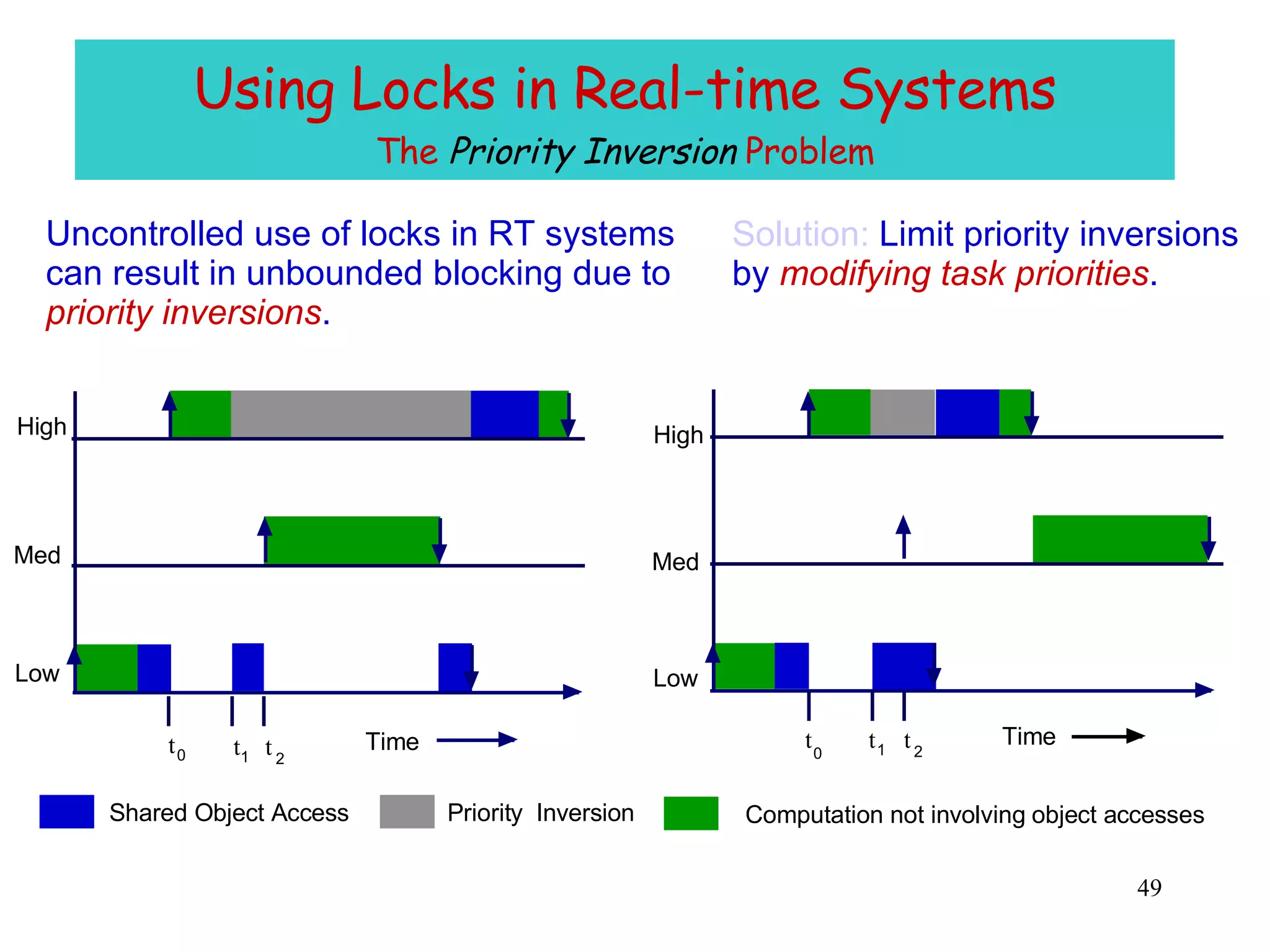
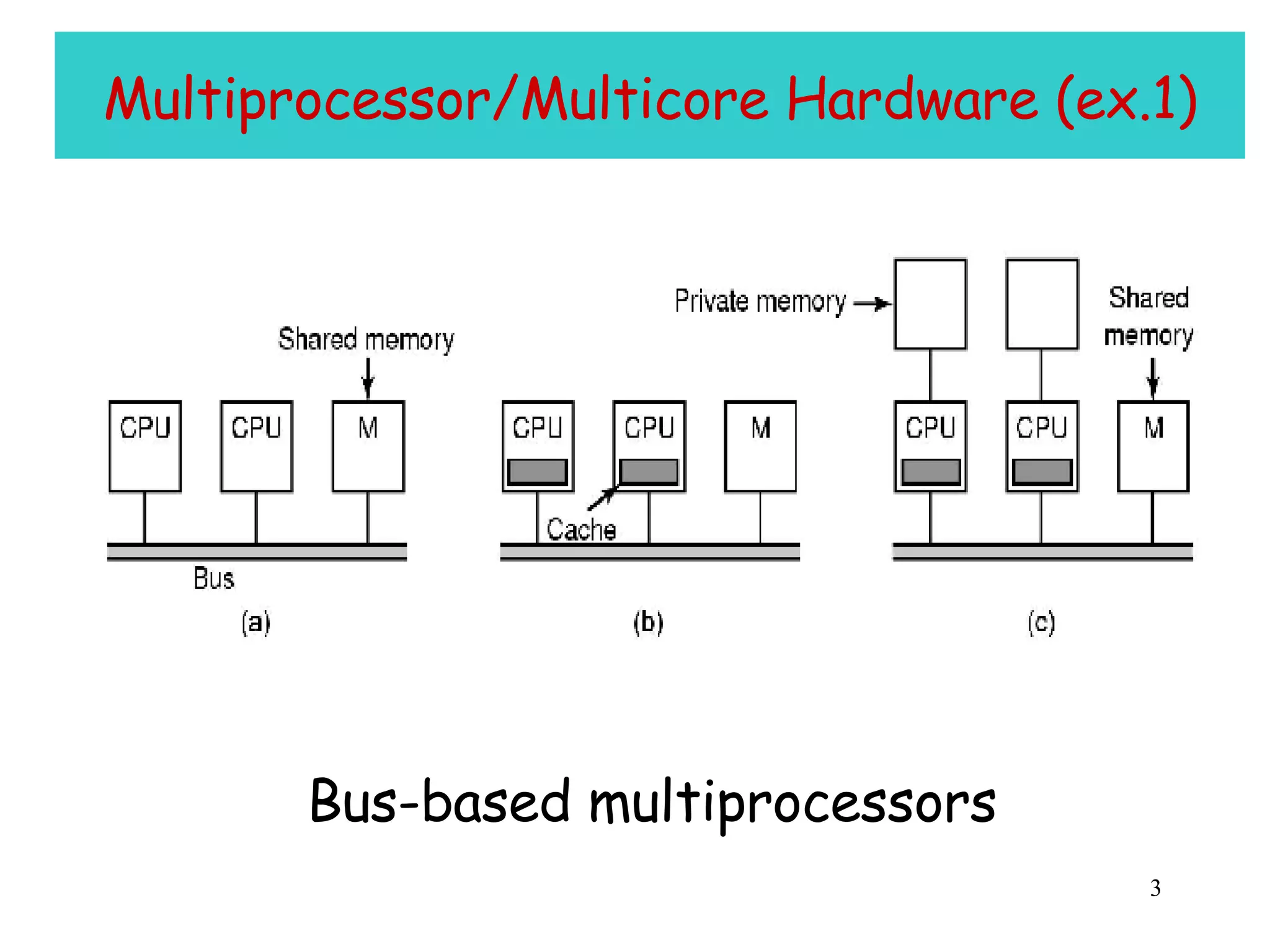
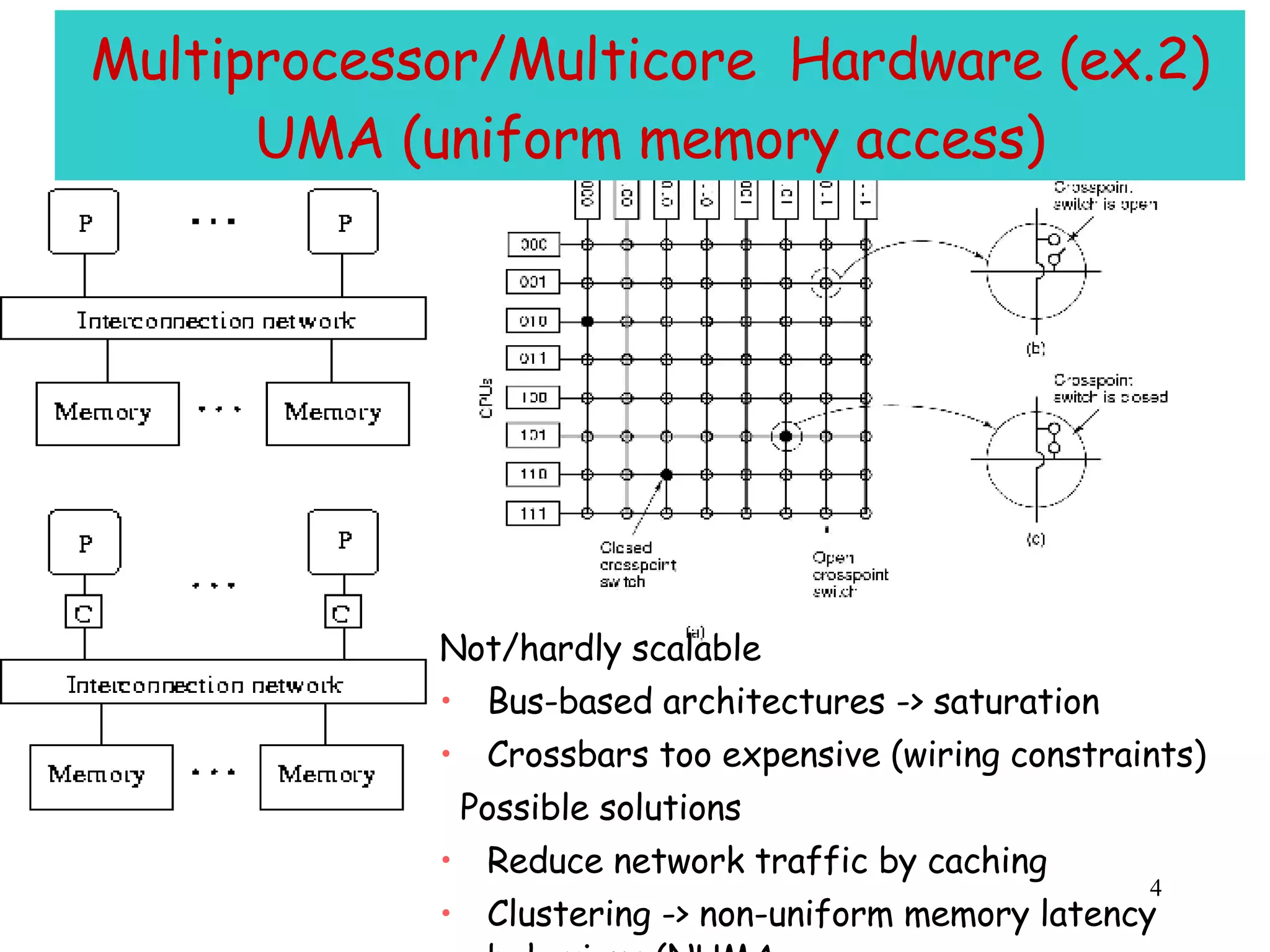
