0: {
"genre": "jazz",
"artist": "Louis Armstrong",
"year": "1967"
}
]
}
Tokenisation:
Lemmatisation:
“The cat sat on the mat” = [“The”, “cat”, “sat”, “on”, “the”, “mat”]
“Running” = “run”, “Swam” = “Swim”
Intent Classification & Slot Tagging:](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-3-2048.jpg)
![Data Vectorisation
• In machine learning, data
representation is very
important.
• 🗑 ! fn(x) ! 🗑
• We like our data to be
represented as vectors.
• Images are vectors (JPEG)
and so are sounds (WAV)
• How do we vectorise words for
NLP?
255 45 199 12
23 129 34 5
49 56 94 254
87 142237175
123243192188
255 45 199 12
23 129 34 5
49 56 94 254
87 142237175
123243192188
255 45 199 12
23 129 34 5
49 56 94 254
87 142237175
123243192188
R
G
B
Colour images can be represented as a Rank 3
Tensor
Imagine this construct = [[[xr],[yr]], [[xg,][yg]],
[[xb],[yb]]]](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-5-2048.jpg)


![Keras on Tensorflow
• Keras is a high-level abstraction developed for Deep Learning that
runs on multiple backends (Tensorflow/Theano/CNTK/MxNet)
• Keras is CoreML compatible.
• Keras can also be converted to run on Tensorflow.
• Android has good Tensorflow support.
model = Sequential([
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
TimeDistributed(Dense(64)),
Activation('relu'),
TimeDistributed(Dense(32)),
Activation('relu'),
TimeDistributed(Dense(num_labels)),
Activation('softmax', name="output")
])](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-11-2048.jpg)

![Extending The Model
model = Sequential([
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
LSTM(128, batch_size=1, input_shape=(None, 300), dropout=0.25, return_sequences=True),
TimeDistributed(Dense(64)),
Activation('relu'),
TimeDistributed(Dense(32)),
Activation('relu'),
TimeDistributed(Dense(num_labels)),
Activation('softmax', name="output")
])
This means that the length of
the input sequence is
computed dynamically at
training time.
The output vector is squashed
from 32 to n-number of labels.
Vector order is important!
Extending the model in Python is easy, but
not so straightforward for CoreML](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-13-2048.jpg)

![Jinja Templating
• After the training phase of the
NLP model, we generate a
config.json
• JSON describes the output
models, and CoreML and
Android model files and the
required parameters
{
"models": [
{
"type": "IntentClassifier",
"name": "UtteranceIntent",
"intents": ["Make", "Weather", "News", "Recommend", "Help"],
"android": {
"filename": "intent_classifier.pb",
"inputOperationName": "lstm_8_input",
"outputOperationName": "activation_18/Softmax"
},
"ios": {
"filename": "CCLabsIntentClassifierModel.mlmodel",
"inputOperationName": "input1",
"outputOperationName": "output1"
},
"inputShape": "300"
},
{
"type": "SlotTagger",
"name": "Weather",
"slots": ["None", "Weather", "Time", "Location"],
"android": {
"filename": "weather_slot_tagger.pb",
"inputOperationName": "lstm_1_input",
"outputOperationName": "output/truediv"
},
"ios" : {
"inputOperationName": "input1",
"outputOperationName": "output1"
},
"inputShape": "300"
},...]
}](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-15-2048.jpg)
![Jinja Templating Cont’d
{
"models": [
{
"type": "SlotTagger",
"name": "Weather",
"slots": ["None", "Weather", "Time", "Location"],
"android": {
"filename": "weather_slot_tagger.pb",
"inputOperationName": "lstm_1_input",
"outputOperationName": "output/truediv"
},
"ios" : {
"inputOperationName": "input1",
"outputOperationName": "output1"
},
"inputShape": "300"
},...]
