Downloaded 283 times






















![Producer-Consumer Problem
Producer
while (true) {
/* produce an item and put in
nextProduced */
while (count == BUFFER_SIZE); // do
nothing
buffer [in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
count++;
}
count: the number of items in the
buffer (initialized to 0)
Consumer
while (true) {
while (count == 0); // do nothing
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
count--;
// consume the item in nextConsumed
}
What can go wrong in concurrent
execution?](https://image.slidesharecdn.com/unitv-151031072101-lva1-app6892/75/CS9222-ADVANCED-OPERATING-SYSTEMS-26-2048.jpg)



![Peterson’s Solution
Simple 2-process solution
Assume that the LOAD and STORE instructions are
atomic; that is, cannot be interrupted.
The two processes share two variables:
int turn;
Boolean flag[2]
The variable turn indicates whose turn it is to enter
the critical section.
The flag array is used to indicate if a process is ready
to enter the critical section. flag[i] = true implies that
process Pi is ready!](https://image.slidesharecdn.com/unitv-151031072101-lva1-app6892/75/CS9222-ADVANCED-OPERATING-SYSTEMS-30-2048.jpg)
![Algorithm for Process Pi
while (true) {
flag[i] = TRUE;
turn = j;
while ( flag[j] && turn == j);
CRITICAL SECTION
flag[i] = FALSE;
REMAINDER SECTION
}
Mutual exclusion
Only one process enters critical section
at a time.
Proof: can both processes pass the while
loop (and enter critical section) at the
same time?
Progress
Selection for waiting-to-enter-critical-
section process does not block.
Proof: can Pi wait at the while loop
forever (after Pj leaves critical section)?
Bounded Waiting
Limited time in waiting for other
processes.
Proof: can Pj win the critical section
twice while Pi waits?
Entry Section
Exit Section](https://image.slidesharecdn.com/unitv-151031072101-lva1-app6892/75/CS9222-ADVANCED-OPERATING-SYSTEMS-31-2048.jpg)
![Algorithm for Process Pi
while (true) {
flag[i] = TRUE;
turn = j;
while ( flag[j] && turn == j);
CRITICAL SECTION
flag[i] = FALSE;
REMAINDER SECTION
}
Entry Section
Exit Section
while (true) {
