Download as PDF, PPTX







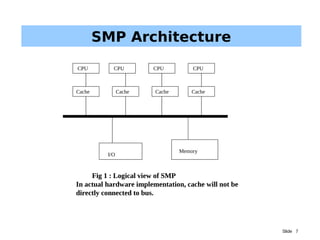


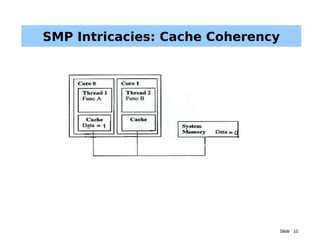


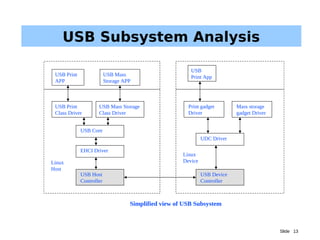












The document discusses driver parallelism in Linux, emphasizing the concepts of concurrency and parallelism, kernel pre-emption, and SMP architecture. It explores the challenges of maintaining cache coherency and atomic operations in multiprocessor systems along with the design considerations for USB subsystems. Ultimately, it highlights the importance of effective locking mechanisms to enhance performance and avoid race conditions in driver development.























































