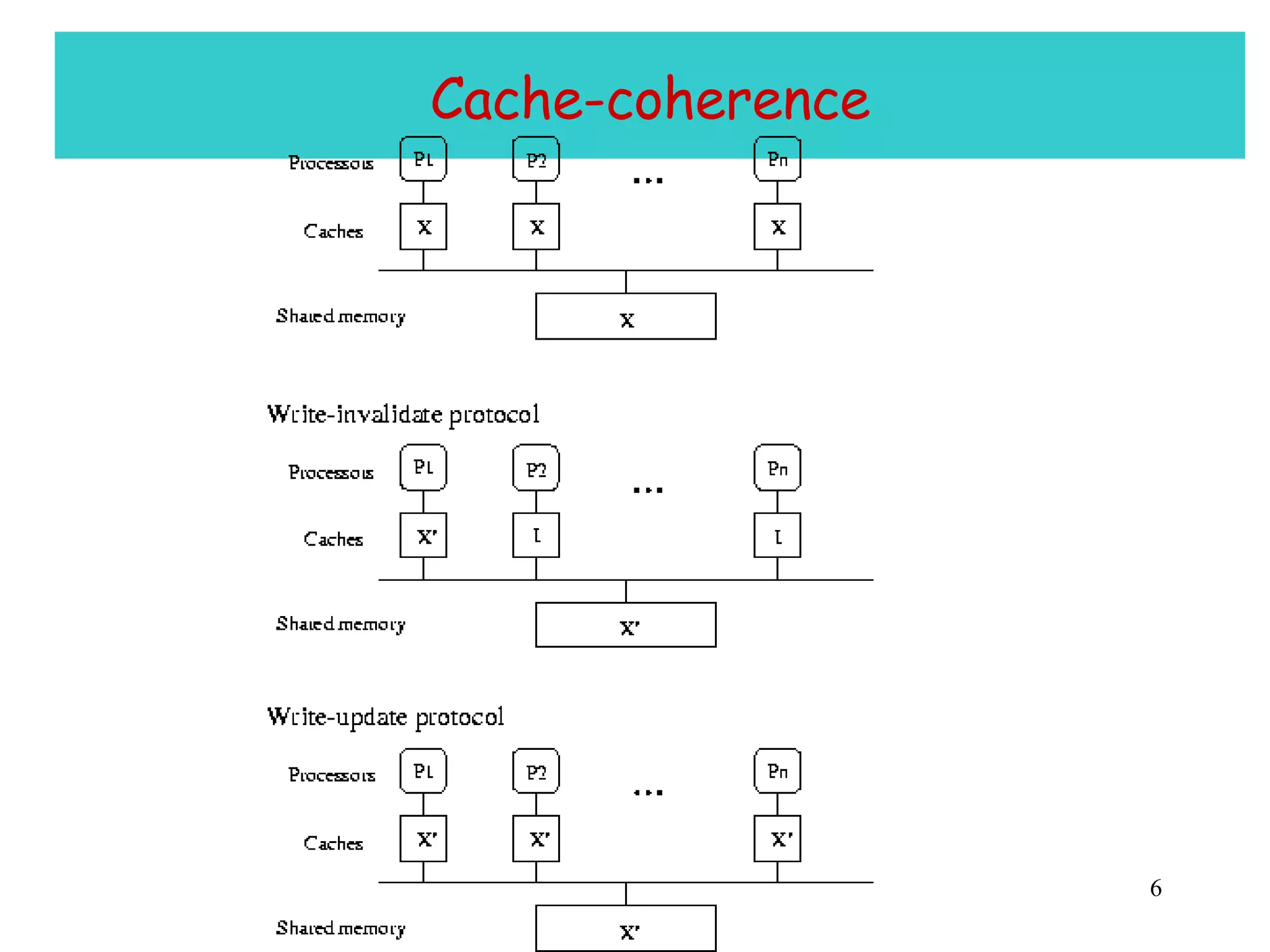
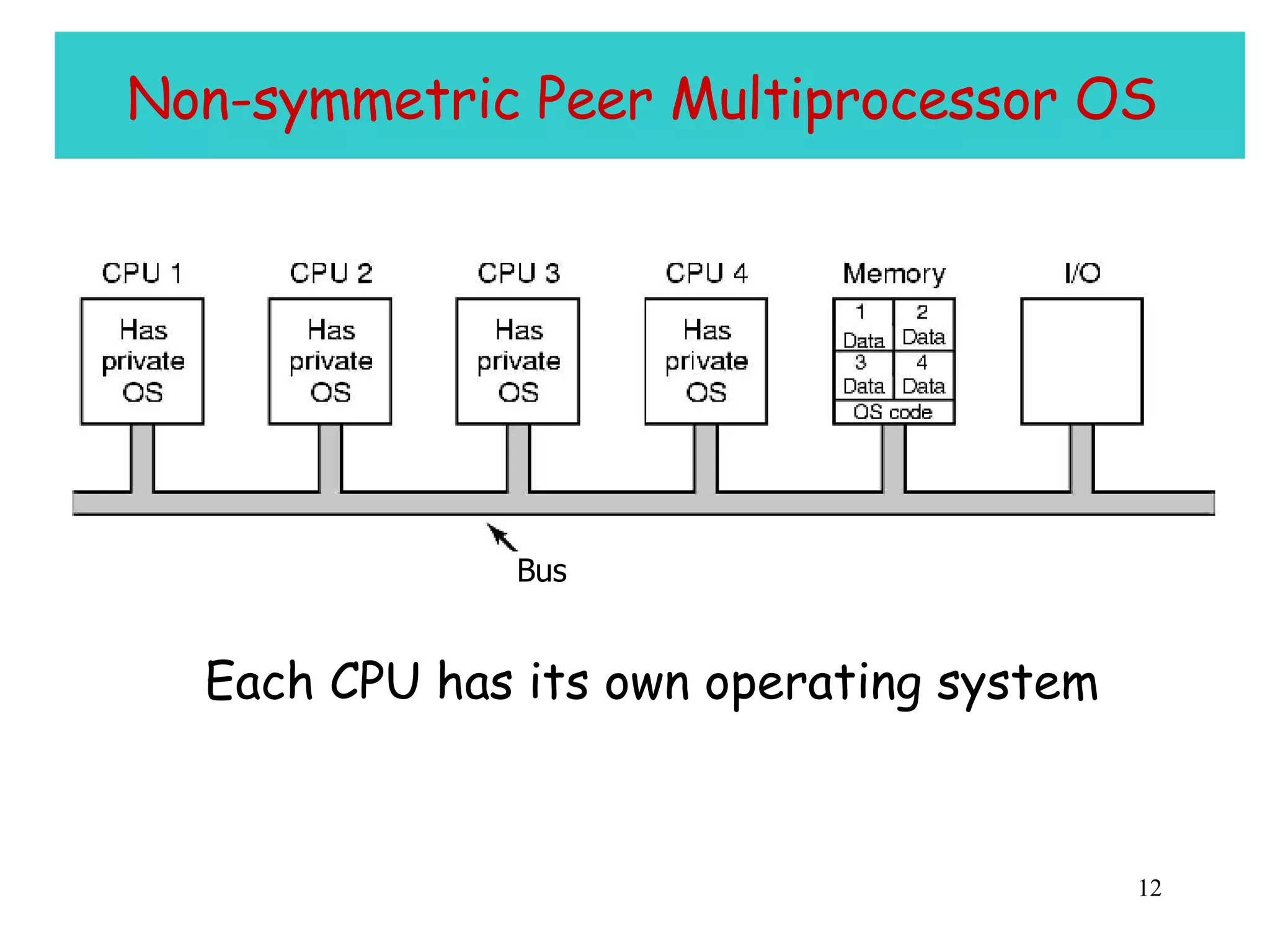
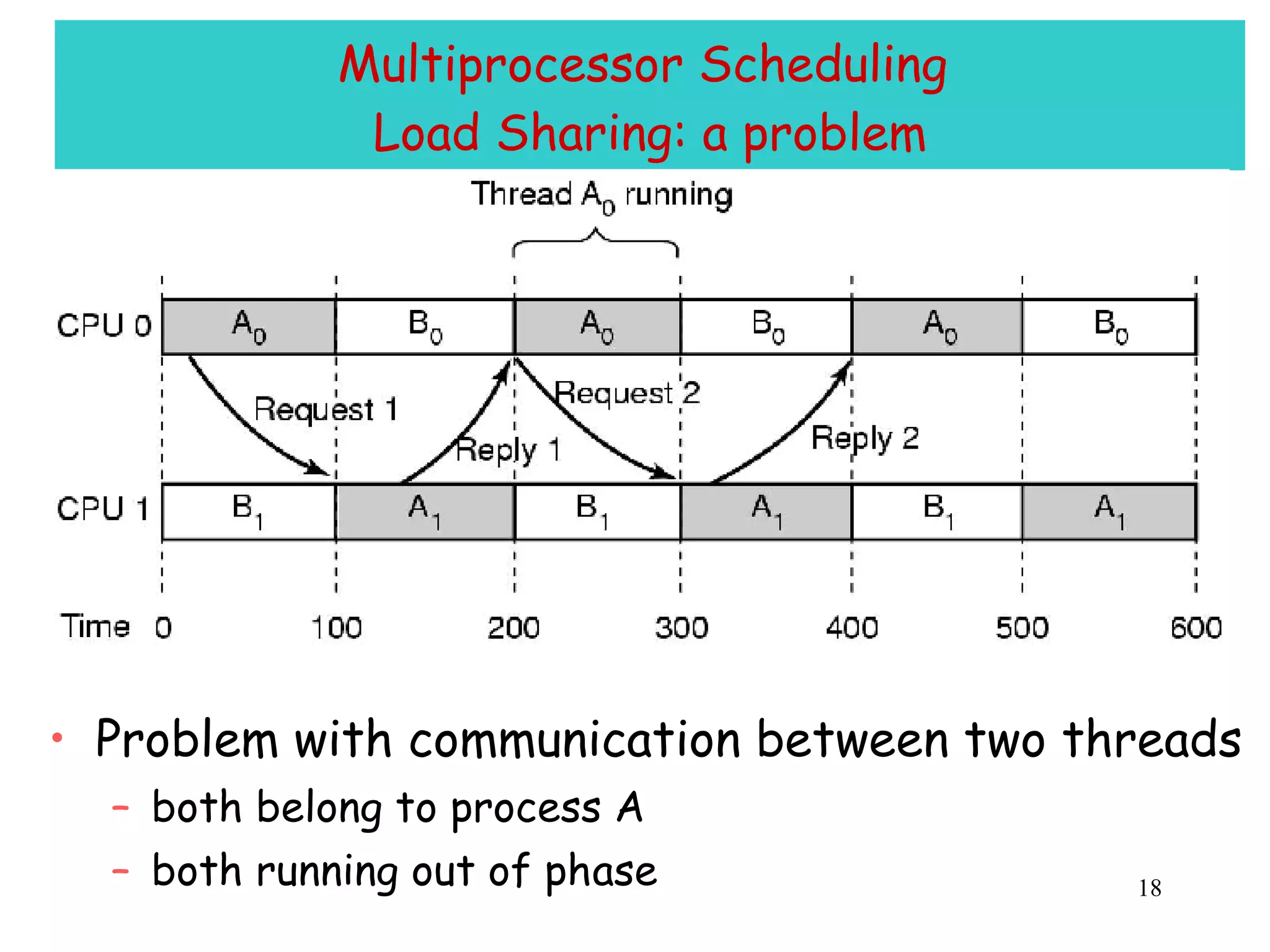