flag[j] = TRUE;
turn = i;
while ( flag[i] && turn == i);
CRITICAL SECTION
flag[j] = FALSE;
REMAINDER SECTION
}](https://image.slidesharecdn.com/unitv-151031072101-lva1-app6892/75/CS9222-ADVANCED-OPERATING-SYSTEMS-32-2048.jpg)



![Bounded-Waiting TestAndSet
• Shared variable
boolean waiting[n];
boolean lock; // initialized false.
• Solution:
do {
waiting[i] = TRUE;
while (waiting[i] &&
TestAndSet(&lock);
waiting[i] = FALSE;
// critical section
j=(i+1)%n;
while ((j!=i) && !waiting[j])
j=(j+1)%n;
If (j==i) lock = FALSE;
else waiting[j] = FALSE;
// reminder section
} while (TRUE);
Mutual exclusion
Proof: can two processes pass the
while loop (and enter critical section)
at the same time?
Bounded Waiting
Limited time in waiting for other
processes.
What is waiting[] for? When does
waiting[i] set to FALSE?
Proof: how long does Pi’s wait till
waiting[i] becomes FALSE?
Progress
Proof: exit section unblocks at least
one process’s waiting[] or set the lock
to FALSE.
Entry Section
Exit Section](https://image.slidesharecdn.com/unitv-151031072101-lva1-app6892/75/CS9222-ADVANCED-OPERATING-SYSTEMS-36-2048.jpg)








































This document provides a comprehensive overview of advanced operating systems, focusing on multiprocessor architectures, process synchronization, and memory management. It discusses different multiprocessing configurations, their advantages, and associated challenges, including performance issues related to process scheduling and memory access. Additionally, it covers threading models, critical section solutions, and mechanisms for ensuring concurrency and reliability in multiprocessor systems.
Introduction to CS9222 Advanced Operating System, focusing on Unit V covering structures, design issues, threads, process synchronization, memory management, and database operating systems.
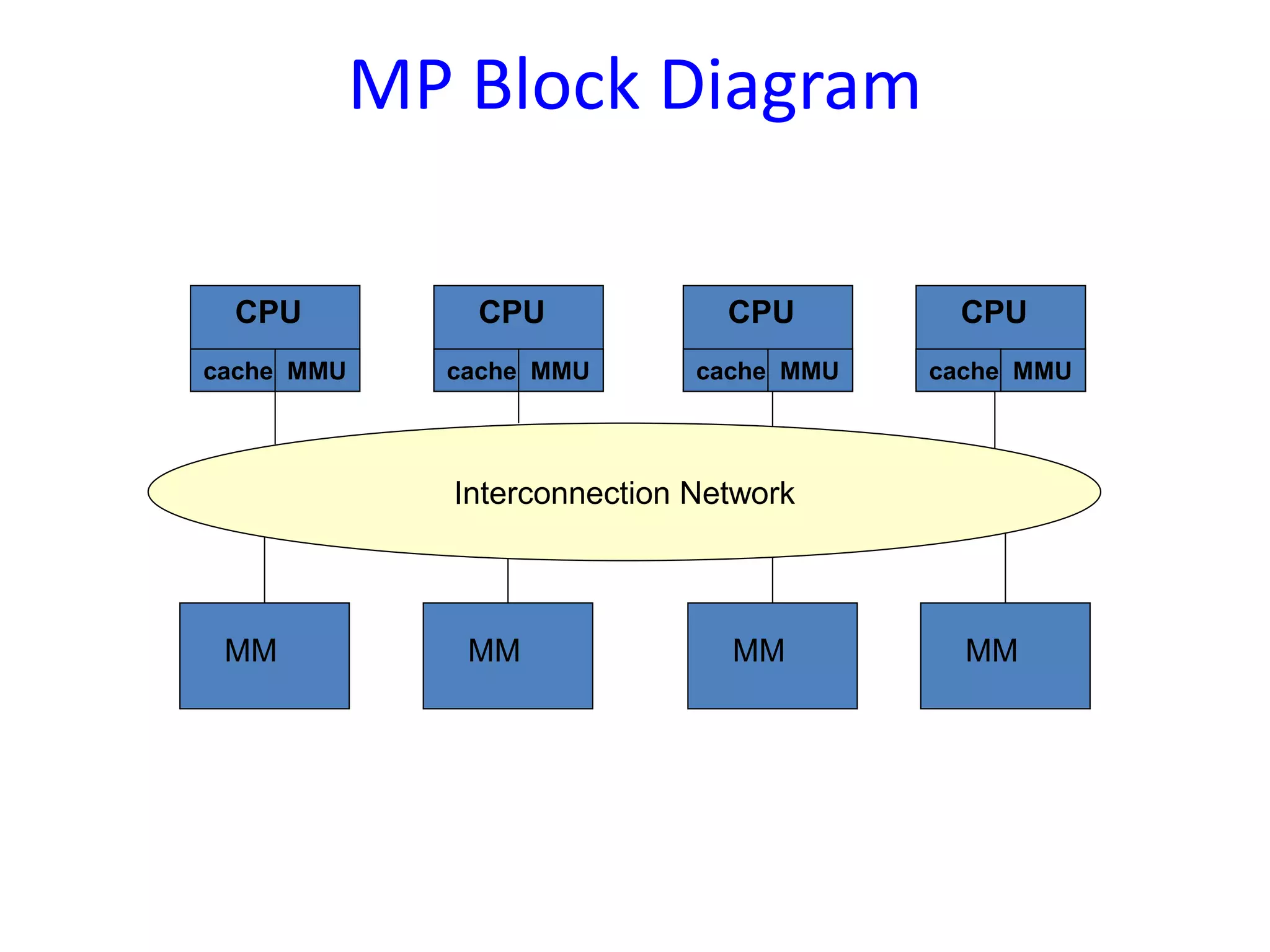
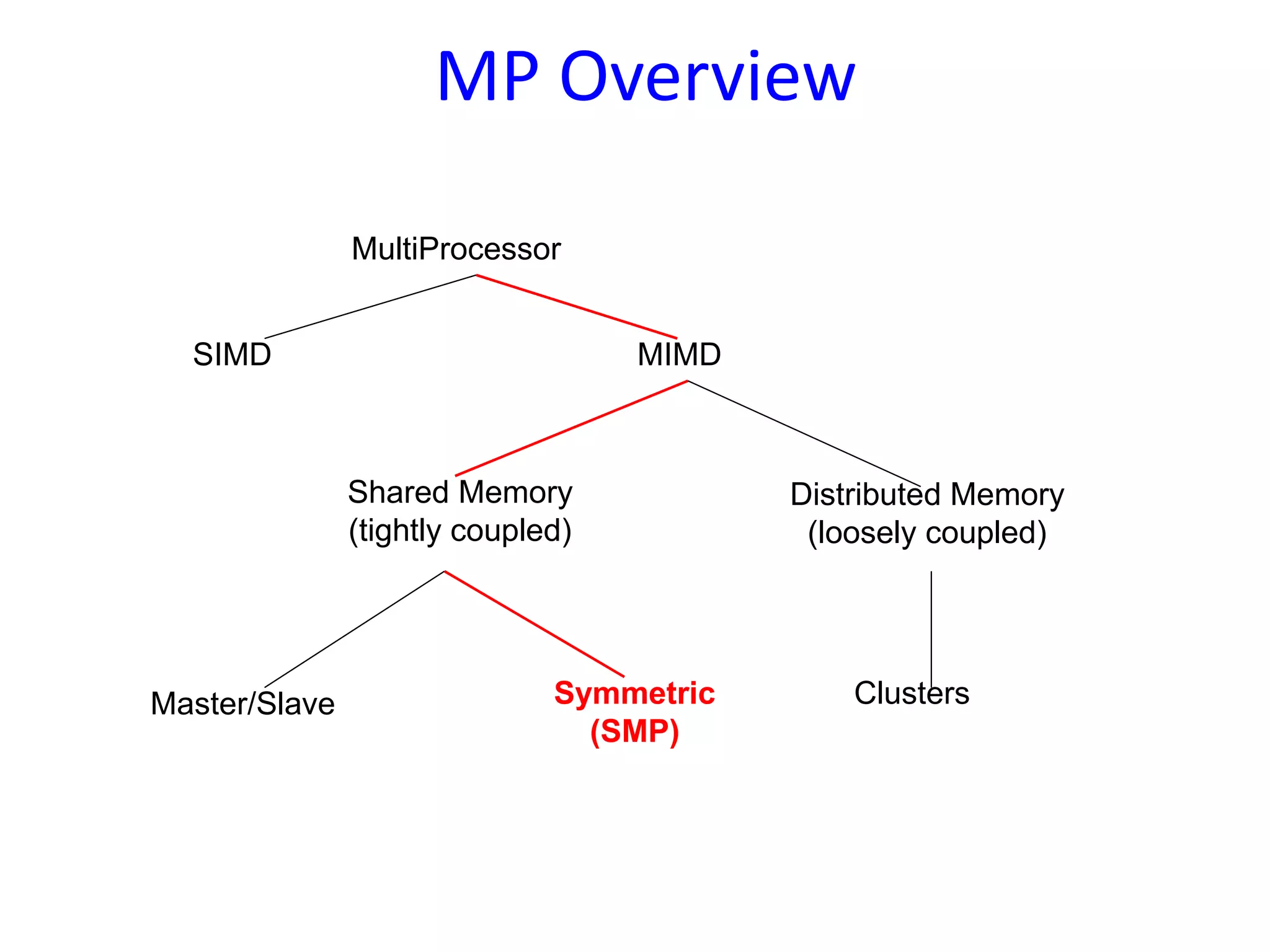
Motivations for multiprocessors include enhanced performance and fault tolerance. Discusses basic architectures (SISD, SIMD, MIMD) and memory access schemes (UMA, NUMA, NORMA).
