Downloaded 32 times


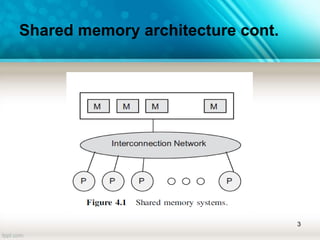



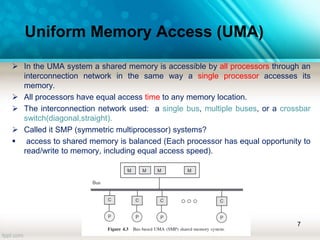














The document discusses shared memory architecture in multiprocessor systems, focusing on communication, coordination, and coherence among processors using a global memory. It outlines the classifications of shared memory systems, including Uniform Memory Access (UMA), Non-Uniform Memory Access (NUMA), and Cache-Only Memory Architecture (COMA), while addressing performance issues such as contention and coherence problems. Additionally, it explains various cache coherence methods necessary to maintain data consistency across multiple caches and provides insights into the design and operation of bus-based symmetric multiprocessors.



































































