Downloaded 88 times




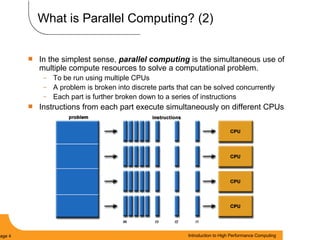










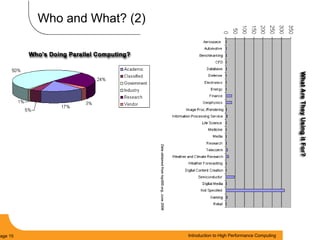


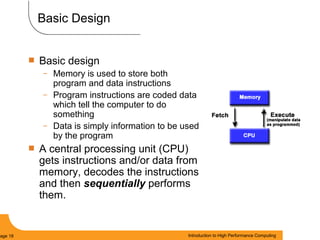














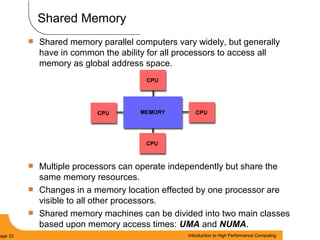


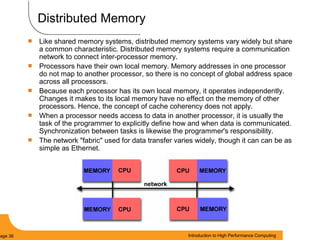

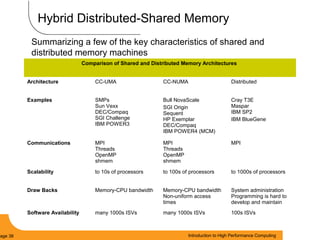
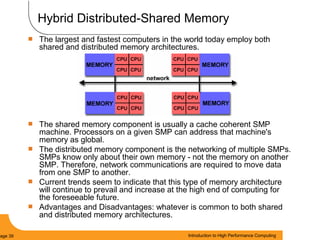








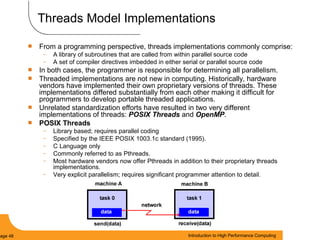



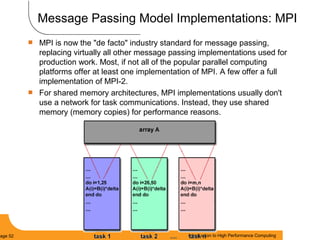






















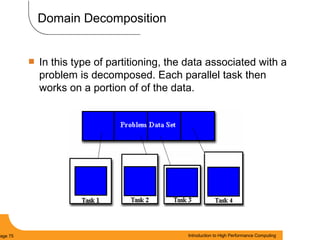
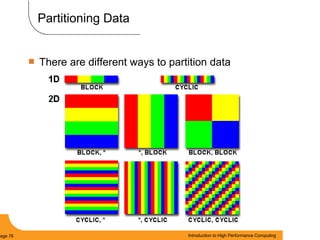
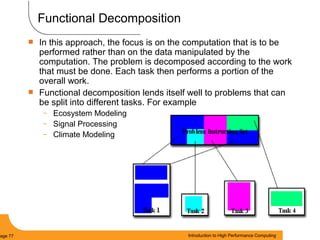
























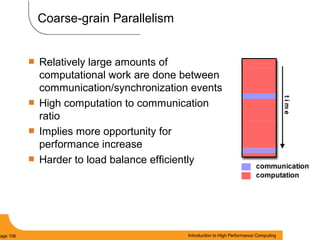




























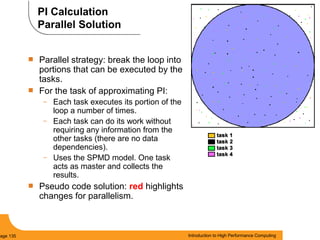







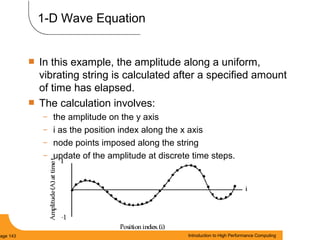

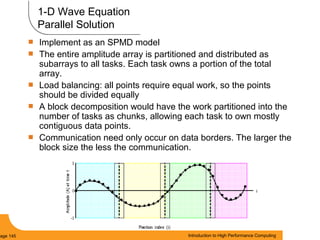



This document provides an introduction to parallel computing. It begins with definitions of parallel computing as using multiple compute resources simultaneously to solve problems. Popular parallel architectures include shared memory, where all processors can access a common memory, and distributed memory, where each processor has its own local memory and they communicate over a network. The document discusses key parallel computing concepts and terminology such as Flynn's taxonomy, parallel overhead, scalability, and memory models including uniform memory access (UMA), non-uniform memory access (NUMA), and distributed memory. It aims to provide background on parallel computing topics before examining how to parallelize different types of programs.






























































![Wondershare Filmora 14 Crack With Activation Key [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture78-250324100902-a498a90d-thumbnail.jpg?width=640&height=640&fit=bounds)