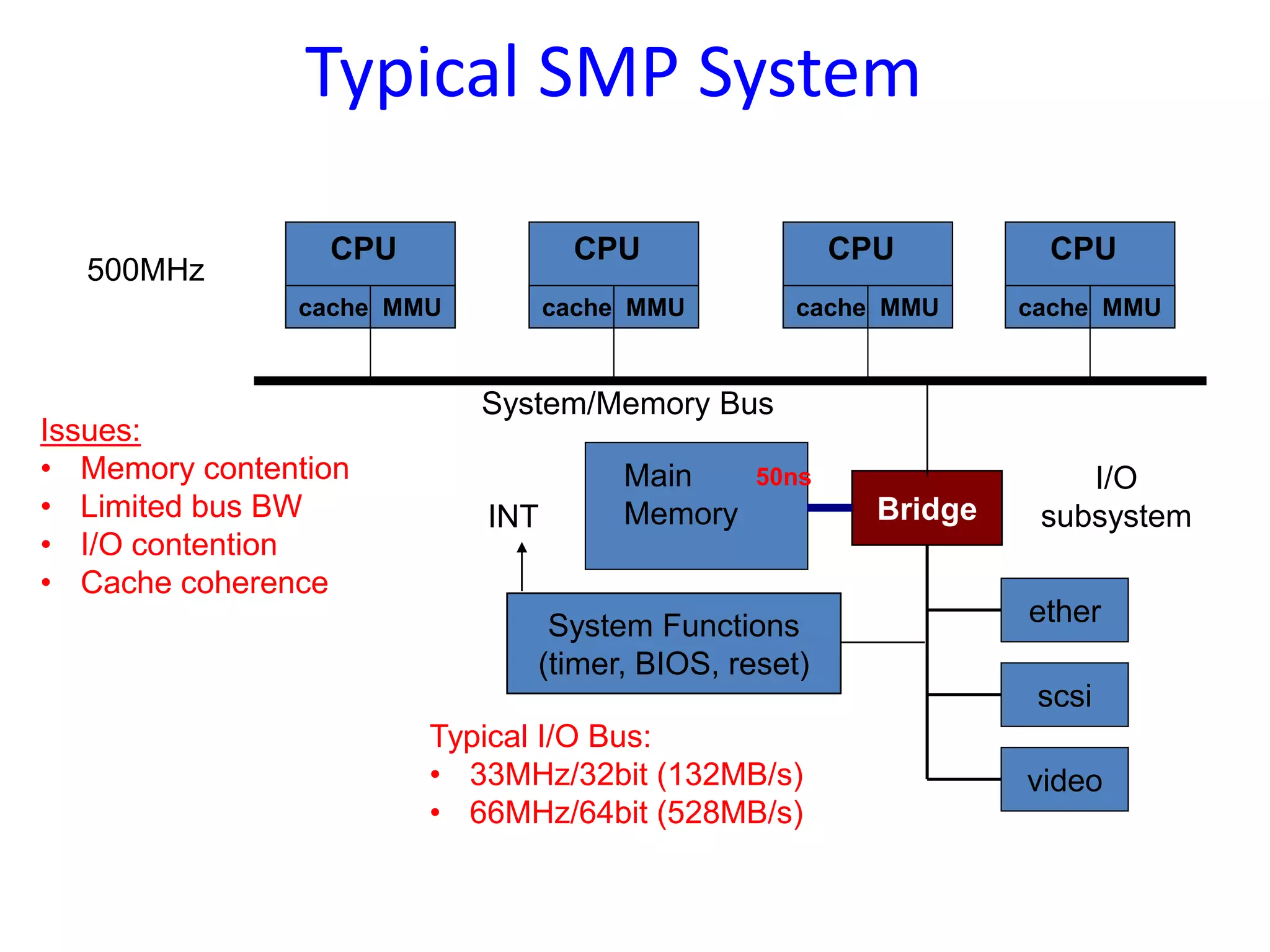
Different OS structures for multiprocessors, such as separate supervisor, master/slave configuration and symmetric configuration, detailing their strengths and weaknesses.
Design issues in SMP systems include threads, process synchronization, scheduling, memory management, and types of threads (user, kernel, LWP).
