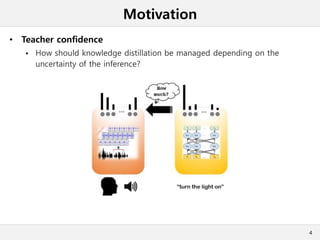
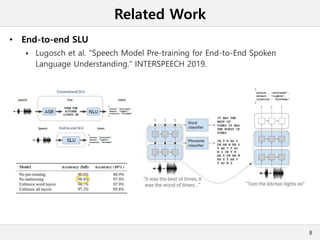
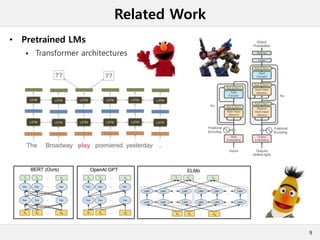
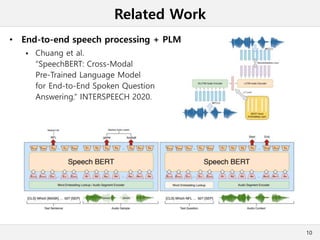
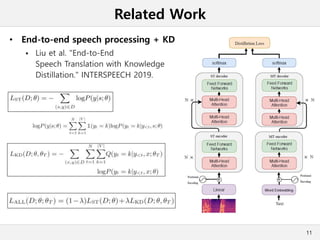
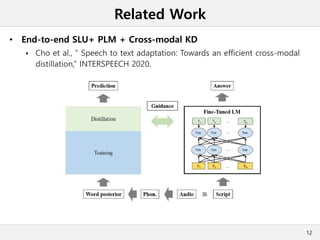
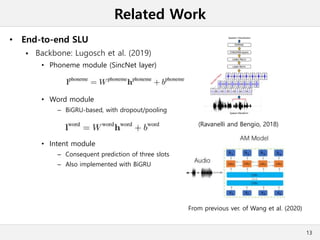
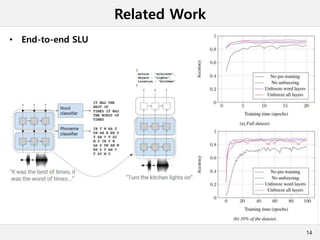
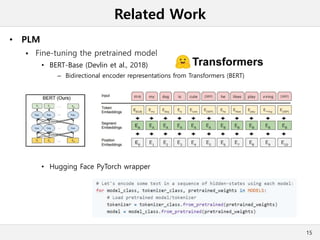
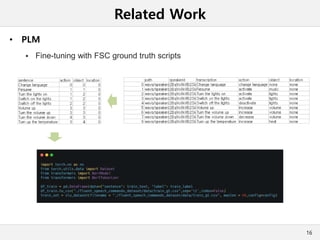
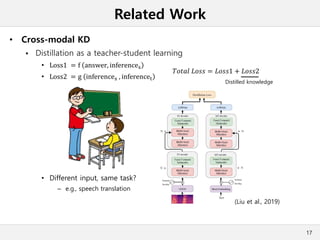
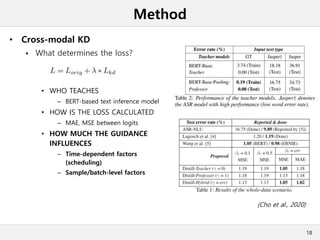
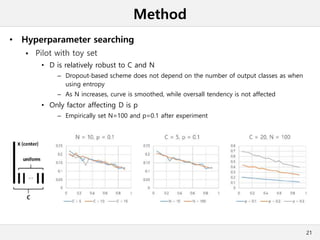
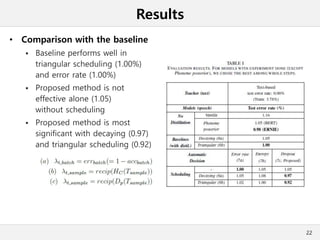
This document presents a method for cross-modal knowledge distillation from text to speech models using dropout-based teacher confidence. It aims to leverage large pre-trained language models trained on text for speech tasks by distilling knowledge from a text-based BERT model to an end-to-end speech understanding model. The method uses dropout perturbations on the teacher's logits to calculate a confidence score for each sample, which is then used to weight the distillation loss and guide the training of the student speech model, especially when combined with scheduling strategies like decaying and triangular schedules. The method is evaluated on a public spoken language understanding dataset and shows improvements over baseline distillation, demonstrating the effectiveness of using teacher confidence to manage knowledge transfer across modal

















































![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)










![2008 [lang con2020] act!](https://cdn.slidesharecdn.com/ss_thumbnails/2008langcon2020act-200829231450-thumbnail.jpg?width=640&height=640&fit=bounds)



