}
// Flatten vector
NSMutableArray *flattenedVector = [[NSMutableArray alloc] init];
for (NSArray<NSNumber*>* element in vector.data) {
[flattenedVector addObjectsFromArray:element];
}
// Convert vector to multiarray
NSNumber* vectorCount = [NSNumber numberWithUnsignedInteger: vector.tokens.count];
NSNumber* utteranceCount = [NSNumber numberWithUnsignedInteger: 1];
NSNumber* valueCount = [NSNumber numberWithUnsignedInteger: {{ input_shape }}];
MLMultiArray *multiArray = [[MLMultiArray alloc] initWithShape:@[vectorCount, utteranceCount, valueCount]
dataType:MLMultiArrayDataTypeFloat32
error: &predictionError];](https://image.slidesharecdn.com/cocoaheads-180209002619/75/CoreML-for-NLP-Melb-Cocoaheads-08-02-2018-16-2048.jpg)
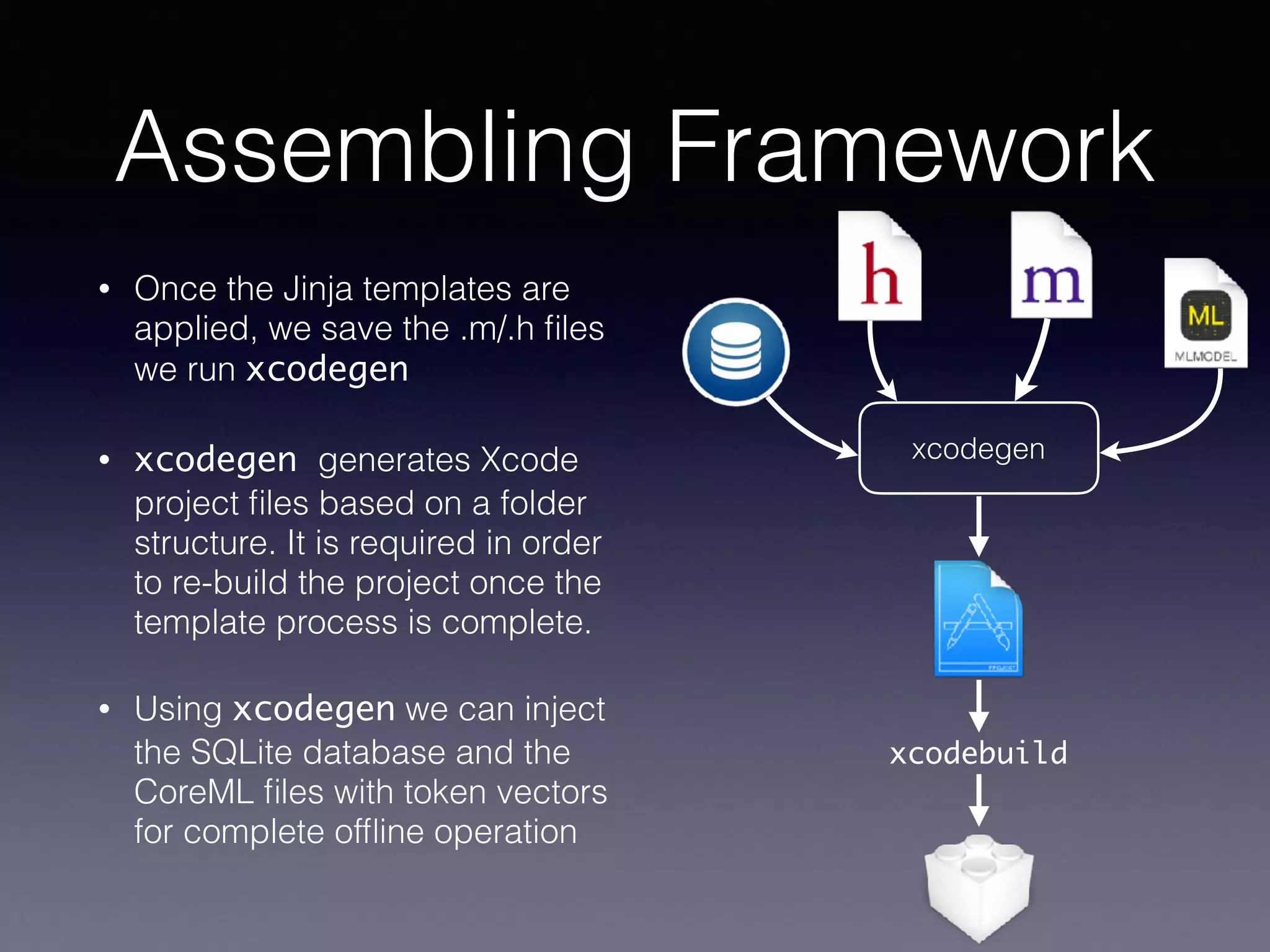


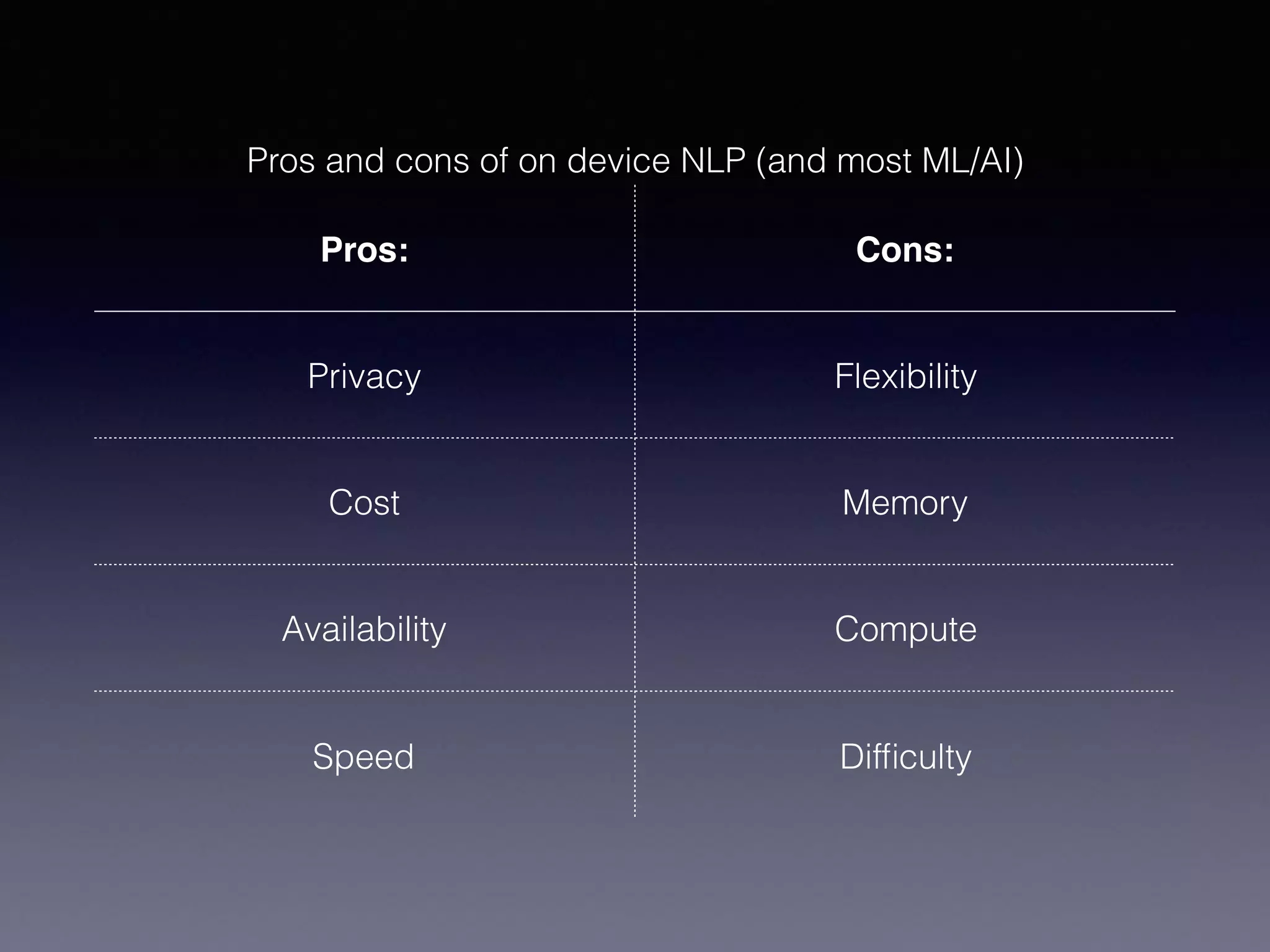
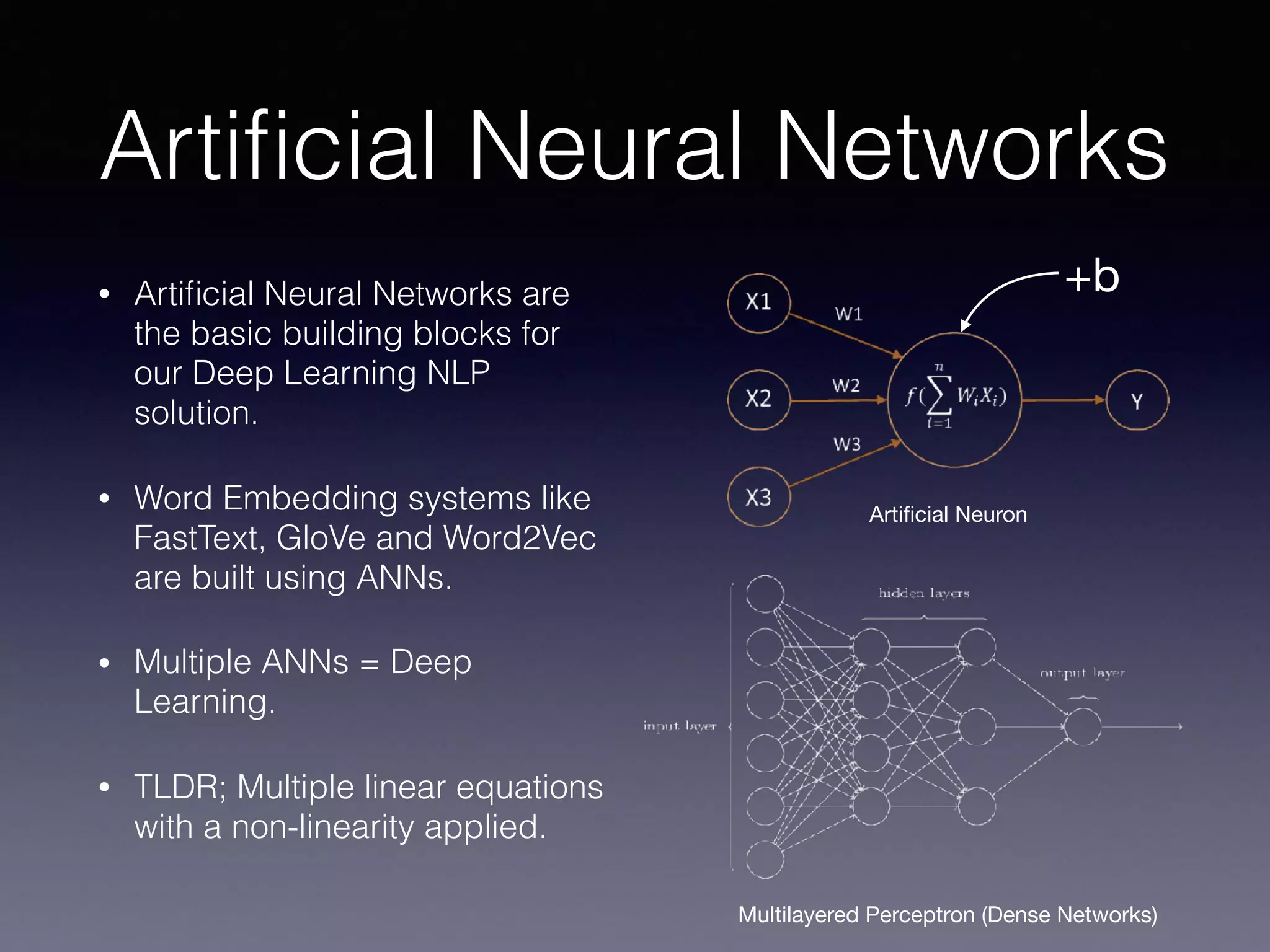
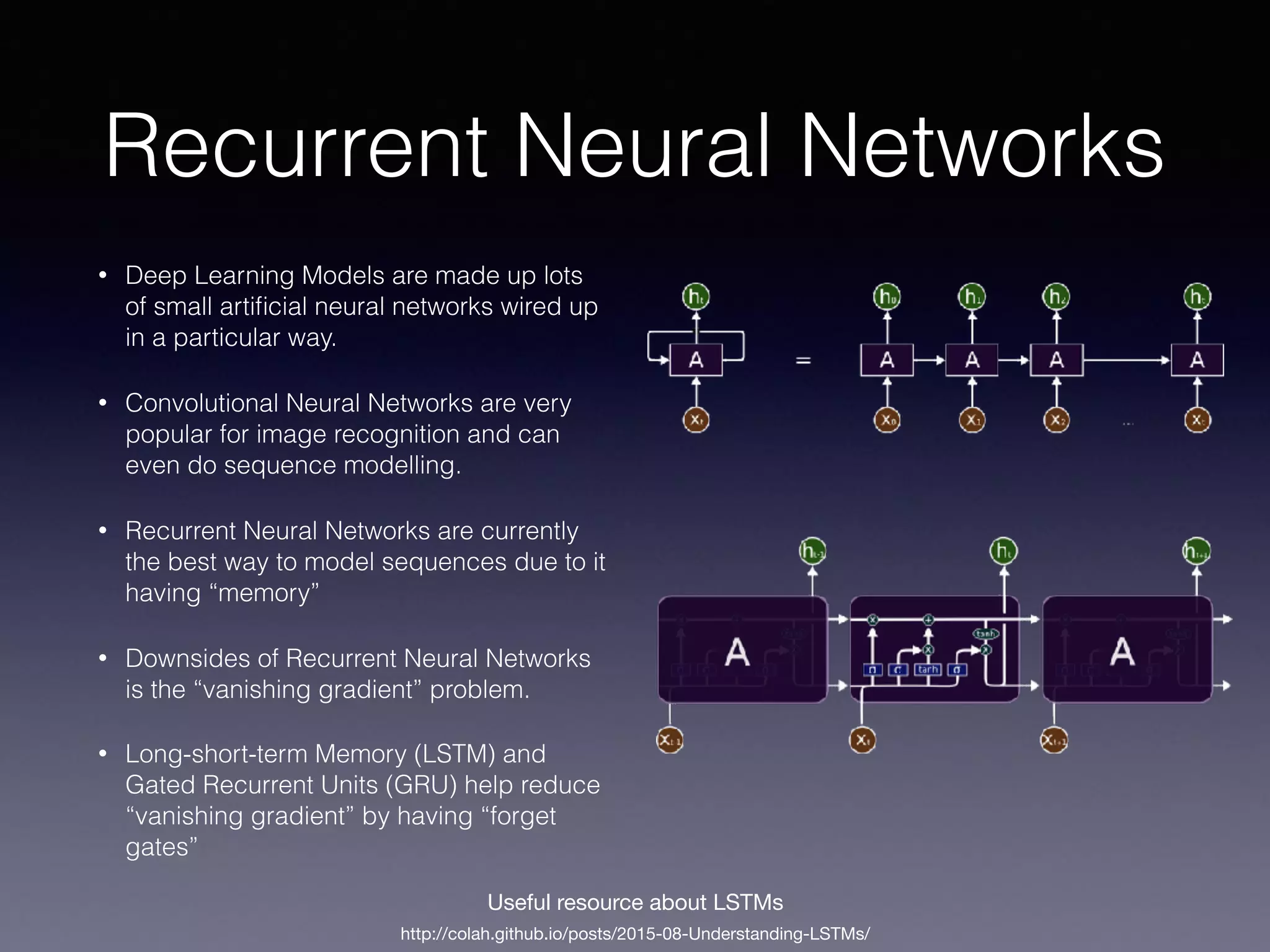
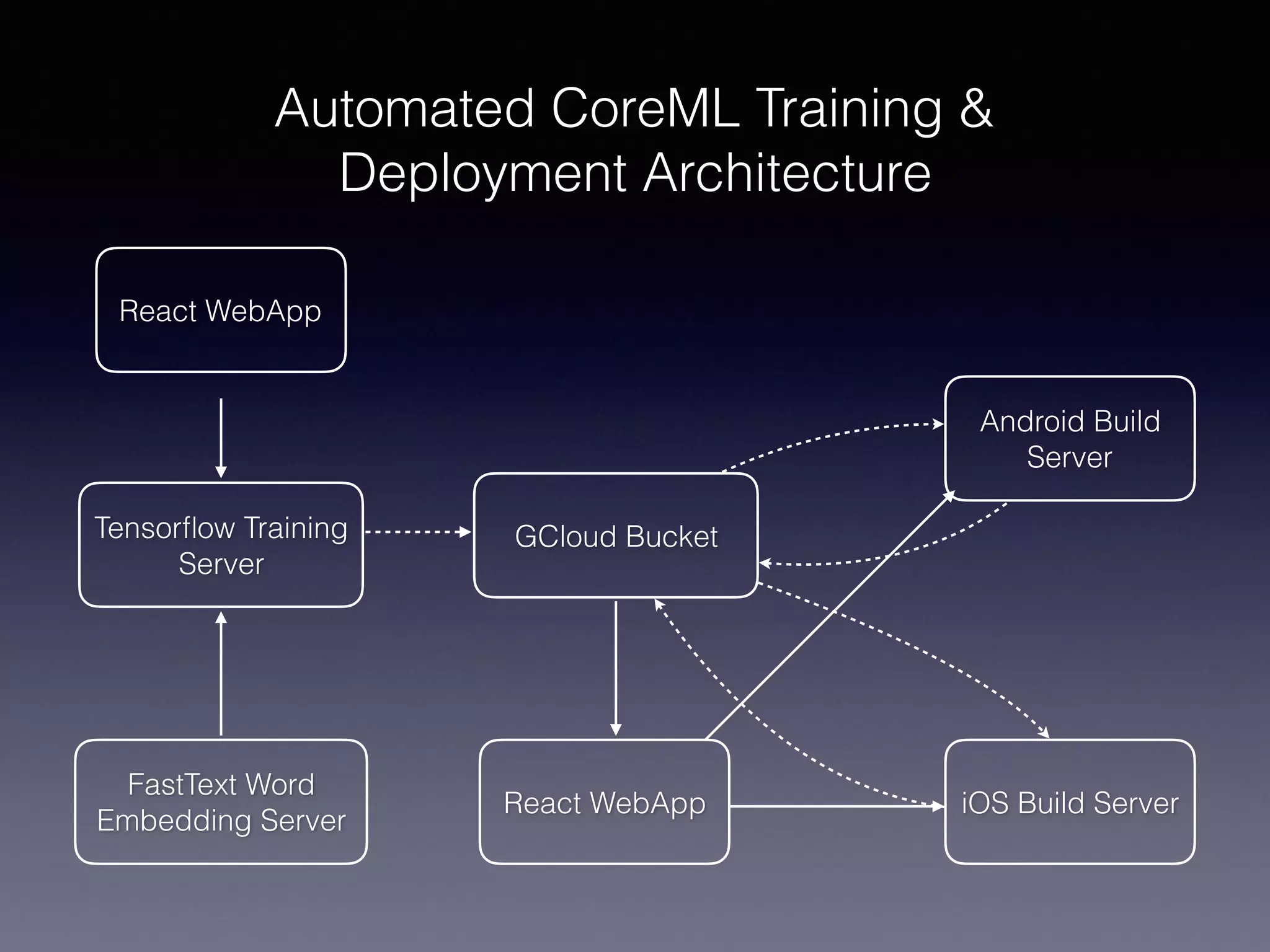
This document provides an overview of using CoreML for natural language processing (NLP) tasks on Android and iOS. It discusses topics like word embeddings, recurrent neural networks, using Keras/Tensorflow models with CoreML, and an automated workflow for training models and deploying them to Android and iOS. It describes using FastText word embeddings to vectorize text, building recurrent neural network models in Keras, converting models to CoreML format, and using Jinja templating to generate code for integrating models into mobile applications. The overall goal is to automatically train NLP models and deploy them to mobile in a way that supports offline usage.















