Challenges in process synchronization illustrated by the producer-consumer problem, race conditions, and critical section solutions such as Peterson’s algorithm.
Hardware support for critical section control using atomic instructions like TestAndSet and Swap to manage access to shared variables.
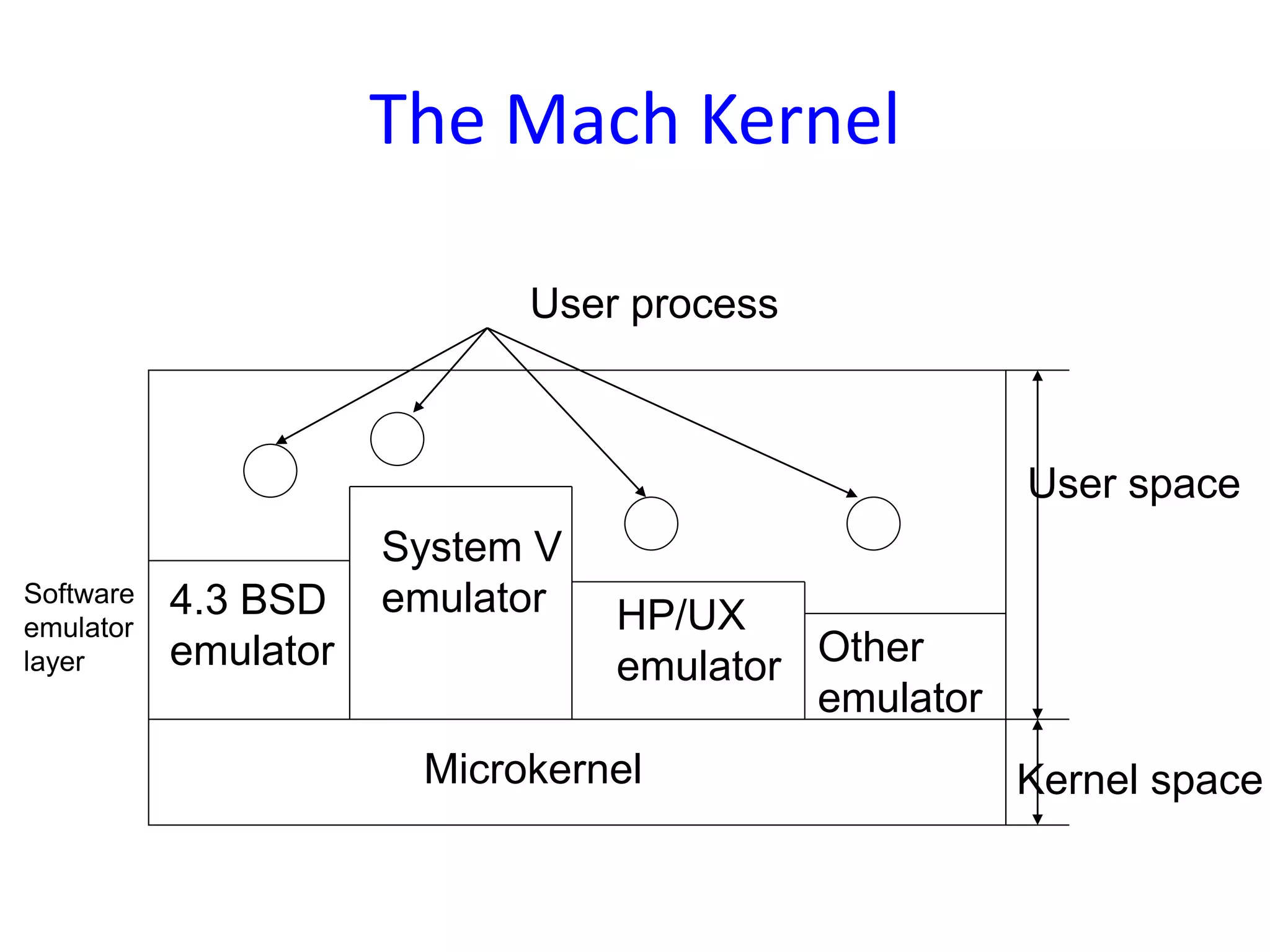
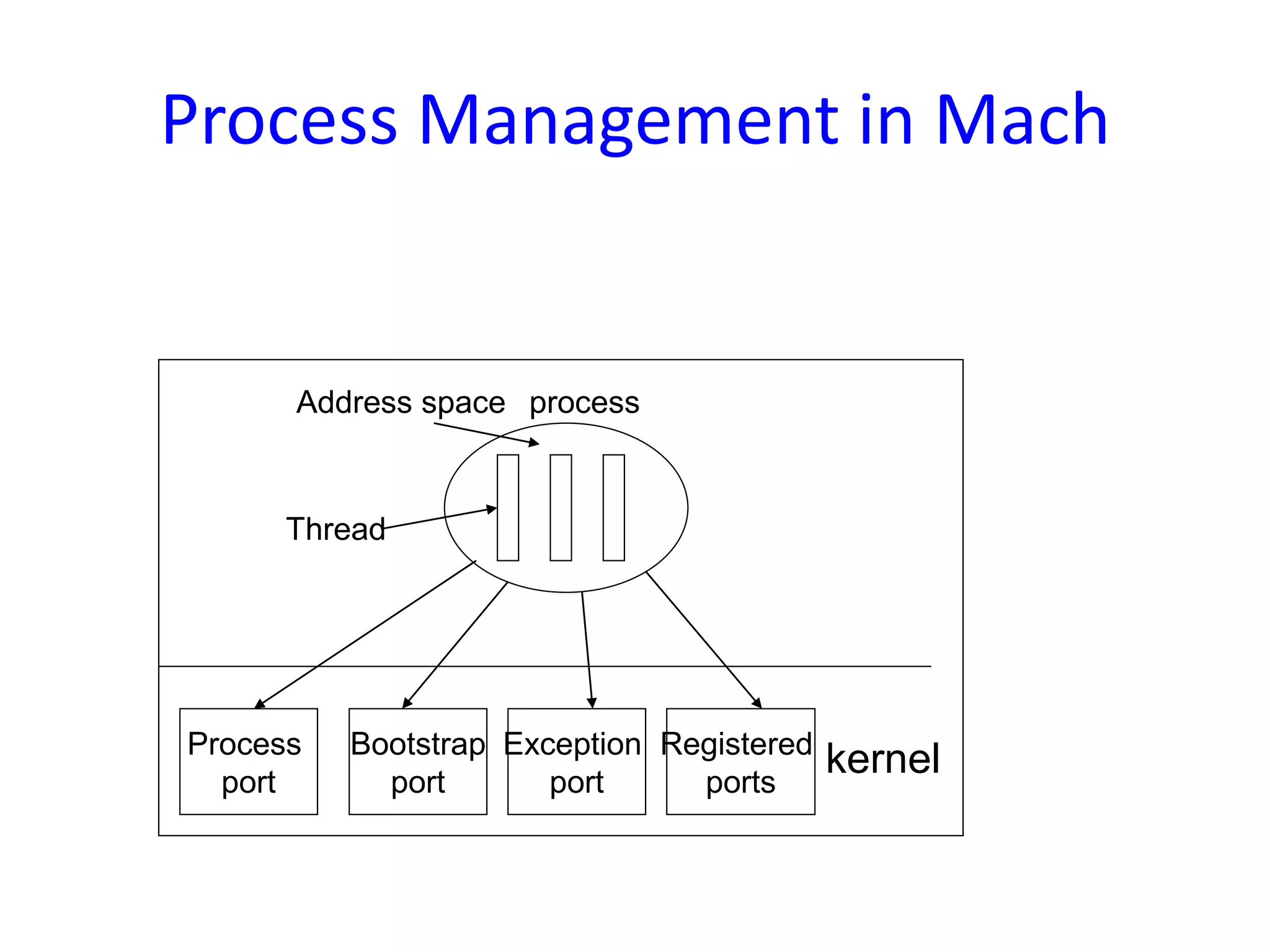
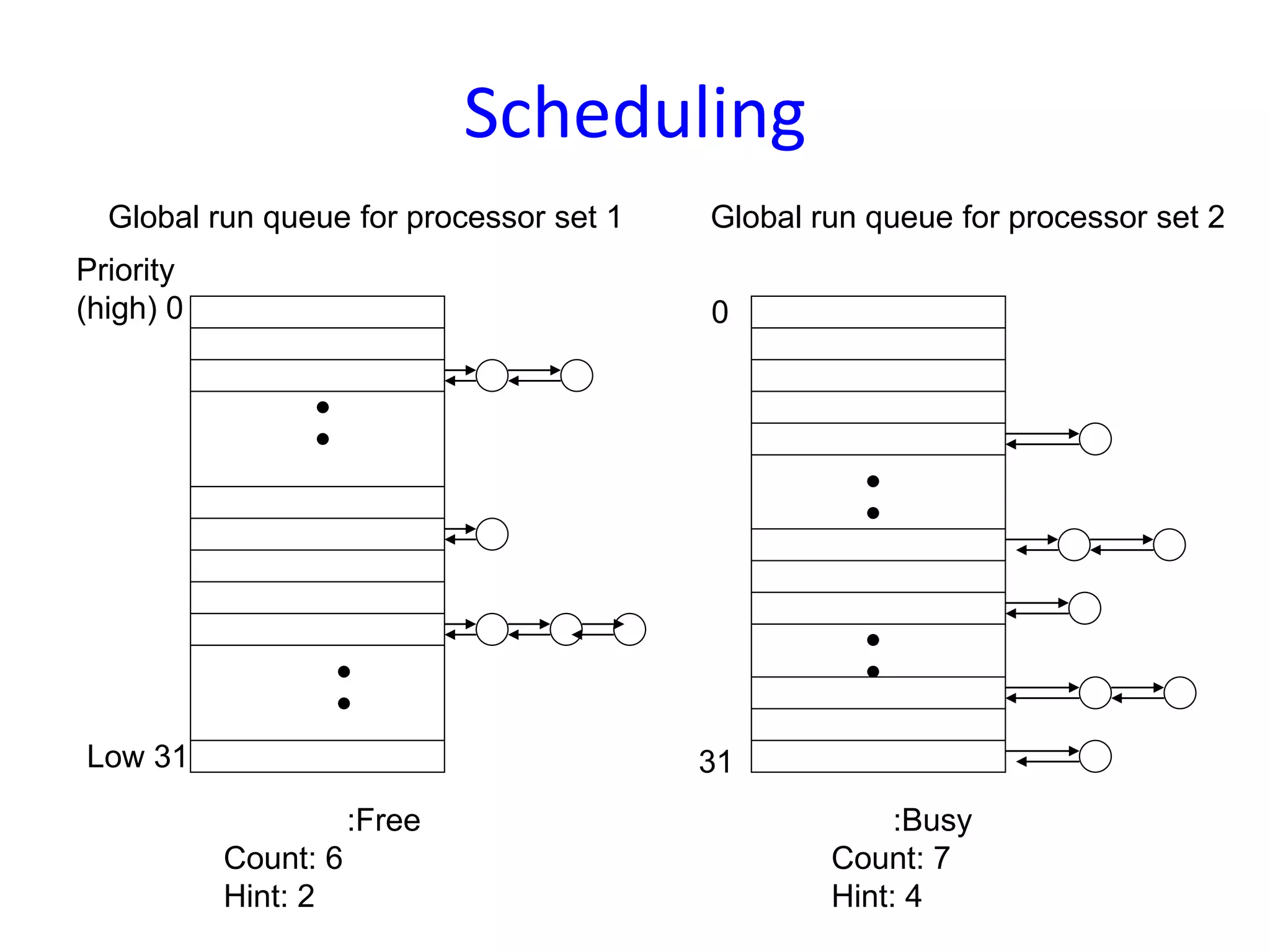