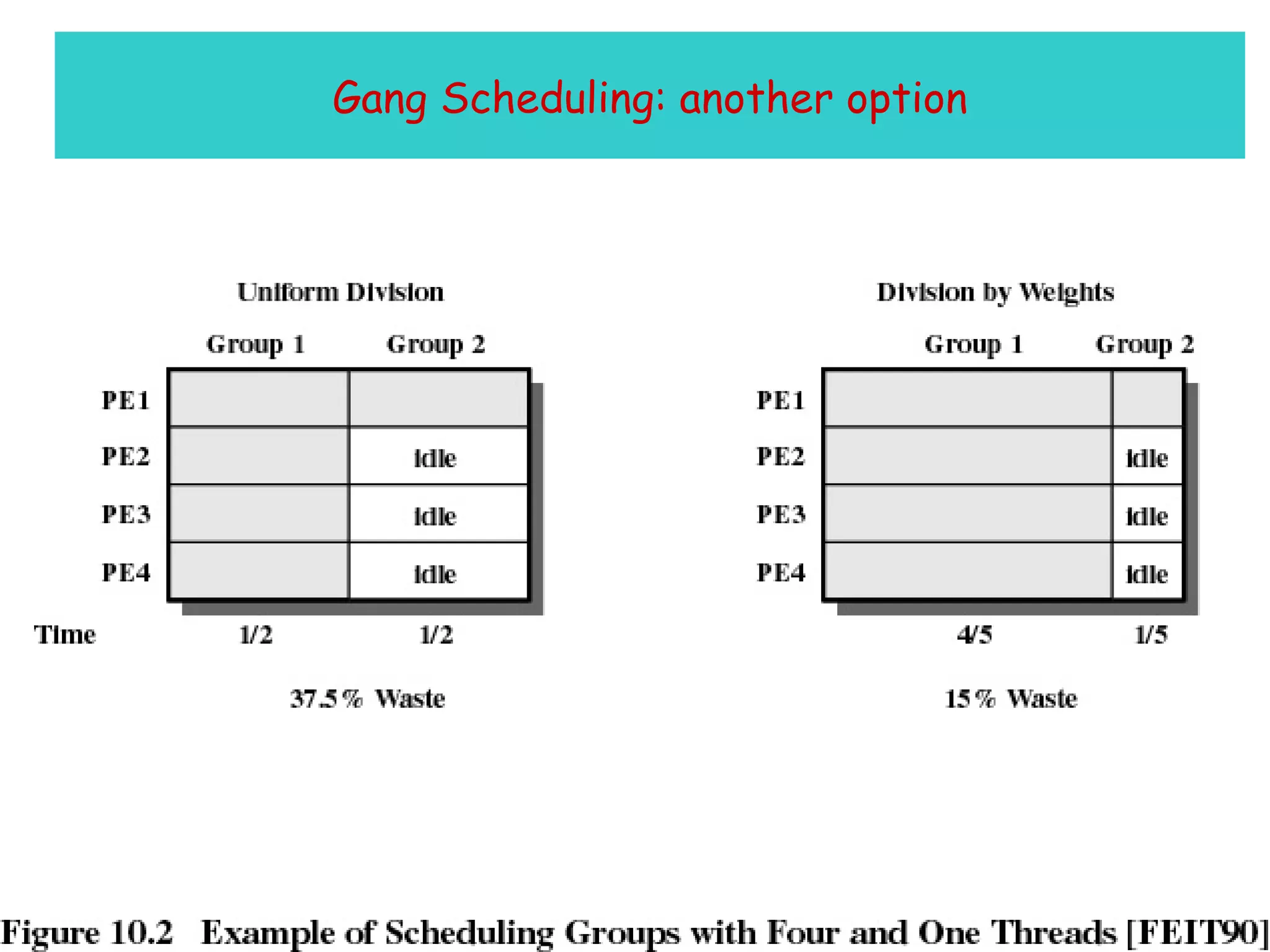
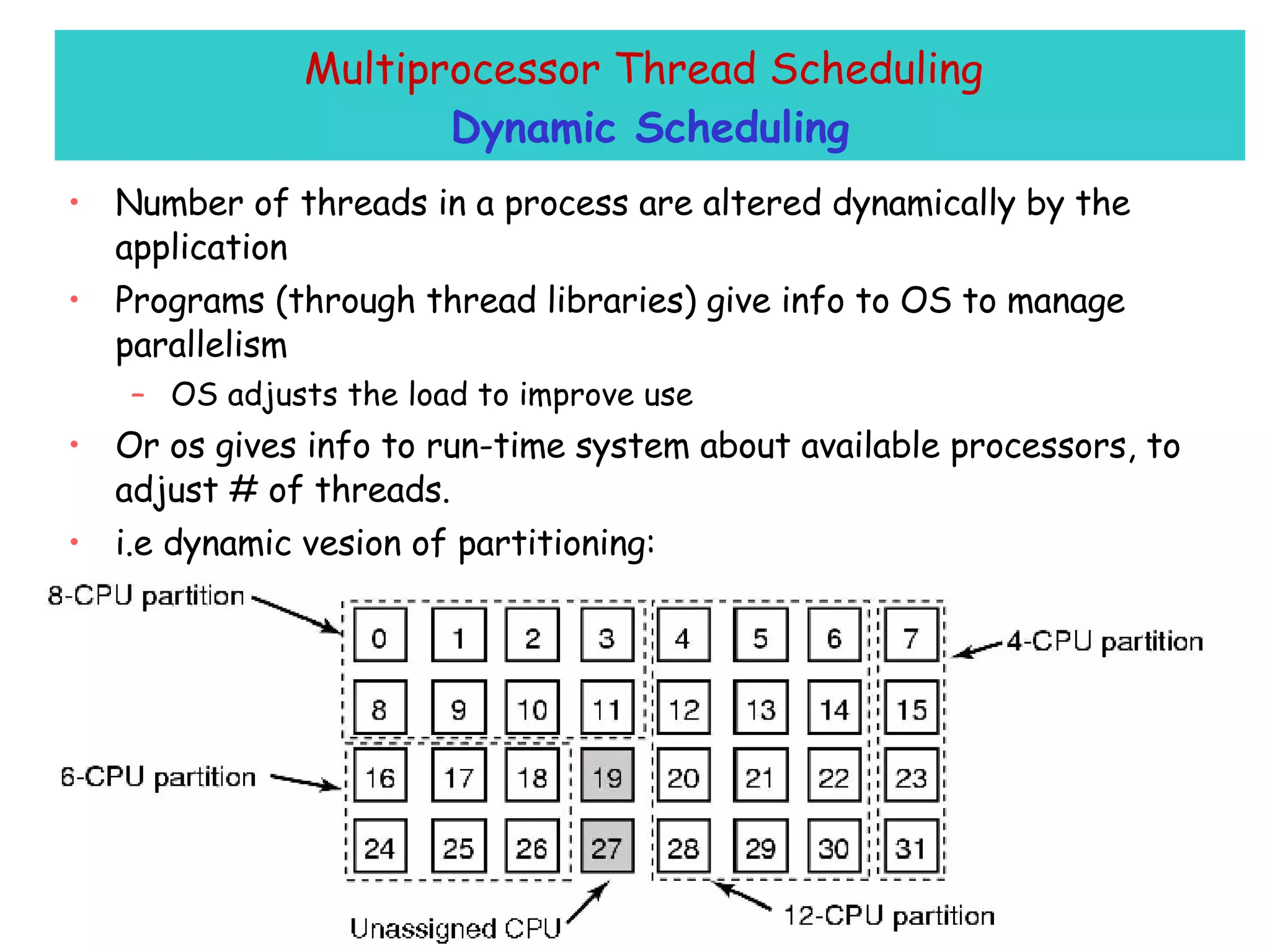
The document discusses multiprocessor and multicore systems. It defines multiprocessors as systems with two or more CPUs sharing full access to common RAM. It describes different hardware architectures for multiprocessors like bus-based, UMA, and NUMA systems. It discusses cache coherence protocols and issues like false sharing. It also covers scheduling and synchronization challenges in multiprocessor systems like load balancing, task assignment, and avoiding priority inversions.





















