Download as PDF, PPTX













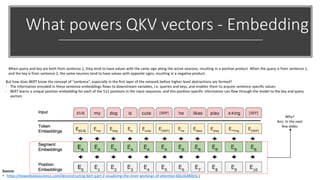

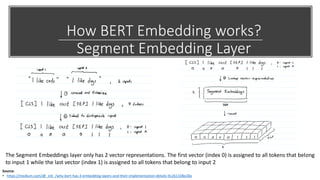
![How BERT Embedding works?
Token Embedding Layer
Source:
• https://medium.com/@_init_/why-bert-has-3-embedding-layers-and-their-implementation-details-9c261108e28a
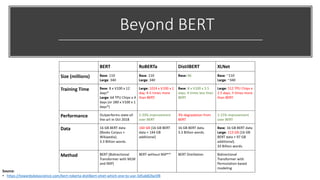
• In BERTbase, each word is represented as a 768-dimensional vector; In
BERTlarge, each word is represented in 1024d
• The input text is first tokenized before it gets passed to the Token
Embeddings layer
• [CLS] – Extra token for Classification Tasks
• [SEP] – Extra token for Sentence pair classification, Q/A pair, etc.,
• Tokenization method – WordPiece Tokenization
• WordPiece tokenization enables BERT to only store 30,522 “words” in
the vocabulary
More about how WordPiece Tokenization works
https://medium.com/@makcedward/how-subword-helps-on-your-nlp-model-83dd1b836f46](https://image.slidesharecdn.com/bertnotespart2-191215082546/85/BERT-Part-2-Learning-Notes-22-320.jpg)









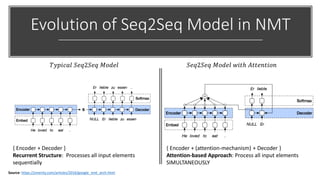
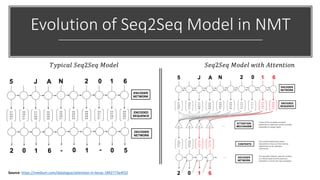
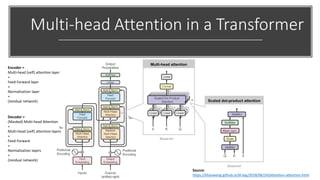
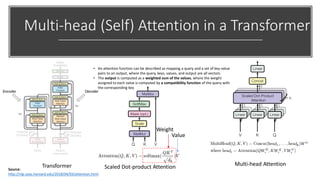
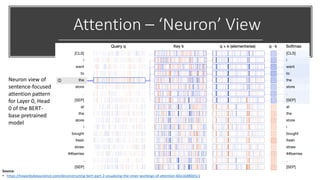
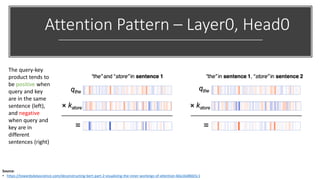
The document provides a comprehensive overview of BERT (Bidirectional Encoder Representations from Transformers) architecture, explaining its use of attention mechanisms and multi-head attention in natural language processing. It emphasizes the significance of self-attention for understanding input sequences and describes how BERT embedding works through token, segment, and position embeddings. Additionally, it discusses the evolution of sequence-to-sequence models and contrasts traditional approaches with attention-driven methods, detailing the benefits and limitations of each.
































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)















![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