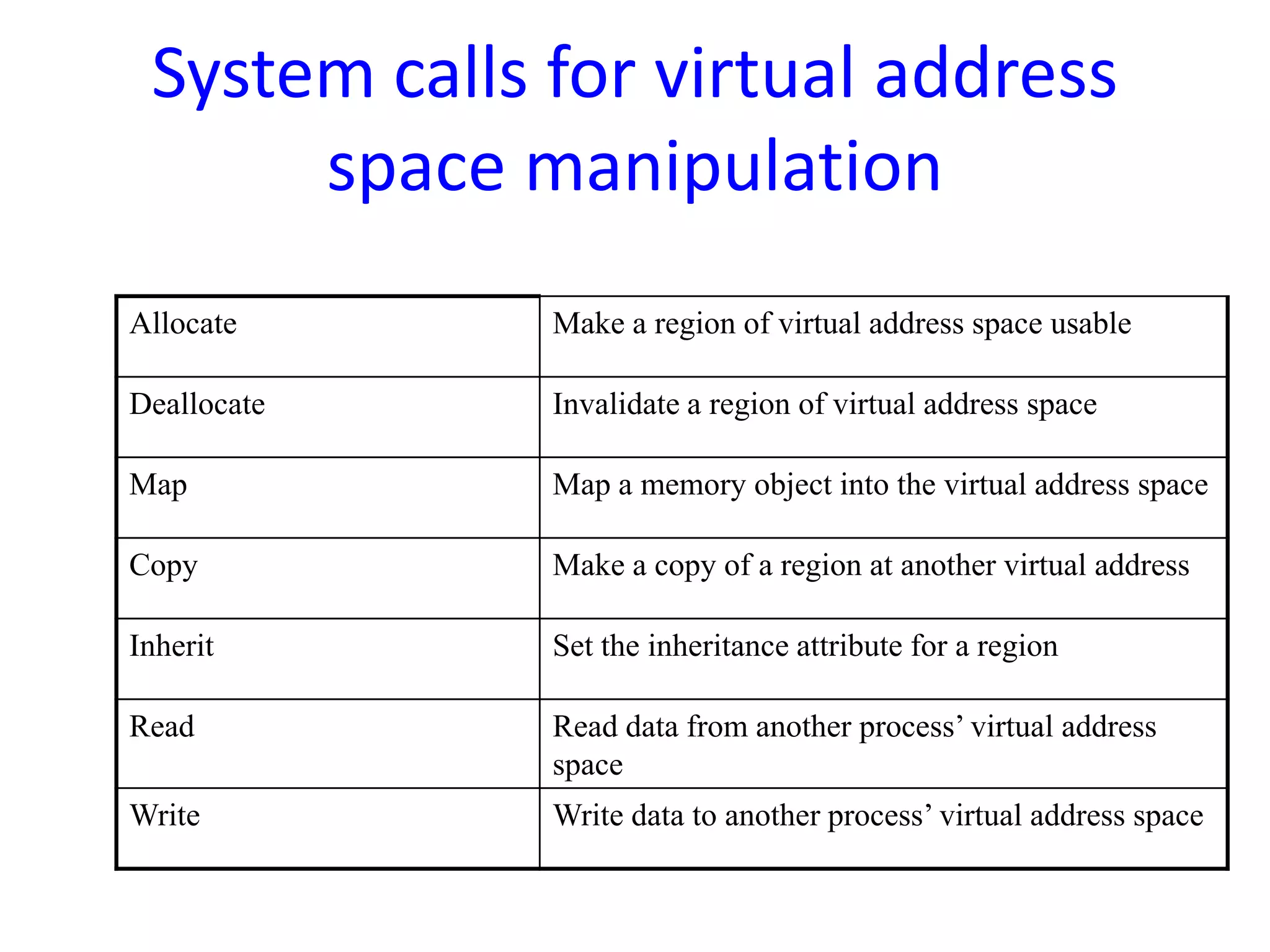
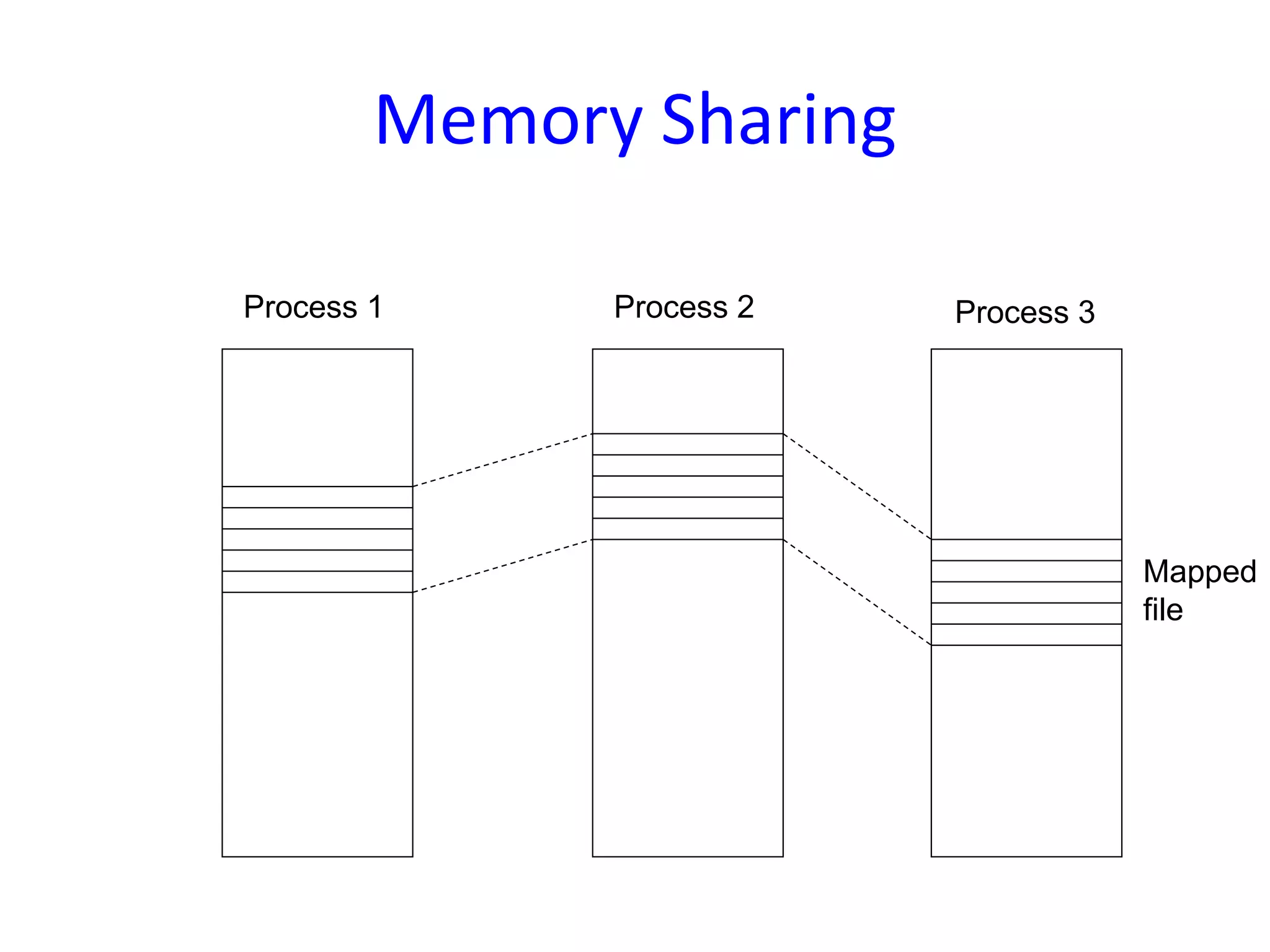
Processor scheduling issues including co-scheduling, cache corruption, context switching, and the importance of efficient scheduling in multiprocessor systems.An overview of the Mach OS focusing on memory management concepts, virtual memory, memory objects, and the flexibility of its memory management system.