![Readers/Writers Problem [Courtois, et al. 1971.] Similar to mutual exclusion, but several readers can execute critical section at once . If a writer is in its critical section, then no other process can be in its critical section . + no starvation, fairness](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-29-2048.jpg)



![Concurrent Reading and Writing [Lamport ‘77] Previous solutions to the readers/writers problem use some form of mutual exclusion . Lamport considers solutions in which readers and writers access a shared object concurrently . Motivation: Don’t want writers to wait for readers. Readers/writers solution may be needed to implement mutual exclusion (circularity problem).](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-33-2048.jpg)


![Preliminaries Definition: v [ i ] , where i 0, denotes the i th value written to v. (v [0] is v ’s initial value.) Note: No concurrent writing of v . Partitioning of v : v 1 v m . v i may consist of multiple digits . To read v : Read each v i (in some order). To write v : Write each v i (in some order).](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-36-2048.jpg)
![More Preliminaries We say: r reads v [ k,l ] . Value is consistent if k = l . write: k write: k + i write: l read v 3 read v 2 read v m -1 read v 1 read v m read r: ](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-37-2048.jpg)
![Theorem 1 If v is always written from right to left, then a read from left to right obtains a value v 1 [ k 1 , l 1 ] v 2 [ k 2 , l 2 ] … v m [ k m , l m ] where k 1 l 1 k 2 l 2 … k m l m . Example: v = v 1 v 2 v 3 = d 1 d 2 d 3 Read reads v 1 [0,0] v 2 [1,1] v 3 [2,2] . read : read v 1 read d 1 read v 2 read d 2 read v 3 read d 3 write:1 w v 3 w v 2 w v 1 w d 3 w d 2 w d 1 write:0 w v 3 w v 2 w v 1 w d 3 w d 2 w d 1 write:2 w v 3 w v 2 w v 1 w d 3 w d 2 w d 1](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-38-2048.jpg)
![Another Example read : write:0 w v 2 w v 1 w d 3 w d 4 w d 1 w d 2 write:1 w v 2 w v 1 w d 3 w d 4 w d 1 w d 2 read v 1 r d 1 r d 2 read v 2 r d 4 r d 3 v = v 1 v 2 d 1 d 2 d 3 d 4 Read reads v 1 [0,1] v 2 [1,2] . write:2 w v 2 w v 1 w d 3 w d 4 w d 1 w d 2](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-39-2048.jpg)
![Theorem 2 Assume that i j implies that v [ i ] v [ j ] , where v = d 1 … d m . (a) If v is always written from right to left, then a read from left to right obtains a value v [ k , l ] v [ l ] . (b) If v is always written from left to right, then a read from right to left obtains a value v [ k , l ] v [ k ] .](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-40-2048.jpg)
![Example of (a) v = d 1 d 2 d 3 Read obtains v [0,2] = 390 < 400 = v [2] . read : read d 1 read d 2 read d 3 write:1(399) w d 3 w d 2 w d 1 9 9 3 write:0(398) w d 3 w d 2 w d 1 8 9 3 write:2(400) w d 3 w d 2 w d 1 0 0 4](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-41-2048.jpg)
![Example of (b) v = d 1 d 2 d 3 Read obtains v [0,2] = 498 > 398 = v [0] . read : read d 3 read d 2 read d 1 write:1(399) w d 1 w d 2 w d 3 3 9 9 write:0(398) w d 1 w d 2 w d 3 3 9 8 write:2(400) w d 1 w d 2 w d 3 4 0 0](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-42-2048.jpg)

![Proof Obligation Assume reader reads V2 [ k 1 , l 1 ] D [ k 2 , l 2 ] V1 [ k 3 , l 3 ] . Proof Obligation: V2 [ k 1 , l 1 ] = V1 [ k 3 , l 3 ] k 2 = l 2 .](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-44-2048.jpg)
![Proof By Theorem 2, V2 [ k 1 , l 1 ] V2 [ l 1 ] and V1 [ k 3 ] V1 [ k 3 , l 3 ] . (1) Applying Theorem 1 to V2 D V1, k 1 l 1 k 2 l 2 k 3 l 3 . (2) By the writer program, l 1 k 3 V2 [ l 1 ] V1 [ k 3 ] . (3) (1), (2), and (3) imply V2 [ k 1 , l 1 ] V2 [ l 1 ] V1 [ k 3 ] V1 [ k 3 , l 3 ] . Hence, V2 [ k 1 , l 1 ] = V1 [ k 3 , l 3 ] V2 [ l 1 ] = V1 [ k 3 ] l 1 = k 3 , by the writer’s program. k 2 = l 2 by (2).](https://image.slidesharecdn.com/10multicore07-1211330236462564-9/75/10-Multicore-07-45-2048.jpg)