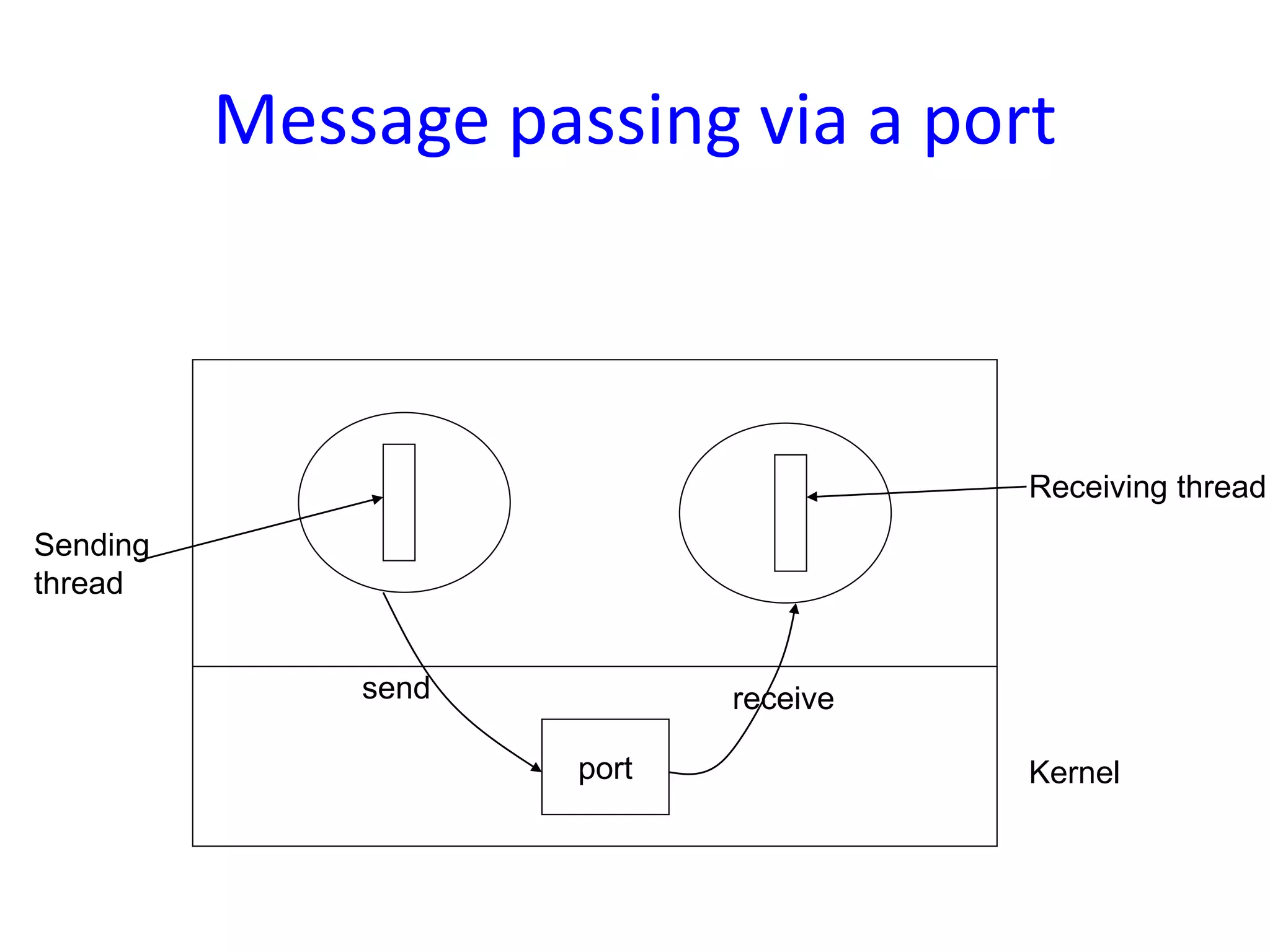
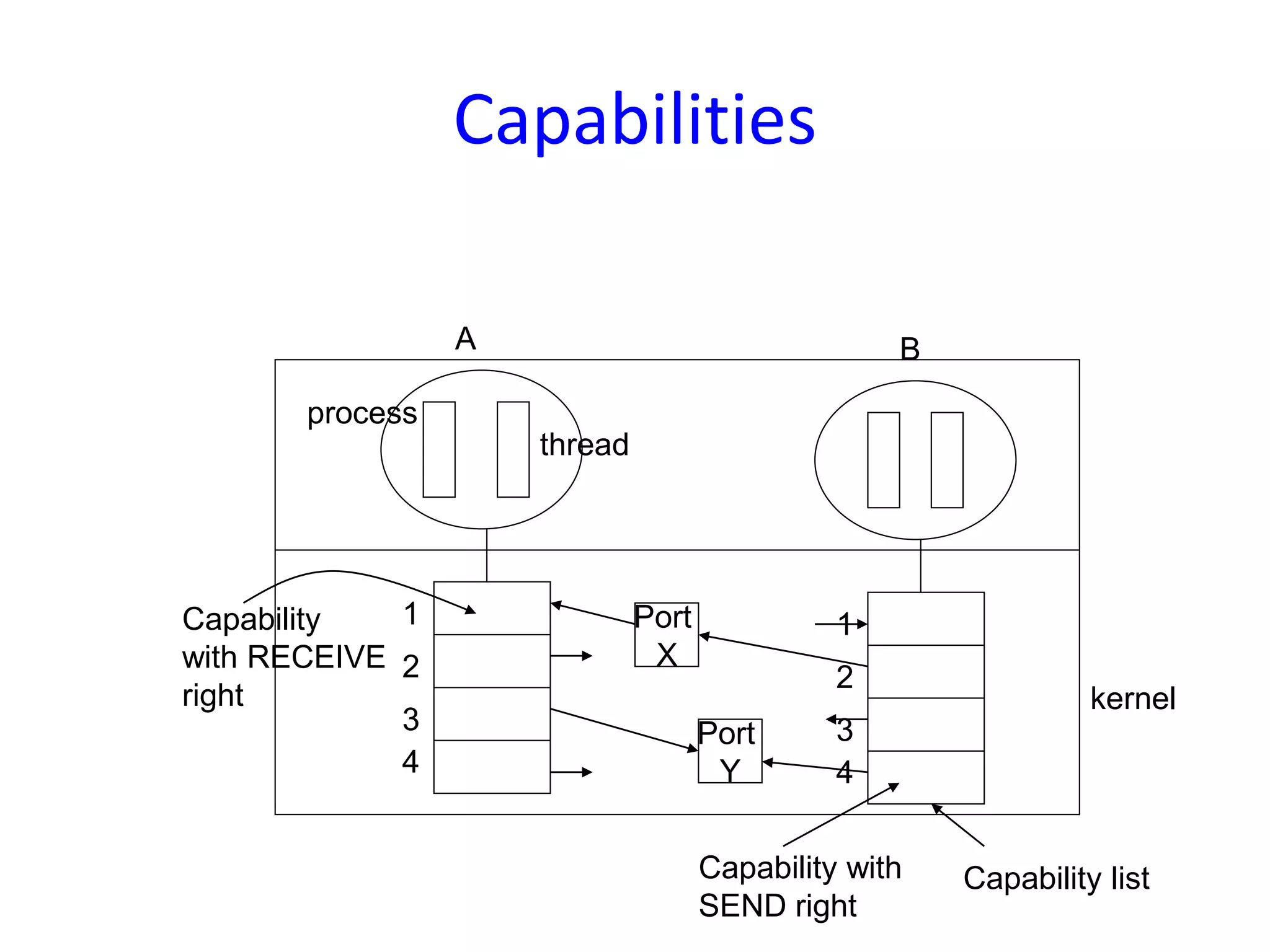
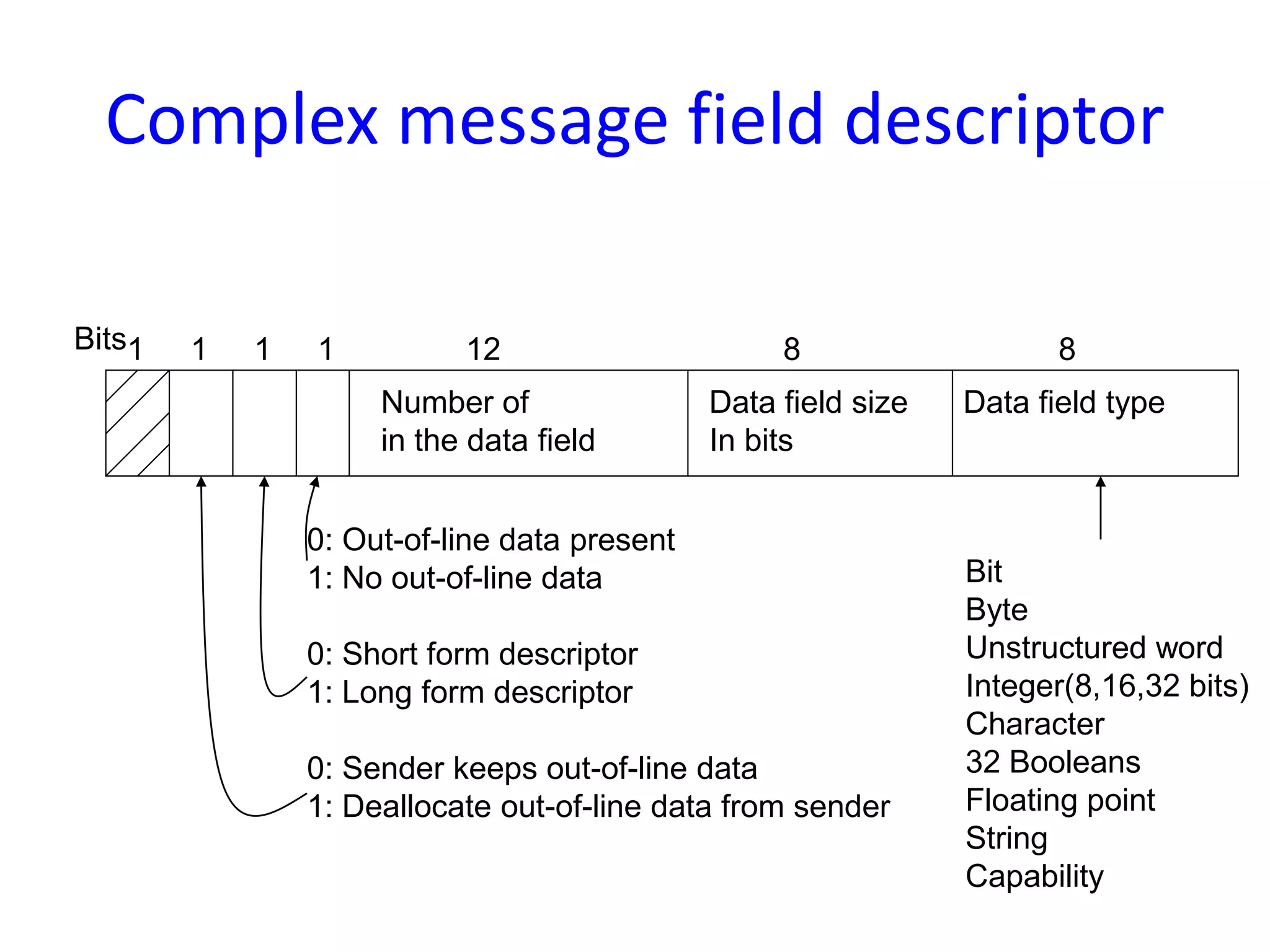
Communication in Mach OS using ports for message passing, emphasizing unidirectional communication between processes through kernel data structures.
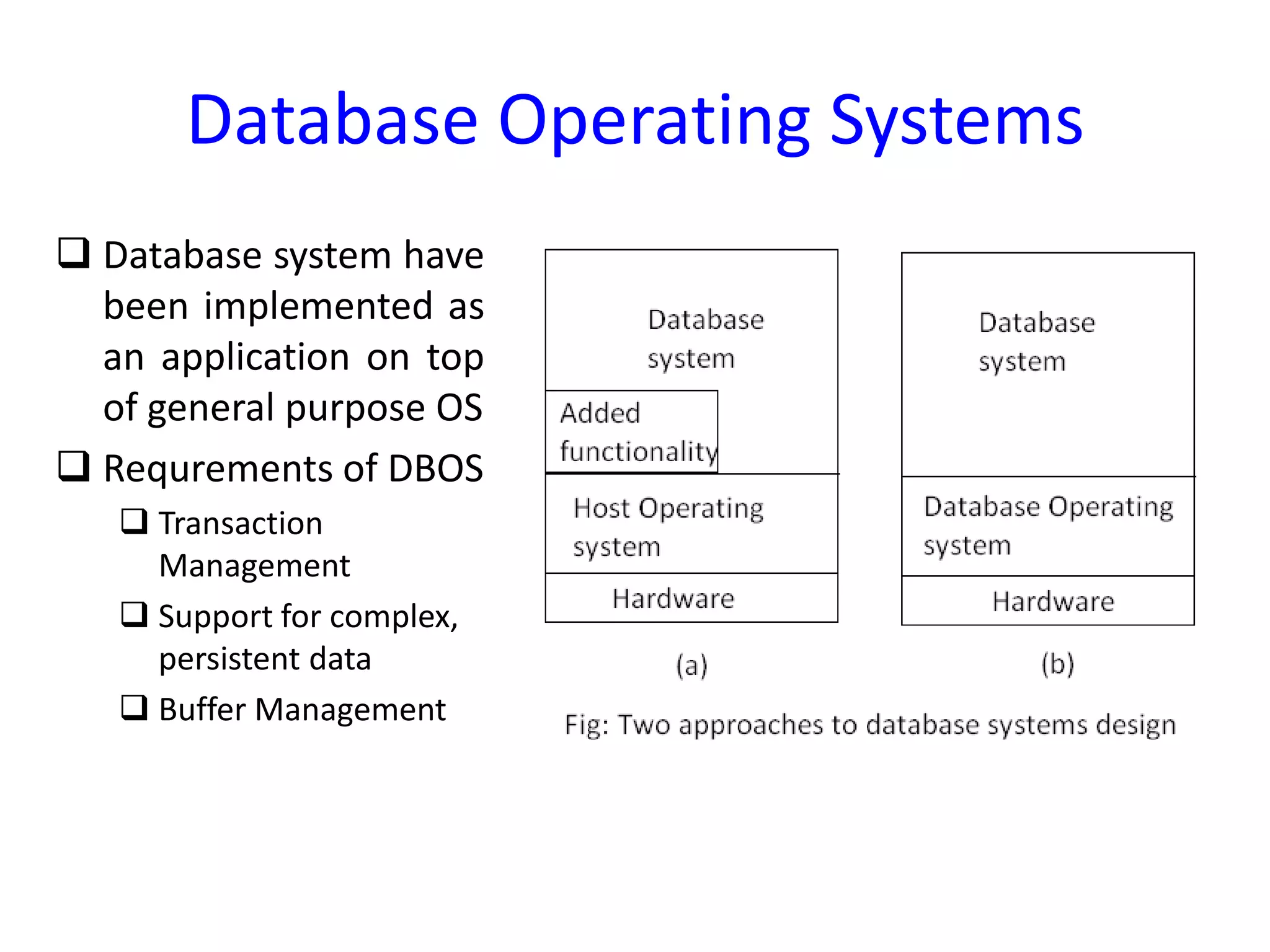
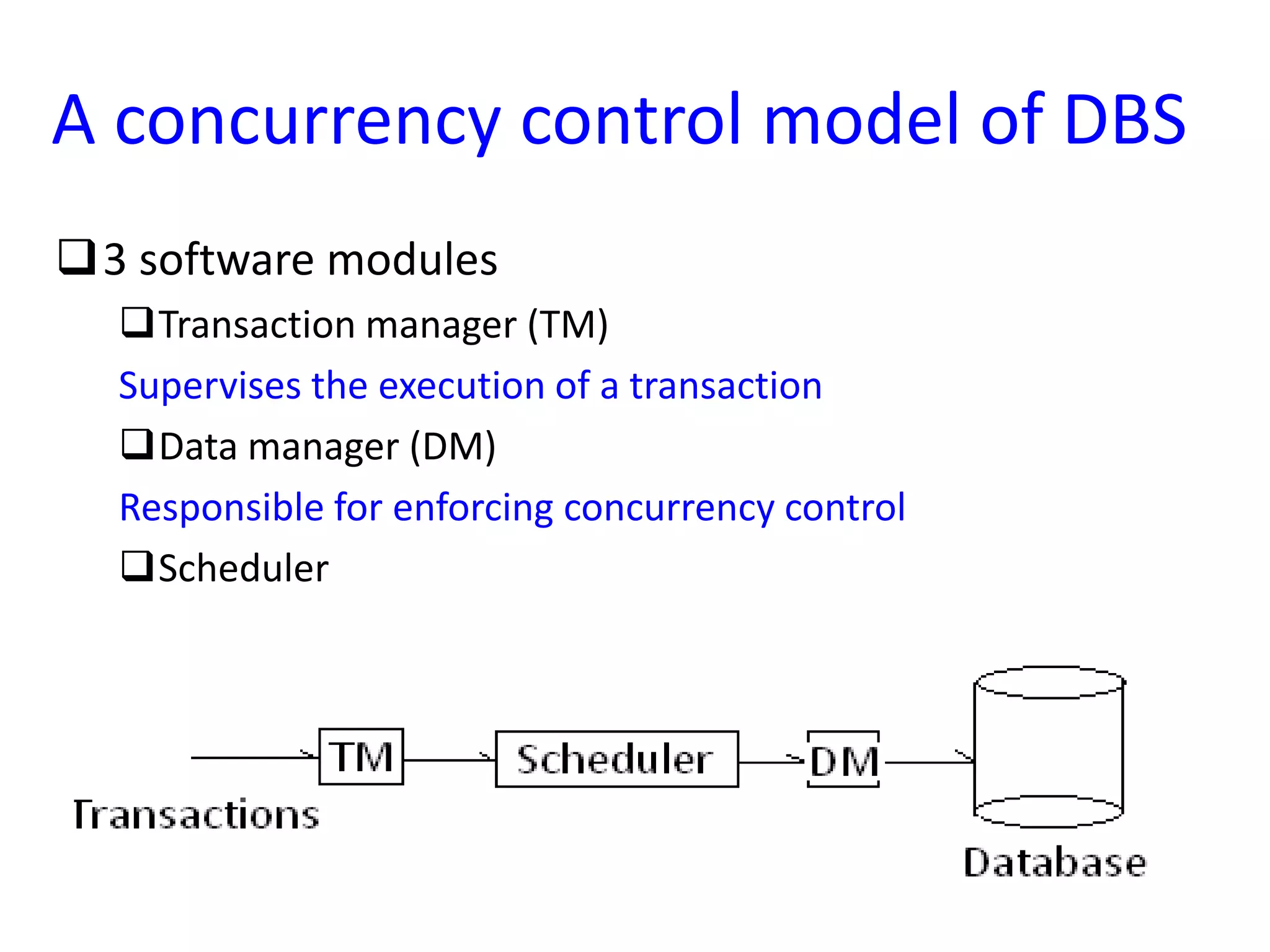
Sequoia system's approach to fault tolerance with fault detection and recovery methods, illustrating the architecture's high level of reliability.Overview of database operating systems focusing on transaction management, concurrency control, and algorithms such as lock-based and timestamp-based models.
Closing remarks and thanking the audience.





















































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)









